
你以为把模型丢到H100上就算「上生产」了,其实那只是烧钱的开始。很多团队上线后才发现:同一块卡,预填充阶段GPU利用率能跑到92%,一到解码就掉到28%,像是突然换了台机器。硬件没动,工作负载却完全变了形,成本曲线也跟着失控。
在一次对 Llama 70B 的实测中,预填充阶段几乎把张量核心压榨到极限,而解码阶段因为每步都要从 HBM 读完整 KV 缓存,被内存带宽死死卡住。预填充是高并行算力问题,解码更像是「搬砖」问题,两者的瓶颈完全不同。
有用户反馈:同样一批卡,换了优化方案后,每月云账单直接从六位数掉到五位数,模型本身几乎没改,只是把服务栈重构了一遍。
这也是为什么数据显示,大模型推理成本这两年几乎每年能砍掉一个数量级——GPT-4 级别模型从每百万 token 20 美元降到 0.40 美元,主要不是靠「更聪明的模型」,而是靠「更聪明的工程」。
我们整理出一张可视化图,把生产环境里常用的 72 种优化技术按瓶颈拆开:预填充计算、解码内存带宽、模型外围成本三大类。把这些手段叠加起来,才能把一个朴素 FP16 部署,拉近到 vLLM、TensorRT-LLM 那种 5–8 倍的成本效率区间。

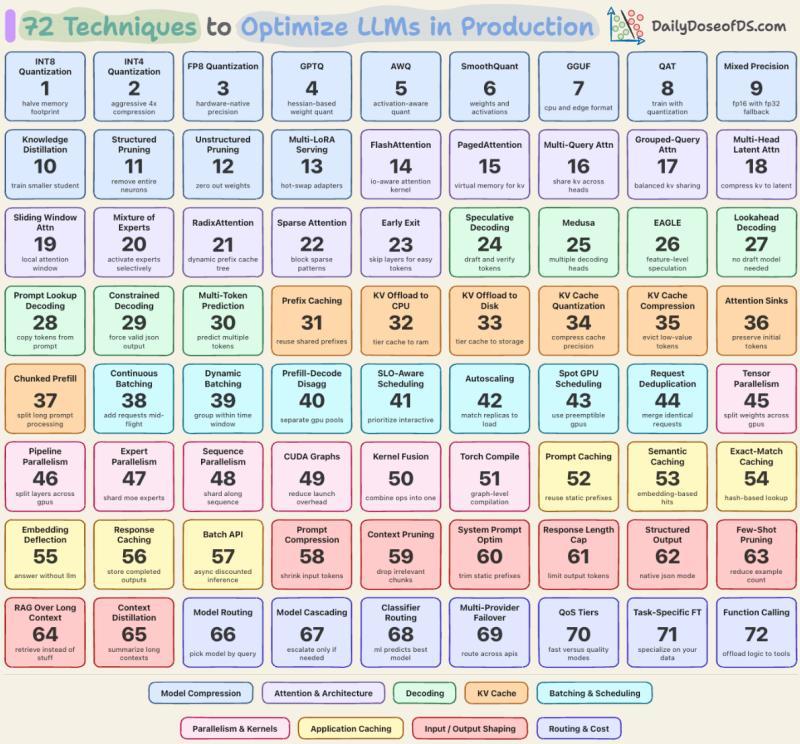
图里的每一类技术,都在对准一个核心问题:要么让预填充更便宜,要么让解码不再被内存拖死,要么把「非模型本身」的开销压到最低。很多团队一开始只盯着模型本体做量化或蒸馏,效果有限,就是忽略了这种结构性不对称。
接下来,我们按九个层面往下拆:每一层解决什么问题,适合什么场景,真实生产里大概能省下多少。
更细的实现细节和工程权衡,我们在 LLMOps 系列课程里做了系统展开,有兴趣可以从这里接着看:
一、模型压缩:从「装得下」到「跑得快」
1.1 精度压缩:INT8、INT4、FP8 怎么选

一个 70B 的 FP16 模型,在你还没喂任何上下文之前,就已经吃掉了 140GB 显存。很多团队一上来就被「装不下」卡住,后面所有优化都无从谈起。压缩做得好,不只是能装下,还能让带宽和算力都更高效。
常见的几种精度选择:
- INT8:相对 FP16 显存减半,精度损失可控,工程上最稳妥
- INT4:显存缩小 4 倍,适合对质量容忍度更高的场景
- FP8:在 Hopper、Blackwell 上有原生张量核心支持,既省内存又提吞吐
据公开基准测试,很多 70B 级模型在 INT8 下几乎不掉分,在 INT4 下会有一定退化,但对聊天、摘要类任务仍然可用。真正的难点不在「能不能量化」,而在「量化后还能不能稳定服务」。
