99% 的团队在部署 DeepSeek 时,都把“Docker 部署”和“本地跑大模型”混为一谈,结果不是显卡被打爆,就是成本失控。更现实的做法,是先搞清楚:你到底要部署的是应用、代理网关,还是自建推理服务。路径选对了,Docker 只是打包和编排工具,而不是“魔法减显存按钮”。
据公开资料,DeepSeek V4 Pro 是 1.6 万亿参数的 MoE 模型(激活参数约 490 亿),V4 Flash 约 2840 亿参数(激活约 130 亿),都支持 100 万 token 长上下文,这个体量远远超出“随便一台笔记本”的范畴。很多团队一上来就想自建 V4,结果发现 GPU 预算直接顶到天花板。
如果你只是想在生产环境稳定用上 DeepSeek,多数情况下:容器化你的应用,直接调用托管 DeepSeek API,就是最省心、最安全的方案。
下面会从“最简单”到“最硬核”,拆开 5 条主线:
- 容器化应用,直连 DeepSeek 托管 API
- 加一层 LiteLLM 代理做网关和治理
- 用 Docker Model Runner 跑本地 DeepSeek R1 / distill 模型
- 用 Ollama + Open WebUI 做本地聊天体验
- 用 vLLM / SGLang 自建 DeepSeek V4 GPU 推理服务
DeepSeek Docker 部署到底指什么?
很多人搜索“DeepSeek Docker”,心里想的是“拉个镜像本地跑 DeepSeek”,但这个说法本身就很模糊。更准确地说,它通常指三类事情之一:
- 用 Docker 打包一个调用 DeepSeek 托管 API 的应用或网关
- 用 Docker Model Runner / Ollama 在本地跑 DeepSeek R1 / distill 这类模型
- 用 vLLM / SGLang 自建 DeepSeek V4 权重 + GPU 推理服务
Docker 只负责“打包和运行软件”,并不会让模型变小、显存变少。DeepSeek V4 Pro 和 V4 Flash 都是超大 MoE 模型,官方给出的 1M 上下文窗口,也意味着 KV Cache 会非常吃显存。说实话,如果你还在纠结“8G 显存能不能跑 V4”,那大概率应该先用托管 API。
哪条路径更适合你?
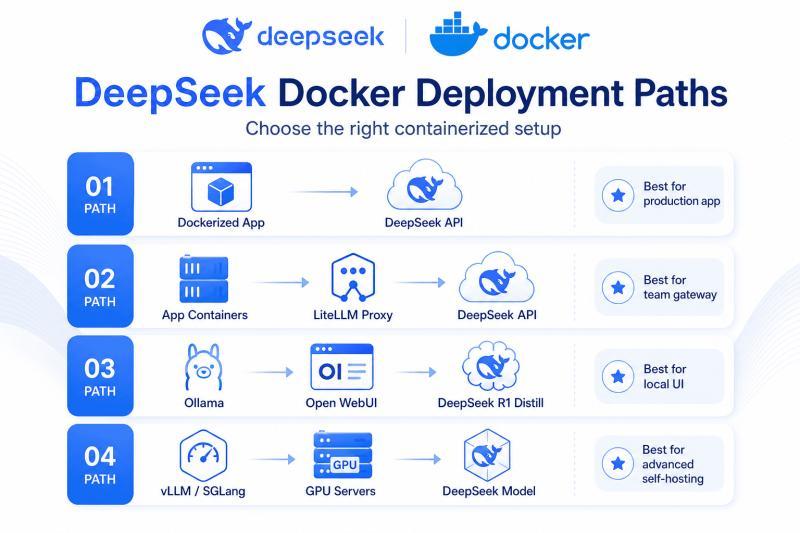
可以先用一个简单判断:
- 想快速上线产品、SaaS、内部工具 → 容器化应用 + 托管 DeepSeek API
- 想统一管理多模型、多厂商、做预算和路由 → 加 LiteLLM 代理
- 想在本地玩 DeepSeek R1 / distill、做离线 demo → Docker Model Runner 或 Ollama + Open WebUI
- 已有多卡 GPU 集群、对延迟和数据主权有极高要求 → vLLM / SGLang 自建 V4
有一位做企业内部平台的团队,早期直接上 vLLM 自建 V4,结果 GPU 账单远超预期,后来改成“生产走托管 API,本地只保留小模型做预处理”,成本直接降了一半多。
部署前你真的需要的准备
你不需要把下面所有东西都装一遍,只要对照你选的路径,勾选对应项就行:
- Docker Engine 或 Docker Desktop
- Docker Compose v2(命令是
docker compose,不是老的docker-compose) - DeepSeek 账号和 API Key(走托管 API 必备)
- LiteLLM(如果你要做内部网关 / 代理)
- Docker Model Runner(想用 Docker 原生命令跑本地模型)
- Ollama + Open WebUI(想要本地聊天 UI)
- Hugging Face Token(部分自建模型下载需要)
- NVIDIA 驱动 + NVIDIA Container Toolkit(跑 GPU 容器必备)
- 足够的磁盘、内存和显存(尤其是长上下文场景)
- 一个小型测试项目,用来验证链路
Docker Model Runner 支持通过 OpenAI 和 Ollama 兼容 API 暴露模型,还能把 GGUF 模型打成 OCI 工件,底层可以选 llama.cpp、vLLM 或 Diffusers 引擎,其中 vLLM 需要支持的 NVIDIA GPU 环境。
Open WebUI 是一个自托管 AI 平台,原生支持 Ollama 和 OpenAI 兼容 API,官方 Docker 快速上手文档也推荐使用 Docker Compose v2 语法来管理整个栈。
这些模型名字,千万别搞混
DeepSeek 当前 API 文档里,主推模型是:
deepseek-v4-flashdeepseek-v4-pro
而旧的 deepseek-chat 和 deepseek-reasoner 只是兼容别名,官方已经标明将在 2026 年 7 月 24 日起废弃。如果你现在新接入,还在用老名字,未来迁移时会多一层坑。
另一方面,Docker Hub 上的镜像 ai/deepseek-r1-distill-llama 是 Docker 发布的 DeepSeek R1 distill Llama 模型,和托管的 DeepSeek V4 API 完全不是一回事。它的标签包括:
8B-Q4_08B-Q4_K_M8B-F1670B-Q4_070B-Q4_K_M
一个简单判断:名字里带
deepseek-v4-*的,多半是 API 模型;带deepseek-r1-distill-*的,通常是本地可跑的压缩版或蒸馏版。
方法一:容器化应用,调用 DeepSeek 托管 API(推荐)
