 精选 · 第 01 篇
精选 · 第 01 篇DeepSeek 接入 Janitor AI 全攻略:URL、密钥和模型一个都不能错
99% 的 DeepSeek 接入失败,都不是模型太难,而是 URL、API Key 和模型名没对上号。本文用通俗步骤讲清:如何在 Janitor AI 中正确配置 DeepSeek(或通过 OpenRouter 代理),如何选模型、排错,以及适合角色扮演的推荐设置。
通过实操案例和步骤讲解,让读者能够真正把 AI应用到 写作、设计、视频、编程、营销等实际工作中。内容包括: AI新手入门教程 ChatGPT使用指南 AI提示词(Prompt)技巧 AI自动化工作流 AI创作案例
精选 · 第 01 篇99% 的 DeepSeek 接入失败,都不是模型太难,而是 URL、API Key 和模型名没对上号。本文用通俗步骤讲清:如何在 Janitor AI 中正确配置 DeepSeek(或通过 OpenRouter 代理),如何选模型、排错,以及适合角色扮演的推荐设置。
99% 的人搜 DeepSeek 时,第一眼点开的链接其实都不完全安全。想用 DeepSeek 聊天、开发 API、下官方 App,却总担心点错网站?这篇把 DeepSeek 官网、聊天、平台、定价、状态和独立指南一口气讲清楚,帮你避开假网站和钓鱼页面。
 精选 · 第 03 篇
精选 · 第 03 篇DeepSeek 聊天免费,但并不是“全场通吃”的免费:网页和手机端日常对话零费用,API 按 Token 计费,本地部署虽然模型可免费获取,却要自己掏硬件和运维的钱。搞清楚这三种用法,才能避免踩坑。
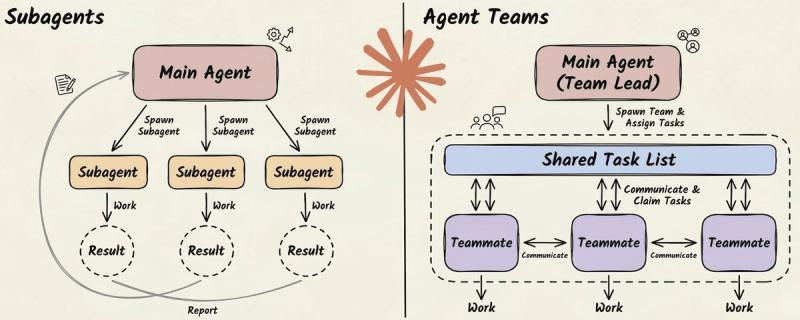