1.2 算法与多租户:GPTQ、AWQ、SmoothQuant 与多 LoRA
主流压缩算法各有侧重:
- GPTQ:利用 Hessian 二阶信息,尽量在「最不敏感」的方向上量化
- AWQ:按激活幅度保留关键权重,对高激活通道更友好
- SmoothQuant:同时平滑权重和激活,常用 W8A8 格式,部署友好
在参数层面,蒸馏和剪枝是另一条路:不是减少每个参数的位数,而是直接减少参数数量。比如把 70B 蒸馏到 7B,在特定任务上做到 90% 以上性能,却只用十分之一的资源。
多租户场景里,多 LoRA 服务是个很实用的工程技巧:

- 只让一个基础模型常驻显存
- 每个租户只加载几百 MB 的 LoRA 适配器
- 请求到来时「热插拔」对应 LoRA 权重
我自己在一个 B2B 场景里试过,多 LoRA 让我们在同一组 GPU 上同时服务 20+ 企业版本,而显存占用只比单租户多了不到 30%。说实话,这种「一机多号」的感觉非常爽。
想系统看压缩和多租户部署,可以翻 MLOps 课程第 9、10 部分,以及 LLMOps 第 12 部分,里面有更细的工程实践。
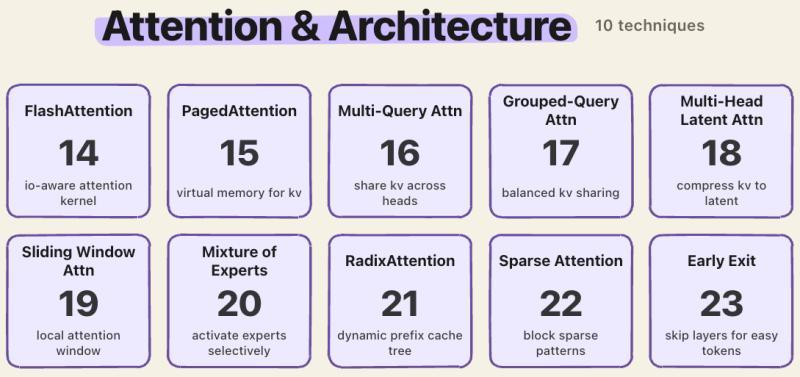
二、注意力与架构:从 O(N²) 逃出去
2.1 FlashAttention、PagedAttention 与长上下文
标准自注意力的复杂度是 O(N²)。当上下文拉到 128K 时,单次前向就要算 160 亿次注意力,这对 H100 来说都很吃力,更别说多租户并发。很多人以为「长上下文=多给点钱」,其实在普通注意力下,硬怼几乎是不可行的。
FlashAttention 的关键不是「算得更少」,而是「算得更聪明」:
- 重排计算顺序,避免显式构建 N×N 注意力矩阵
- 让数据在 SRAM 和 HBM 之间来回搬运次数最少
- IO 成本大幅下降,长上下文才真正跑得动
PagedAttention 则借鉴操作系统的虚拟内存:
- 把 KV 缓存切成小页
- 动态复用空闲页,消除碎片
- 长对话场景下,显存利用率明显提升
2.2 MQA/GQA/MLA、滑动窗口与 MoE
在 KV 头数量上做文章,是另一条大幅省内存的路:
- MQA:所有查询共享一个 KV 头,极致压缩
- GQA:把头分组,每组共享 KV,兼顾质量和效率
- MLA:把键值压缩到低秩潜空间,DeepSeek-V2 报告仅 MLA 就减少了 93.3% 的 KV 缓存