对大多数生产团队来说,这是最稳妥的 DeepSeek Docker 部署方式:
- 你的应用跑在 Docker 里
- 应用通过 HTTPS 调用 DeepSeek 托管 API
- 模型推理、扩缩容、GPU 运维都交给 DeepSeek
你将搭建的结构
一个简单的 FastAPI 服务,暴露一个 /chat 接口:
deepseek-api-app/
├─ app/
│ └─ main.py
├─ .env.example
├─ requirements.txt
├─ Dockerfile
└─ docker-compose.yml
.env.example
DEEPSEEK_API_KEY=sk-your-key-here
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-v4-flash
不要把真正的 .env 提交到代码仓库。
requirements.txt
fastapi
uvicorn[standard]
openai
pydantic
app/main.py
import os
from typing import Optional
from fastapi import FastAPI, HTTPException
from openai import OpenAI
from pydantic import BaseModel
class ChatRequest(BaseModel):
prompt: str
system: Optional[str] = "You are a helpful coding assistant."
app = FastAPI(title="DeepSeek Docker API App")
def get_client() -> OpenAI:
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise RuntimeError("DEEPSEEK_API_KEY is not set")
return OpenAI(
api_key=api_key,
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
)
@app.get("/healthz")
def healthz():
return {"status": "ok", "has_api_key": bool(os.getenv("DEEPSEEK_API_KEY"))}
@app.post("/chat")
def chat(request: ChatRequest):
model = os.getenv("DEEPSEEK_MODEL", "deepseek-v4-flash")
try:
client = get_client()
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": request.system},
{"role": "user", "content": request.prompt},
],
max_tokens=500,
stream=False,
extra_body={
"thinking": {"type": "disabled"}
},
)
return {
"model": model,
"answer": response.choices[0].message.content,
}
except Exception as exc:
raise HTTPException(status_code=500, detail=str(exc))
DeepSeek 官方 Quick Start 展示的就是这种 OpenAI 兼容的 /chat/completions 格式,支持 model、messages、可选的 thinking、reasoning_effort 和 stream 等参数。
Dockerfile
FROM python:3.12-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN addgroup --system app && adduser --system --ingroup app app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app ./app
USER app
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
docker-compose.yml
services:
app:
build: .
env_file:
- .env
ports:
- "8000:8000"
restart: unless-stopped
healthcheck:
test: ["CMD", "python", "-c", "import urllib.request; urllib.request.urlopen('http://localhost:8000/healthz')"]
interval: 30s
timeout: 5s
retries: 3
运行服务
cp .env.example .env
# 编辑 .env,填入真实密钥
docker compose up --build -d
docker compose logs -f app

本地接口测试
curl http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{
"prompt": "Explain Docker healthchecks in two sentences."