多代理不是越多越好,关键在于你到底需要“隔离并行”还是“持续协同”。这篇用直观模型和实战经验,帮你判断什么时候用子代理、什么时候上代理团队,什么时候干脆一个代理就够。

在同一块H100上,Llama 70B预填充阶段GPU利用率能到92%,解码却只剩28%。硬件没变,钱却在悄悄流失。本文从9个层面拆解72种优化技术,帮你把「研究用大模型」变成「能赚钱的大模型」。
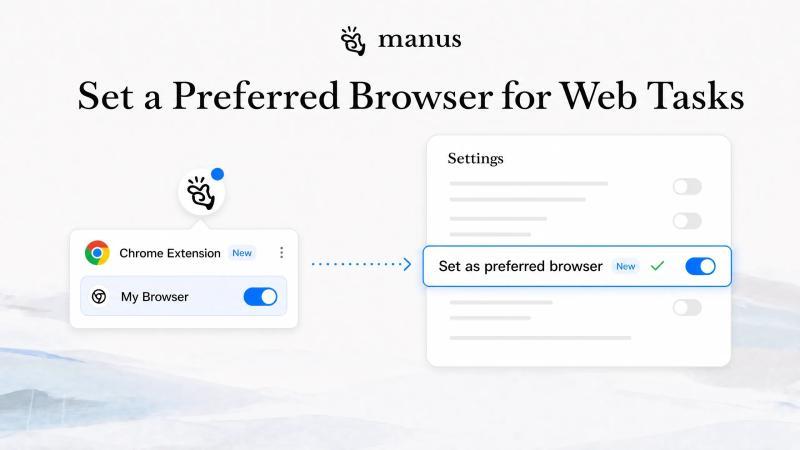
Browser Operator 现在支持设置首选浏览器,你可以把一台已经登录好账号、装好扩展、打通内网的 Chrome 浏览器接入 Manus,让所有网页任务都在这台“专用浏览器”里自动完成。

DeepSeek 不是来抢你键盘的,而是帮你从想法到大纲、初稿、修改和定稿一路提速。用对方法,它能显著提升博客、邮件、产品文案、SEO 文章、学术笔记和创作草稿的效率,但前提是:你给清晰指令,并保留最终判断权。
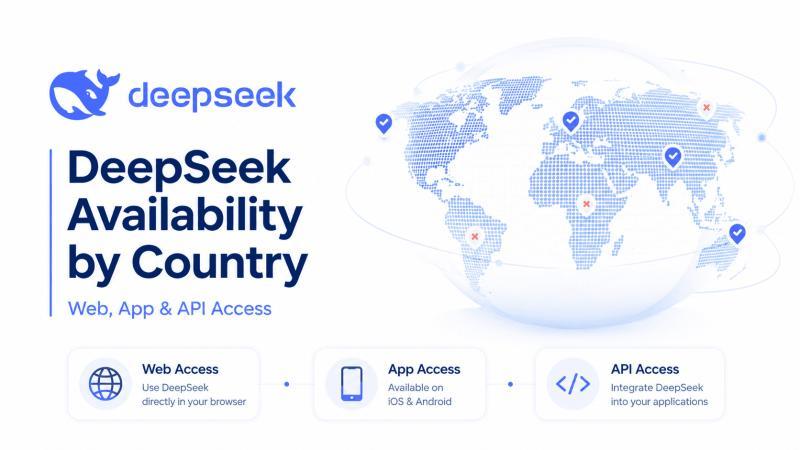
DeepSeek 在不同国家的可用性,并不是简单的「能用 / 不能用」。本文基于 2026 年 5 月 9 日前公开信息,梳理各国在网页、App、API 以及政府和职场场景下对 DeepSeek 的开放与限制,并给出自查可用性的实用步骤。
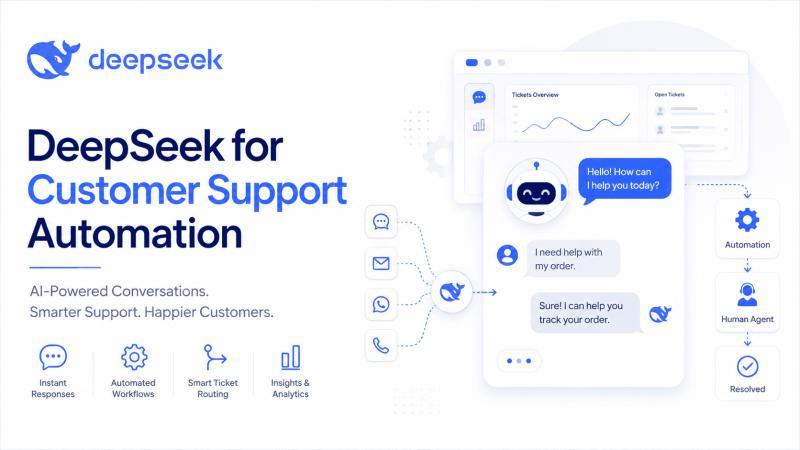
DeepSeek 客服自动化不是简单换个聊天机器人,而是把 DeepSeek 模型嵌入工单、知识库和 CRM 流程中,让 AI 负责高频、低风险的重复工作,人类专注复杂、高价值对话。本文用结构化步骤、示例提示词和风险清单,帮你搭建一套可控、可量化的 DeepSeek 客服自动化方案。
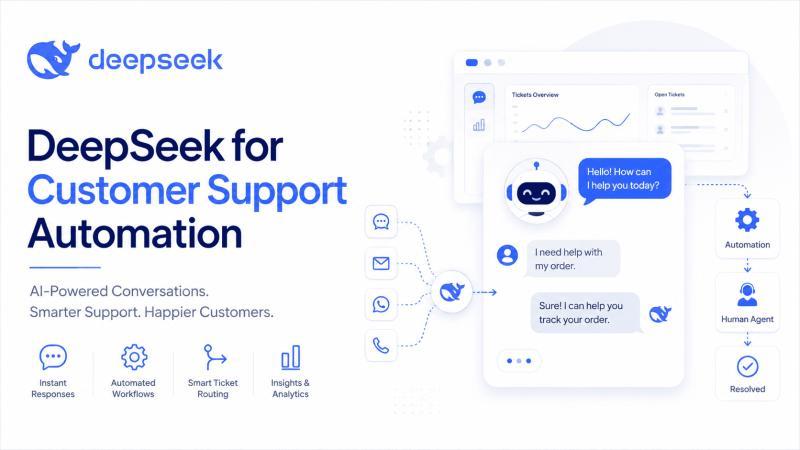