滑动窗口注意力则直接限制「每个 token 只看附近一小段」,对很多对话、代码补全任务来说,远处上下文本来也没那么重要。MoE 架构则通过「只激活少数专家」来减少每次前向的有效参数量。
有研究团队在内部评估时发现:在新闻摘要任务上,把全局注意力换成滑动窗口,成本下降近一半,ROUGE 分数只掉了 1–2 个点。你要说这是不是划算,我也不太确定,但业务侧一般会说:能上线。
相关的原理和工程权衡,可以参考 LLMOps 第 3、13 部分的长上下文与注意力专题。
三、解码:被内存带宽卡住的那一段
3.1 推测解码、Medusa、EAGLE:让模型「先写草稿」

解码阶段的痛点在于:每生成一个新 token,都要完整扫一遍权重和 KV 缓存,内存带宽成了绝对瓶颈。想要提速,就得想办法「一次多走几步」。

常见的几种做法:
- 推测解码:用一个小模型先生成一串草稿,再让大模型并行验证
- Medusa:在大模型上挂多个预测头,让它自己一次预测多个候选 token
- EAGLE:把预测搬到隐藏状态层面,草稿更准,回滚更少
- 预见解码:直接由主模型并行生成和验证多个 token,不再依赖小模型
据公开实验,推测解码在不少场景下能带来 1.5–2.5 倍的解码加速,且质量几乎不变。代价是工程复杂度明显上升,监控和回滚逻辑都要重写。
3.2 提示查找、约束解码与多 token 预测
还有几类更偏任务形态的技巧:
- 提示查找解码:当输出和输入高度重叠(摘要、代码编辑),直接复制输入片段,而不是逐 token 生成
- 约束解码:在 token 级别强制语法规则,比如必须输出合法 JSON、SQL
- 多 token 预测:训练时就让模型一次输出多个 token,推理时自然可以「多走几步」
我在一个「生成结构化配置」的项目里试过约束解码,最直观的感受是:解析错误几乎消失了,后端异常告警直接清净了很多。不过风险也很现实——约束写得太死,模型有时会「卡」在某些状态,调试体验并不轻松。
更多解码相关的细节,可以翻 LLMOps 第 4、13 部分。
四、KV 缓存:长对话真正吃掉的是谁
4.1 KV 大小、前缀缓存与卸载


KV 缓存大小随上下文长度线性增长,一旦对话拉长,它往往比模型权重更占显存。以 70B 模型为例,4K 上下文每个请求就要吃掉数 GB 的 KV 缓存,多并发时很容易把卡撑爆。
几种常用手段:
- 前缀缓存:复用共享前缀的 KV,比如系统提示、少量示例,一次预填充,多次复用