}'
直接对 DeepSeek API 做冒烟测试
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "Reply with OK if the API works."}
],
"thinking": {"type": "disabled"},
"max_tokens": 20,
"stream": false
}'
生产环境里的密钥管理
本地开发用 .env 还算方便,但一到生产,建议切换到 Docker Secrets 或云厂商的密钥管理服务。Docker Compose 的 secrets 会挂载到容器内的 /run/secrets/,并且需要在服务里显式声明才能访问。
我自己在给团队做落地时,一般会:
- 开发环境:
.env+ 本地 Docker Compose - 测试 / 预发:Docker Secrets + CI 注入
- 生产:云 Secret Manager + 容器只读挂载
方法二:用 LiteLLM 做 DeepSeek 代理网关
当你希望所有内部服务只对接一个 OpenAI 兼容入口,而背后可以灵活切换 DeepSeek、OpenAI、Anthropic 等提供商时,LiteLLM 就很有用。它能帮你做:
- 虚拟 Key(给不同团队 / 应用分配配额)
- 费用统计和预算控制
- 速率限制和日志审计
- 模型路由和 A/B 测试
- 更平滑的多厂商切换
LiteLLM 文档中,DeepSeek 模型通常用 deepseek/deepseek-v4-flash 这种 provider 前缀形式,在代理配置里通过 model_list 映射:model_name 是对外暴露的别名,litellm_params.model 是实际调用的提供商模型名。
litellm-config.yaml
model_list:
- model_name: deepseek-v4-flash
litellm_params:
model: deepseek/deepseek-v4-flash
api_key: os.environ/DEEPSEEK_API_KEY
- model_name: deepseek-v4-pro
litellm_params:
model: deepseek/deepseek-v4-pro
api_key: os.environ/DEEPSEEK_API_KEY
general_settings:
master_key: os.environ/LITELLM_MASTER_KEY
这个配置遵循 LiteLLM 官方的 deepseek/ 模式,并使用当前 V4 模型名。如果你用的 LiteLLM 版本还不支持 V4 名字,可以升级 LiteLLM,或者把 DeepSeek 当成普通 OpenAI 兼容提供商来配置。
.env
DEEPSEEK_API_KEY=sk-your-deepseek-key
LITELLM_MASTER_KEY=sk-change-this-admin-key
LITELLM_SALT_KEY=sk-generate-a-stable-random-salt
POSTGRES_PASSWORD=change-this-password
LiteLLM 的生产指引里强调:LITELLM_SALT_KEY 用来加解密存储的 LLM 凭据,一旦开始存模型配置,就不要再随便改这个值。
docker-compose.yml
services:
litellm-db:
image: postgres:16-alpine
environment:
POSTGRES_DB: litellm
POSTGRES_USER: litellm
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
volumes:
- litellm_db:/var/lib/postgresql/data
restart: unless-stopped
litellm:
image: docker.litellm.ai/berriai/litellm:main-latest
depends_on:
- litellm-db
ports:
- "4000:4000"
env_file:
- .env
environment:
DATABASE_URL: postgresql://litellm:${POSTGRES_PASSWORD}@litellm-db:5432/litellm
volumes:
- ./litellm-config.yaml:/app/config.yaml:ro
command: ["--config", "/app/config.yaml", "--port", "4000"]
restart: unless-stopped
volumes:
litellm_db:
LiteLLM 的虚拟 Key 功能需要数据库、DATABASE_URL 和 master key 来管理代理层的访问密钥,这也是为什么 Compose 里要加一个 Postgres。
通过 LiteLLM 代理测试 DeepSeek
docker compose up -d
curl http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${LITELLM_MASTER_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "user", "content": "Give me one Docker hardening tip."}
],
"max_tokens": 100
}'
不要把 LiteLLM 代理直接裸露在公网,至少要加上:
- TLS(HTTPS)
- 鉴权(API Key / OAuth / 内网网关)
- 速率限制
- IP 白名单或零信任访问
方法三:用 Docker Model Runner 本地跑 DeepSeek R1 / distill
Docker Model Runner 更适合想用 Docker 原生命令管理本地模型工作流的场景,它可以通过 OpenAI、Anthropic 和 Ollama 兼容 API 暴露本地模型服务。
这条路径通常用来跑 DeepSeek R1 / distill 这类模型,而不是托管的 DeepSeek V4 API 模型。
启用 Docker Model Runner
在 Docker Desktop 里,可以在 AI 设置中直接启用 Model Runner;如果是纯 Docker Engine 环境,需要安装 Model Runner 插件,然后用下面命令验证:
docker model version
# 或
docker model run ai/smollm2
拉取 DeepSeek R1 Distill 模型
docker model pull ai/deepseek-r1-distill-llama:8B-Q4_K_M
docker model list
Docker Hub 当前在官方 Verified Publisher 命名空间下列出了 ai/deepseek-r1-distill-llama,包含多个 8B 和 70B 的量化版本标签。
交互式运行
docker model run ai/deepseek-r1-distill-llama:8B-Q4_K_M
通过 OpenAI 兼容 API 调用
在宿主机上:
curl http://localhost:12434/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/deepseek-r1-distill-llama:8B-Q4_K_M",
"messages": [
{"role": "user", "content": "Explain Docker volumes in one paragraph."}
]
}'
Docker 的 API 参考文档说明:OpenAI 兼容客户端应使用 /engines/v1 路径,并在 model 字段中写完整的模型标识(包括命名空间)。
在其他容器里访问 Model Runner
Docker Desktop 环境下,容器可以通过:
http://model-runner.docker.internal/engines/v1
Docker Engine + Compose 环境,需要在服务里加:
extra_hosts:
- "model-runner.docker.internal:host-gateway"
然后在容器内使用:
http://model-runner.docker.internal:12434/engines/v1
这是 Docker 官方文档里推荐的“容器访问宿主服务”的方式之一,用 host-gateway 解决宿主名解析问题。
方法四:Ollama + Open WebUI 本地 DeepSeek 聊天栈
当你想要一个“完全本地、带 Web UI 的聊天体验”,并且接受使用 DeepSeek R1 / distill 这类本地模型变体时,可以考虑:
- 用 Ollama 管理和加载本地模型
- 用 Open WebUI 提供浏览器聊天界面
Ollama 的 Docker 文档给出了 CPU、NVIDIA GPU、AMD GPU 和 Vulkan 的示例。以 NVIDIA 为例,需要先安装 NVIDIA Container Toolkit,然后用 --gpus=all 运行容器。

docker-compose.yml
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
depends_on:
- ollama
ports:
- "3000:8080"
environment:
OLLAMA_BASE_URL: http://ollama:11434
WEBUI_SECRET_KEY: change-this-secret
volumes:
- open-webui:/app/backend/data
restart: unless-stopped
volumes:
ollama:
open-webui:
Docker Compose 对 GPU 的支持是通过 deploy.resources.reservations.devices 来声明的,其中 capabilities 必须包含 gpu 才会被识别为 GPU 资源。
如果是纯 CPU 机器,可以直接删掉 ollama 服务里的整个 deploy: 块。

启动栈
docker compose up -d
docker compose logs -f ollama
在 Ollama 中拉取 DeepSeek 模型
docker exec -it ollama ollama pull deepseek-r1:8b
Ollama 模型库里列出了 DeepSeek R1 的多个标签,包括 1.5b、7b、8b、14b、32b、70b 和 671b 等,选择时要老老实实对照自己的显存和内存,不要硬上。
浏览器访问:
http://localhost:3000
然后创建账号、验证 Ollama 连接,并在模型列表里选择刚刚拉取的 DeepSeek 模型。
停止或删除栈
docker compose down
如果要连同本地 Open WebUI 数据和 Ollama 模型卷一起删掉:
docker compose down -v
Open WebUI 官方文档也用 docker compose up -d 启动,并提醒 docker compose down -v 会删除卷数据,这一步一旦执行,聊天记录和本地模型缓存都会被清空。
方法五:进阶——用 vLLM Docker 自建 DeepSeek V4 推理
这一条是“硬核路线”,只适合已经有成熟 GPU 基础设施、推理服务经验,并且有明确自建理由(如数据主权、极端低延迟、本地网络隔离)的团队。
vLLM 在 2026 年 4 月 24 日的博客中宣布支持 DeepSeek V4 系列,描述 V4 Pro 为 1.6T 参数大模型,V4 Flash 约 285B 参数,两者都支持最高 100 万 token 上下文。
vLLM Docker 基本模式
vLLM 官方 Docker 部署文档使用 vllm/vllm-openai 镜像,挂载 Hugging Face 缓存目录,传入 HF_TOKEN,开放 8000 端口,并使用 --ipc=host。
一个通用的 vLLM Docker 启动模式类似这样:
export HF_TOKEN=your-huggingface-token
docker run --gpus all \
--ipc=host \
-p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=${HF_TOKEN}" \
vllm/vllm-openai:latest \
--model deepseek-ai/DeepSeek-V4-Flash \
--trust-remote-code
针对 DeepSeek V4,vLLM 官方给出了不同 GPU 架构的专门命令,例如:
- V4 Pro:8×B200 或 8×B300
- V4 Flash:4×B200 或 4×B300
并配合 --kv-cache-dtype fp8、--enable-expert-parallel、--data-parallel-size、--tokenizer-mode deepseek_v4、--tool-call-parser deepseek_v4、--reasoning-parser deepseek_v4 等参数。
示例:vLLM DeepSeek V4 Flash 模式
docker run --gpus all \
--ipc=host \
-p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:deepseekv4-cu130 deepseek-ai/DeepSeek-V4-Flash \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 4 \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--reasoning-parser deepseek_v4
不要把这条命令直接复制到一台随便的服务器上就开跑。你需要认真匹配:
- 镜像标签(是否支持你的 CUDA / 驱动版本)
- GPU 架构和数量
- 模型变体(Pro / Flash)
- 并行策略(expert parallel / data parallel)
- 上下文长度和 KV Cache 占用
vLLM 的 DeepSeek V4 Pro 配方里还提到:Think Max 推理模式需要 --max-model-len >= 393216 才不会被截断,并给出了 8×B300 和 8×H200 的部署说明,其中 H200 的上下文在配方里被限制在 80 万 token 左右,以给 KV Cache 留出空间。
SGLang 作为替代方案
SGLang 也提供了 DeepSeek V4 的部署文档,包括针对 B300、B200、GB200/GB300 和 H200 的硬件专用 Docker 镜像,以及一个最小化 Docker 启动模式:
--gpus all--shm-size调整共享内存- 挂载 Hugging Face 缓存
- 设置
HF_TOKEN - 使用
--ipc=host
对大多数团队来说,托管 DeepSeek API 或托管推理平台,往往比自建 V4 更省心。自建虽然看起来“免费模型 + 自己的 GPU”,但一旦考虑到运维、监控、弹性和故障恢复,综合成本并不一定低。
Docker GPU 环境检查与排错
先在宿主机确认 GPU 是否正常:
nvidia-smi
如果这一步就失败,那就别急着折腾容器,先把宿主机驱动装好。之后安装并配置 NVIDIA Container Toolkit。
NVIDIA 当前的安装指南大致包括:
- 安装
nvidia-container-toolkit - 用
sudo nvidia-ctk runtime configure --runtime=docker配置 Docker 运行时 - 重启 Docker 服务
然后测试 GPU 透传:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
NVIDIA 官方示例工作负载文档就是用这条命令来验证 Docker 是否能访问 GPU 的。如果这里都不通,后面 vLLM、Ollama、Model Runner 全都会踩坑。
生产环境加固清单
在把任何 DeepSeek Docker 部署方案推到生产前,可以对照这份清单逐项确认:
- 固定镜像标签,不要用
latest - 不要提交
.env到代码仓库 - 使用 Docker Secrets 或云密钥管理
- 尽量以非 root 用户运行容器
- 为关键服务添加健康检查和就绪检查
- 配置合理的重启策略