用 DeepSeek 做客服自动化,不是多放一个聊天机器人,而是把它嵌进工单、知识库、CRM 和人工流程里,让 AI 先干重复活、人类专注解决真正棘手的问题。本文从架构、API 特性、实施步骤、成本测算到风控与隐私,给出一套可直接落地的 DeepSeek 客服自动化方案。
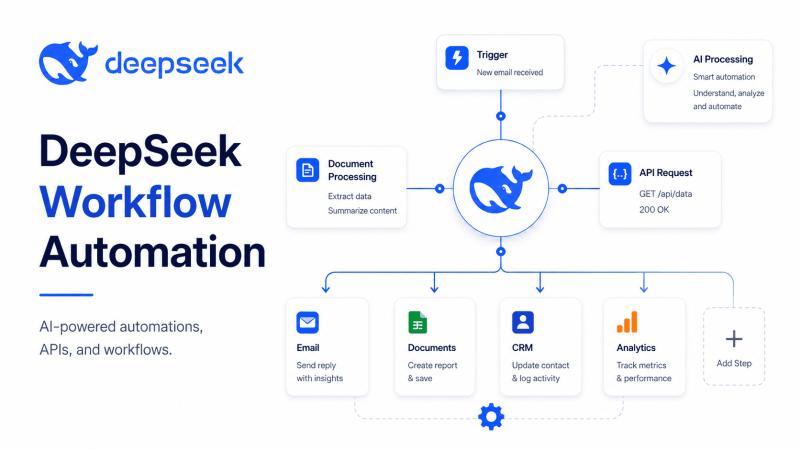
DeepSeek 不只是一个聊天模型,而是一层可以嵌入业务流程的「AI 工作引擎」。通过触发器、API、数据库、CRM、工单系统和消息工具的组合,你可以让 DeepSeek 负责理解、推理和结构化输出,让重复工作自动往前走,而不是停在人工手里。本文用实战视角拆解 DeepSeek 在自动化栈中的位置、关键能力、无代码接入方式,以及安全与合规风险。
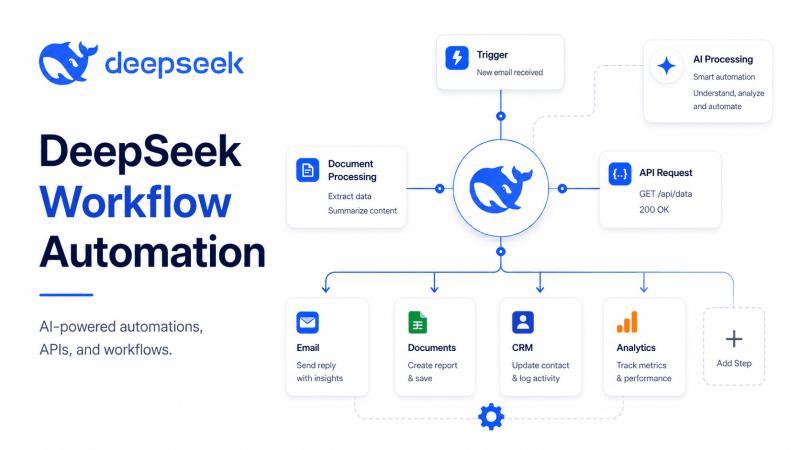
DeepSeek 不只是一个聊天模型,而是可以嵌入触发器、API、数据库、CRM、工单系统和消息工具里的“工作流大脑”。这篇实战指南讲清楚:如何选模型、如何用 n8n / Make / Zapier / Workato / BuildShip 搭建自动化流程,如何通过 JSON 输出、工具调用和后端代理,让 DeepSeek 在真实业务环境里既省钱又可靠。
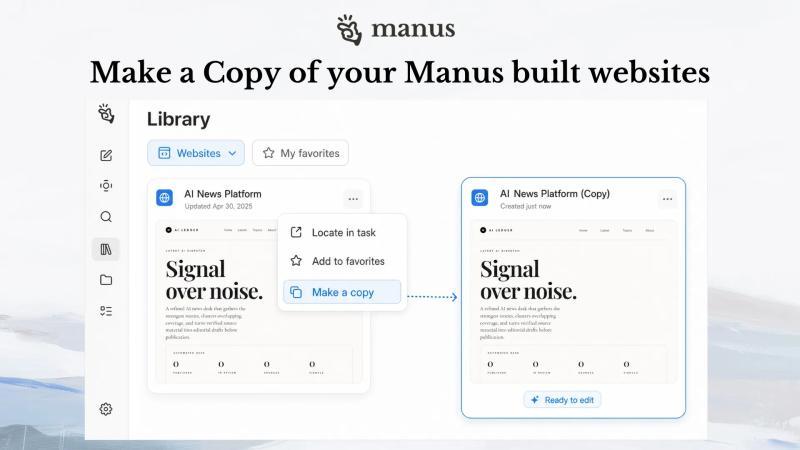
想大改首页、重做支付流程、为新市场做一个版本,却又怕动到线上站?用 Manus Website Builder 的「Make a Copy」功能,把现有项目一键复制到全新会话里,在不影响原站的前提下大胆试错、反复测试、当模板复用。
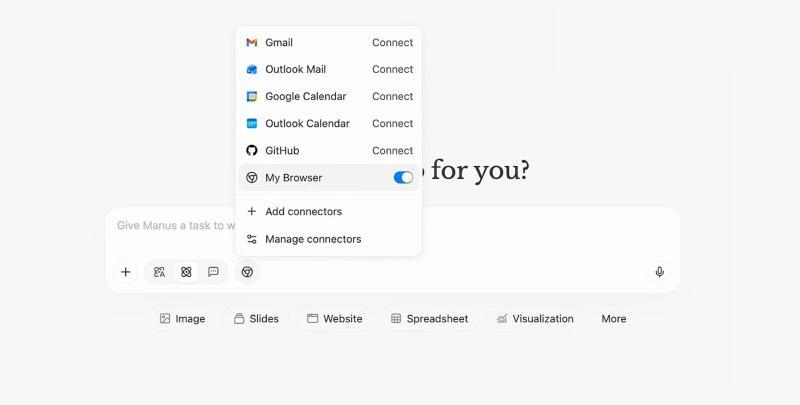