- KV 卸载:把冷 KV 挪到 CPU 内存或 NVMe 上,显存只留热数据
- KV 量化:单独对 KV 做 INT8/INT4 压缩,不动权重
有团队报告,在多轮对话场景里,仅靠前缀缓存就能让系统提示和 few-shot 示例的边际成本接近 0,长会话的显存压力明显缓解。
4.2 Token 驱逐、Attention Sinks 与分块预填充
更激进的做法是「扔掉一部分 KV」:
- H2O、SnapKV:根据注意力分布丢弃低关注 token
- SnapKV 在 1024 token 预算下实现了 92% 的 KV 压缩和 3.6 倍解码加速
为了防止长上下文被截断后语义崩坏,StreamingLLM 提出了 Attention Sinks:
- 永久保留前几个特殊 token
- 即便后面窗口滑动,这些「锚点」也不会被驱逐
分块预填充则是一个很实用的工程技巧:

- 把超长提示拆成多个块
- 一边预填充后半段,一边开始对前半段解码
- 让 GPU 不再在预填充和解码之间「一会儿忙死,一会儿闲着」
KV 相关的可视化解释,可以看这篇:
https://www.dailydoseofds.com/p/kv-caching-in-llms-explained-visually/
五、批处理与调度:把「闲着的 GPU」用起来
5.1 连续批处理、动态批处理与预填充-解码分离

解码阶段 GPU 经常是「算一点,等一会儿」,内存带宽在忙,算力却在闲。批处理的本质,就是用更多请求来摊薄这部分内存读取成本。
常见几种方式:
- 连续批处理:在解码循环层面做,某个请求结束,立刻让新请求接上
- 动态批处理:等待一个很短的时间窗口,把多条请求合成一个大 batch
- 预填充-解码分离:把预填充和解码放到不同 GPU 池,避免新来的长提示把正在解码的请求「冻住」
有公开数据表明,32 请求的动态批处理可以把每 token 成本压低约 85%,而 P95 延迟只略有上升。Perplexity、Meta、Mistral 等在生产里都采用了预填充-解码分离的架构。

5.2 SLO 调度、Spot GPU 与请求去重
在更高一层,调度器可以做的事还有很多:
- SLO 感知调度:优先处理交互式流量,把批量任务往后排
- Spot GPU 调度:把可中断任务丢到便宜的抢占式实例上
- 请求去重:对完全相同的查询做合并,只算一次,结果多播
我见过一个实际案例:某团队在高峰期把 FAQ 类请求统一做去重和批处理,结果是高峰期 GPU 利用率从 40% 拉到 80% 以上,用户侧几乎感知不到变化。这种「不改模型,只改排队方式」的优化,往往是最容易被忽略的。
更多调度细节可以看 LLMOps 第 13、14 部分,以及 MLOps 第 15 部分。
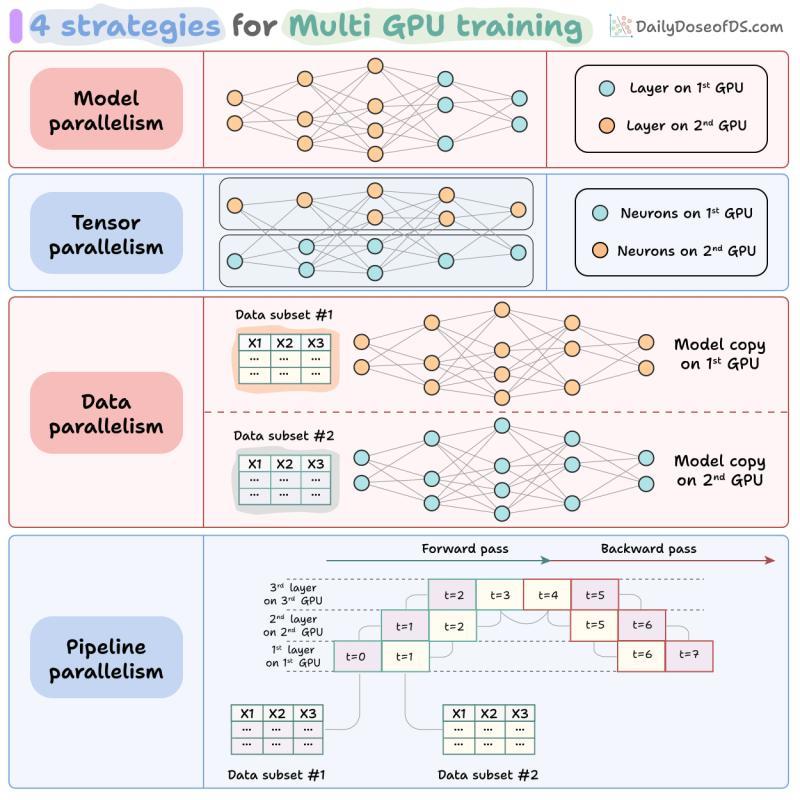
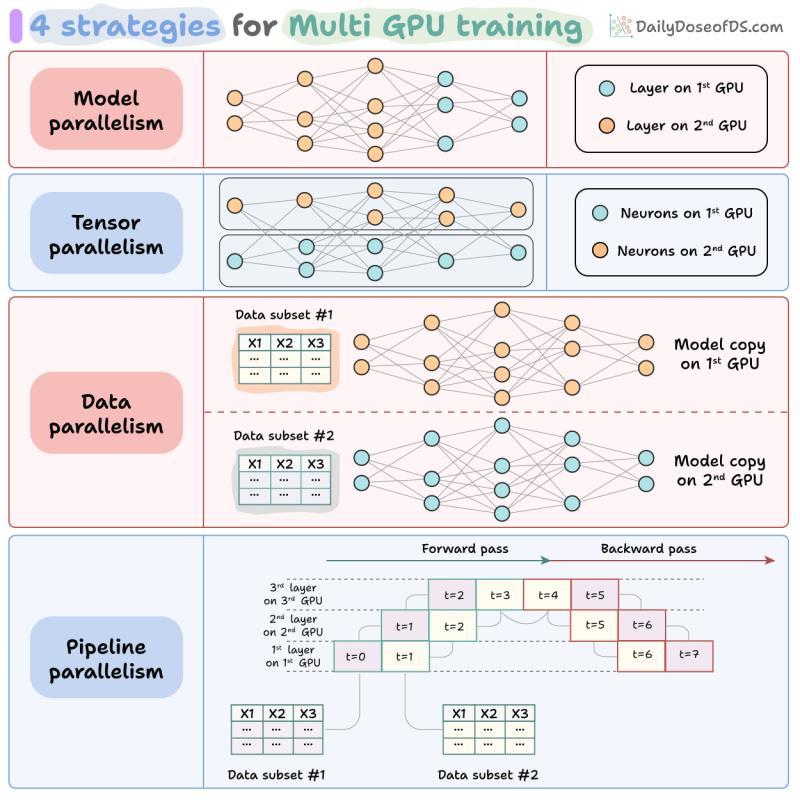
六、并行与内核:把一块卡当多块用
6.1 张量并行、流水线并行、专家并行、序列并行

大模型上不了单卡,就得拆着跑:
- 张量并行:把大矩阵按列或行切到多块 GPU 上
- 流水线并行:按层切分,每块 GPU 负责一段网络
- 专家并行:MoE 模型里,不同专家分布在不同设备上
- 序列并行:沿 token 维度拆分,让长序列也能分布式处理
这些并行策略的组合,决定了你能不能在有限 GPU 上跑起 100B+ 模型,也决定了跨机通信是不是会成为新的瓶颈。
6.2 CUDA 图、内核融合与 Torch Compile
在更底层,内核优化直接决定了「同样一块卡,能不能多挤出 20–30% 的吞吐」:
- CUDA 图:把一串固定的内核调用录成图,减少每次启动开销
- 内核融合:把多个小操作合成一个大内核,减少内存往返
- Torch Compile:通过图级编译自动生成融合内核,减少手写 CUDA 的工作量
解码阶段每秒可能要启动上千个小内核,如果每次启动都要付出固定开销,累计下来就是肉眼可见的浪费。有团队在引入 CUDA 图和内核融合后,单卡吞吐提升了 30% 左右,延迟也更稳定。
更多并行与内核优化的实践,可以看 LLMOps 第 13 部分。
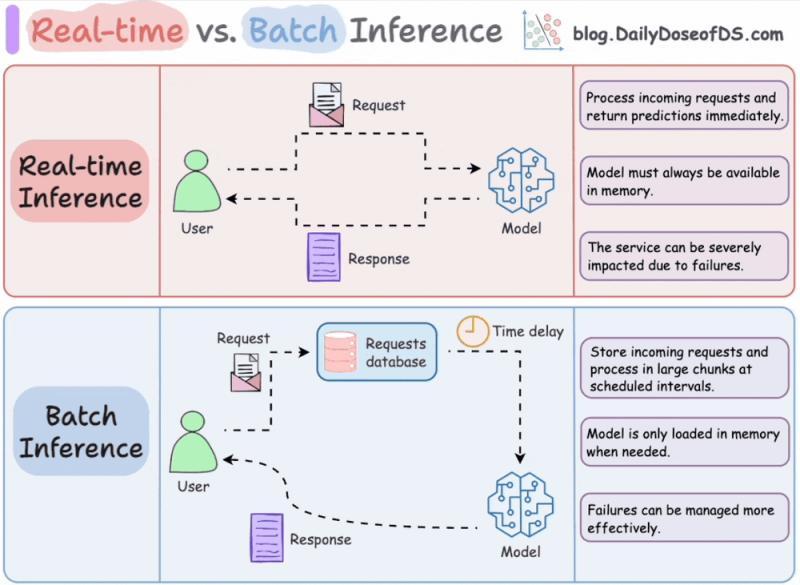
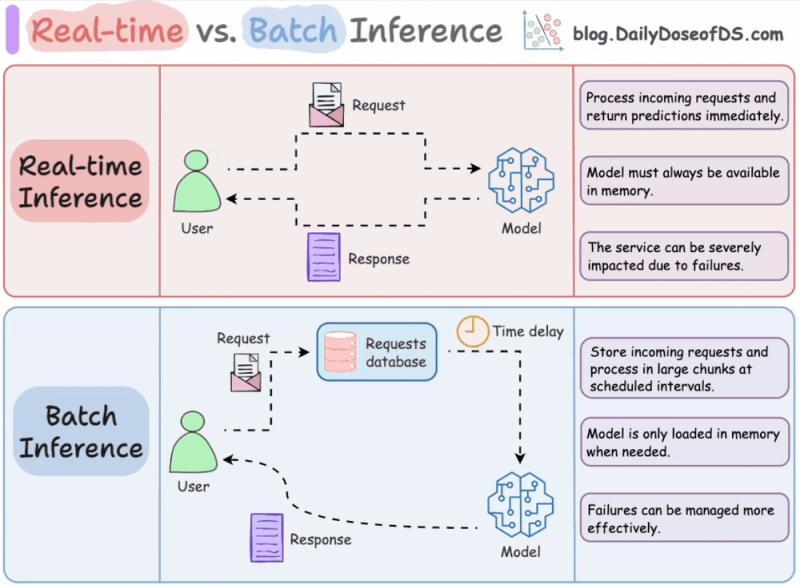
七、应用缓存:最便宜的推理是「不推理」
7.1 提示缓存、语义缓存与响应缓存

如果从业务视角看,最省钱的推理方式就是:直接命中缓存,不算新结果。很多人只在模型层面做优化,却忽略了应用层的巨大空间。

常见几种缓存:
- 提示缓存:复用静态前缀的 KV 状态
- 语义缓存:用嵌入相似度匹配「意思差不多」的查询
- 精确匹配缓存:基于哈希的严格命中
- 响应缓存:直接存储完整输出
Anthropic 报告称,在长提示场景下,提示缓存可以让成本降低 90%,延迟降低 85%。这类优化对用户是「无感的」,但对账单非常友好。
7.2 嵌入偏转与批量 API
还有两种很实用的手段:
- 嵌入偏转:把简单查询直接路由到向量搜索或规则系统,绕开 LLM
- 批量 API 端点:对非实时任务做异步批量处理,每 token 成本大约能减半
我见过一个典型案例:某知识库问答系统上线语义缓存后,热门问题的缓存命中率超过 60%,高峰期 GPU 使用量直接砍半。缺点也很现实——缓存失效策略设计不好,会出现「用户改了点小字,结果还是老答案」的尴尬场景。
更多应用层优化,可以看 LLMOps 第 13、14 部分,以及 MLOps 第 11 部分。
八、输入/输出形态:别让 token 白白流走
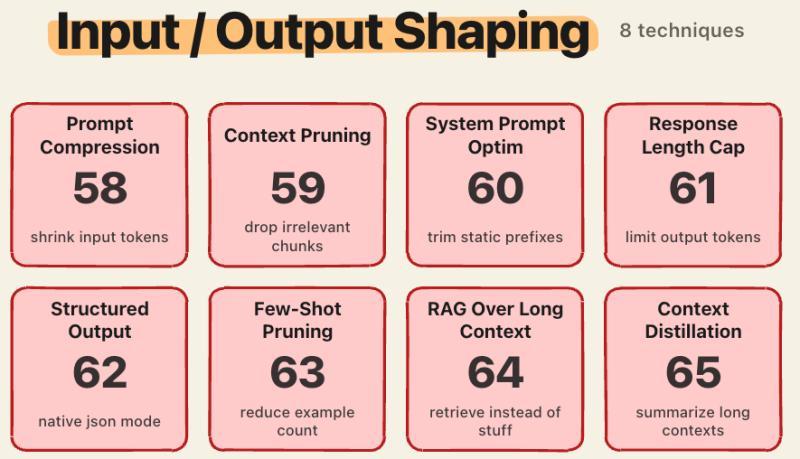
8.1 提示压缩、上下文剪枝与系统提示优化
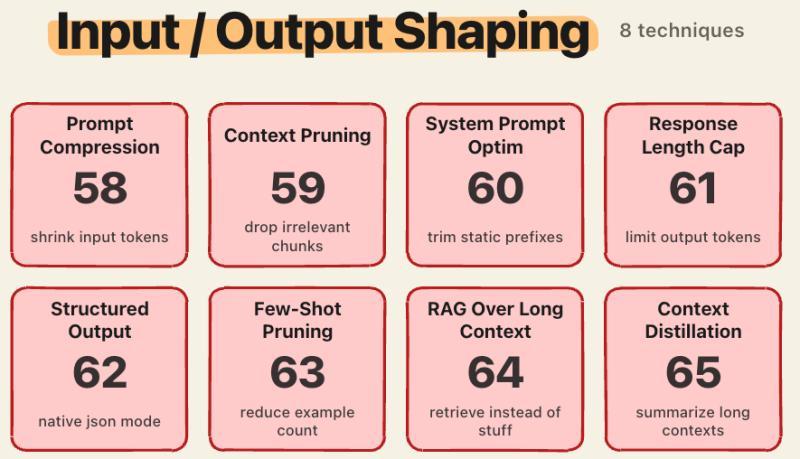
在大多数商用 API 里,输出 token 的价格是输入的 3–10 倍。以 Claude Sonnet 4 为例:输入每百万 token 3 美元,输出是 15 美元。每多说一句废话,都是实打实的成本。
几种常见做法:
- 用 LLMLingua 等工具做提示压缩,实测最高可达 20 倍压缩,质量损失很小
- 上下文剪枝:丢掉与当前问题无关的检索片段
- 系统提示优化:把冗长的「人格设定」「风格说明」精简到最小
有团队在 RAG 系统里做了一轮上下文剪枝,把平均上下文长度从 8K 压到 2K,召回质量几乎不变,预填充成本却直接降了 70% 左右。
8.2 输出控制、上下文蒸馏与长上下文 RAG
在输出端,可以做的事也不少:
- 响应长度限制:硬控最大输出长度
- 结构化输出模式:让模型只填空,不长篇大论
- 少样本剪枝:减少示例数量
- 上下文蒸馏:把长历史总结成短状态,后续对话只带状态
- 长上下文 RAG:用检索+短上下文替代「一股脑塞满窗口」
这类优化的一个隐性好处是:不仅省钱,还能让模型更聚焦。用户不必读一大段「解释性废话」,而是直接拿到结构化结果。缺点是提示工程会变复杂,调参成本上升。
更多关于提示与 RAG 的实践,可以看 LLMOps 第 5–8 部分。
九、路由与成本控制:不是所有问题都配得上 GPT-4
9.1 模型路由、级联与分类器路由

现实里,大部分查询并不需要顶级模型。把所有请求一股脑丢给最大最贵的模型,是最常见、也最昂贵的误用方式。
常见策略:
- 模型路由:根据任务类型、长度、历史表现选择不同大小的模型
- 模型级联:先跑便宜模型,置信度不够再升级到大模型
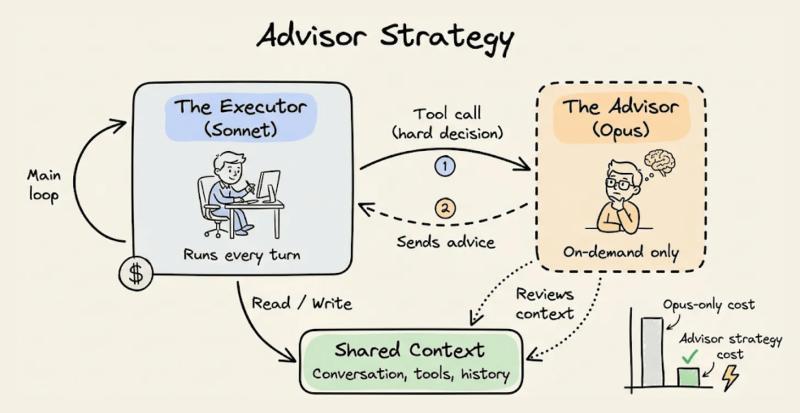