大多数人让 AI 做调研,只拿到几页公开网页的礼貌总结。真正影响决策的关键信息,其实藏在你已经登录的系统、订阅内容和内部工具里。本文用具体场景和操作步骤,讲清楚 Manus 浏览器操作符如何在你本地浏览器里工作,帮你跨设备自动化复杂网页流程,同时又不牺牲安全与可控。
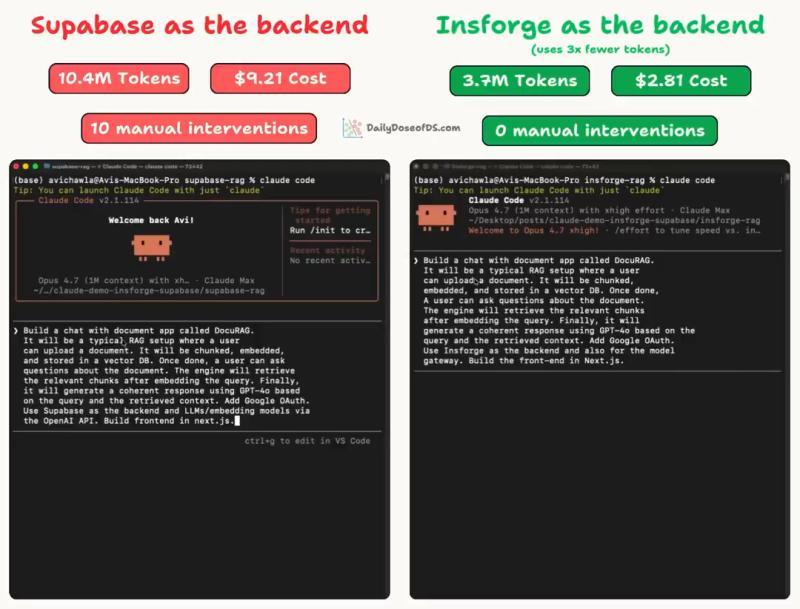
同样是用 Claude Code 搭建 DocuRAG,换一套“后端上下文工程”思路,令牌从 1040 万直接降到 370 万,成本差了 3 倍不止。关键不在模型,而在你怎么把后端状态、文档和错误暴露给代理。

一文吃透 DeepSeek 微调:何时该微调、如何选模型、LoRA/QLoRA 实战流程、数据集规范、评估与安全部署,全程以 DeepSeek-R1 Distill 为主线。

很多人一提“DeepSeek Docker 部署”就只想到拉个镜像跑模型,其实这只是五种方案里的一个。本文用实战结构和配置示例,带你从最简单的“容器化应用 + 托管 DeepSeek API”,一路走到 vLLM / SGLang 自建 GPU 推理集群,并对成本、安全和性能做清晰取舍。

想在 GitHub Copilot Chat 里直接用 DeepSeek V4 Pro 和 Flash,而不是再开一个新窗口?这篇一步步教你在 VS Code 中安装 DeepSeek V4 for Copilot Chat、配置 API Key、选择合适的模型和思考强度,并讲清费用、隐私、常见报错和避坑要点。

DeepSeek 不只是一个“便宜好用的聊天机器人”,企业如果想把它用在客服、研发、运营和自动化上,需要从数据分级、安全策略、人审机制和合规风险一起规划。这篇指南用具体步骤、案例和风控清单,帮你搭建一套可落地、可扩展的 DeepSeek 商业使用方案。