- Advisor 策略:让一个「顾问模型」决定是否需要调用更强模型
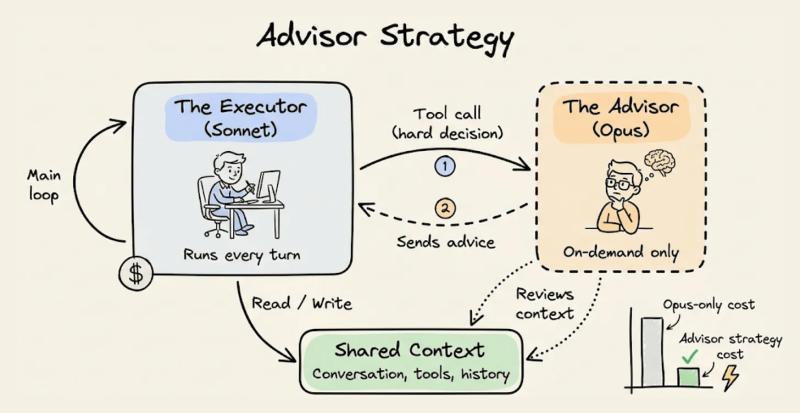
更进一步,可以训练分类器路由:

- 输入是查询内容、上下文特征
- 输出是「该用哪个模型」的决策
据一些公开案例,合理的路由策略可以让 70–80% 的请求落在 7B 级模型上,只有 20–30% 升级到 70B 或 GPT-4 级别,整体成本直接砍半以上。
9.2 多供应商、QoS 分层、任务特定微调与函数调用
在更宏观的层面,还有几种常见做法:
- 多供应商故障切换:在不同云厂商、不同 API 之间做智能选择
- QoS 分层:给不同用户或请求类型配置不同的「速度/质量」档位
- 任务特定微调:让 7B 模型在垂直领域逼近 70B 的表现
- 函数调用:把确定性逻辑交给工具,模型只负责决策和 glue code
我在一个报表生成项目里见过极端情况:原本全靠大模型「算+写」,后来把所有计算逻辑都改成函数调用,模型只负责生成 SQL 和解释,token 用量直接下降了 80% 以上,用户体验反而更好。
更多路由与成本控制的实践,可以看 LLMOps 第 12、14 部分。
综合应用:真正能赚钱的生产栈长什么样
严肃的生产环境,很少只用一两种优化技术。更常见的,是一个「组合拳」:
- 模型层:FP8 权重,GQA 注意力,配合 FlashAttention 内核
- KV 层:PagedAttention 管理 KV,必要时做 KV 量化
- 调度层:连续批处理 + 预填充-解码分离
- 应用层:系统提示前缀缓存 + 语义缓存 + 批量 API
- 提示层:长检索上下文做提示压缩和上下文剪枝
- 路由层:简单查询走小模型,复杂任务才上大模型
有团队在类似栈上做过对比:相对于「朴素 FP16 + 静态批处理」的基线,每 token 成本降低了 5–8 倍,P95 延迟也更稳定。单点优化往往只能带来 10–30% 的提升,真正改变曲线形状的,是这九个层面的复合叠加。
如果你正打算把一个「Demo 级」大模型服务推向真实业务,这套组合拳的思路值得反复翻看。很多坑,别人已经踩过一轮了,没必要再用自己的云账单去验证一遍。
更多实现细节和工程逻辑,可以从这里接着看:
https://www.dailydoseofds.com/llmops-crash-course-part-1/
常见问题
Q:只有几块 GPU 的小团队,有必要上这么复杂的优化栈吗?
A:小团队不必一口气上全套,但挑 3–5 个性价比最高的点做,回报会非常可观。一般建议优先做:模型压缩(INT8/FP8)、动态批处理、提示压缩/上下文剪枝、应用层缓存和简单的模型路由。这几项改动工程量相对可控,却能带来 2–4 倍的成本下降。判断标准是:先用监控抓出你最大的瓶颈(显存、带宽还是延迟),再对症下药,而不是盲目堆技术名词。实在资源有限,就从「不改模型,只改服务栈」的优化开始,风险更小。
Q:推测解码会不会明显降低生成质量,适合在高风险业务里用吗?
A:推测解码在大多数公开实验中,对质量影响很小,但在高风险场景(金融、医疗)仍需谨慎。原因在于:它通过「草稿+验证」跳过了一部分逐 token 计算,理论上可能放大模型原有的偏差或幻觉。实操建议是:先在离线评估里对关键指标(准确率、一致性、合规性)做 A/B 测试,再在生产中灰度放量,并配合更严格的输出约束和人工抽检。如果业务对错误极度敏感,可以只在低风险请求上启用推测解码,高风险请求仍走保守路径。
Q:长上下文模型和 RAG,哪个更适合做企业知识库?
A:大多数企业知识库更适合「中等上下文 + RAG」的组合,而不是一味追求超长上下文。原因有三点:一是长上下文模型的预填充成本极高,窗口翻倍,成本往往不止翻倍;二是企业知识往往结构化、可检索,用向量检索+过滤能更精准地喂给模型;三是 RAG 便于做权限控制和数据更新。实操上,可以用 8K–32K 上下文的模型配合检索,把真正相关的几段内容拼成提示,再用提示压缩和剪枝控制长度,这样更经济也更可控。
Q:模型路由会不会让系统变得很难维护,出了问题不好排查?
A:模型路由确实会增加系统复杂度,但通过良好的观测和日志设计,可以把风险控制在可接受范围内。关键是:每次路由决策都要有可追踪的理由(比如置信度、任务类型、历史表现),并在日志中记录「请求→路由结果→模型输出→反馈」。这样一旦出现异常,可以快速定位是路由策略问题,还是某个具体模型的问题。建议在早期先用简单规则路由(按长度、任务类型),等监控和回溯体系成熟后,再逐步引入学习型路由器,避免一上来就把系统搞得过于黑盒。
Q:应用层缓存会不会导致用户拿到过期或不准确的答案?
A:缓存确实有「过期」风险,所以设计策略时要在命中率和新鲜度之间做平衡。原因在于:知识库更新、业务规则变化、用户上下文差异,都会让旧答案失效。实操建议是:对强依赖实时性的内容(价格、库存、时效政策)禁用缓存,或设置极短 TTL;对稳定知识(产品说明、使用教程)可以设置较长 TTL,并在底层数据更新时主动失效相关缓存。同时,可以在语义缓存上加一层「时间权重」或版本号,避免很久以前的答案继续被命中。这样既能吃到缓存带来的成本红利,又不至于在关键场景踩坑。
这一整套优化思路,很多都来自真实团队在生产里的摸索和踩坑。你可以先挑一两条最贴近当前痛点的路径试起来,等账单和监控曲线开始变化,再慢慢把更多技术叠加进去。留一点空间给未来的迭代,也给自己一点试错的余地。