- 记录请求 ID、延迟、模型名和错误信息
- 对外接口加速率限制
- 所有公网入口必须走 TLS + 鉴权
- Open WebUI、Ollama、vLLM、SGLang、LiteLLM 默认只暴露在内网
- 用卷持久化模型和缓存,避免重复下载大权重
- 在 CI/CD 里做镜像安全扫描
- 文档里写清楚模型名、版本、价格假设和硬件假设
有用户反馈,他们在没做限流的情况下把 Open WebUI 暴露到公网,结果被脚本扫到后疯狂刷请求,直接把家用 GPU 打到 100% 长时间不降,这种“免费算力”很快就会被人盯上。
成本、隐私与性能的取舍
DeepSeek 的价格按输入 / 输出 token 计费。以最近一次审查时的公开数据为例:
- V4 Flash:缓存命中输入约 $0.0028 / 100 万 token
- V4 Flash:缓存未命中输入约 $0.14 / 100 万 token
- V4 Flash:输出约 $0.28 / 100 万 token
- V4 Pro:有临时 75% 折扣(截至 2026 年 5 月 31 日),价格可能随时调整
官方也提醒价格可能变化,建议定期查看价格页。这里有个常被忽略的点:
对于请求量不稳定、峰谷明显的业务,自建 GPU 往往比按量付费的 API 更贵,因为 GPU 服务器在闲时也要付钱。
长上下文推理对显存和内存的要求尤其高,即便模型权重是开源的,硬件和运维成本也不会凭空消失。我自己的观察是:很多团队在 POC 阶段高估了自建的“自由度”,低估了长期运维的复杂度。
常见错误与排查方向
DeepSeek 的错误码文档列出了一些典型情况:
- 401:鉴权失败(API Key 错误或缺失)
- 402:余额不足
- 429:触发速率限制
- 500:服务端错误
- 503:服务过载
在 Docker 场景下,常见的额外问题包括:
- 容器内时间漂移导致签名或证书异常
- 代理 / 网关层(如 LiteLLM)配置了错误的模型名
- 环境变量没正确传入容器(
env_file或 Secrets 配置错误)
推荐的部署模式
模式 A:单应用容器 → DeepSeek 托管 API
适合:SaaS 应用、后端 API、内部工具,以及希望运维简单的团队。
Browser / client
↓
Your app container
↓
DeepSeek hosted API
如果你现在还在选型阶段,可以优先从这个模式起步,后续再按需加 LiteLLM 或本地栈。
模式 B:应用容器 → LiteLLM 代理 → DeepSeek API
适合:需要虚拟 Key、预算控制、模型路由和统一审计的团队。
App containers
↓
LiteLLM proxy
↓
DeepSeek API
LiteLLM 的虚拟 Key 文档支持按 Key、用户、团队维度做消费统计和限额,对多团队共用一套底层模型资源的场景非常友好。
模式 C:Open WebUI / 本地应用 → Ollama / Docker Model Runner → 本地 DeepSeek 相关模型
适合:本地原型、演示、隐私敏感的个人实验、离线开发体验。
Open WebUI or local app
↓
Ollama / Docker Model Runner
↓
Local DeepSeek-related model
更适合作为“实验场”和“沙盒”,而不是托管 V4 API 的完全替代品,除非你已经验证本地模型质量和硬件都能满足需求。
模式 D:应用 → 内部网关 / 负载均衡 → vLLM / SGLang GPU 集群 → DeepSeek V4 权重
适合:有成熟 GPU 集群和推理平台经验的团队。
Apps
↓
Internal gateway / load balancer
↓
vLLM or SGLang GPU servers
↓
DeepSeek V4 weights
这条路线需要你认真规划:
- GPU 资源和拓扑
- KV Cache 策略和上下文长度
- 模型版本管理和灰度发布
- 监控、告警和自动扩缩容
- 成本核算和容量预估
小结与行动建议
如果你只记得一件事,那就是:生产优先用“容器化应用 + 托管 DeepSeek API”,本地和自建 GPU 只在你真的需要时再上。
这套分层思路在不少团队里被反复验证有效:
- 先用最简单的模式跑通业务闭环
- 再按需叠加 LiteLLM、Ollama、Model Runner
- 最后才考虑 vLLM / SGLang 这种重资产方案
遇到类似技术选型时,把这篇文章翻出来对照一下,往往比随手问身边人更系统。你也可以把这几种模式画成自己的架构草图,贴在团队文档里,后面每次扩展都能少走弯路。
常见问题
Q:我只想在生产环境稳定用 DeepSeek,最简单的做法是什么?
A:最简单的做法是:用 Docker 容器化你的后端应用,然后在应用里直接调用 DeepSeek 托管 API(deepseek-v4-flash 或 deepseek-v4-pro)。这样模型推理、扩缩容和 GPU 运维都交给 DeepSeek,你只需要管理自己的业务逻辑和配置。之所以推荐这条路,是因为它对基础设施要求最低,出问题时排查链路也最短。落地时记得:用环境变量或 Secrets 管理 DEEPSEEK_API_KEY,加上健康检查和日志,把模型名、版本和价格假设写进配置文档,方便后续升级。
Q:什么时候应该考虑用 LiteLLM 做 DeepSeek 代理?
A:当你开始有多个应用、多个团队都要用 DeepSeek,或者需要统一做 Key 管理、预算控制、模型路由时,就可以考虑 LiteLLM。LiteLLM 能把 DeepSeek、OpenAI 等不同厂商统一成一个 OpenAI 兼容入口,并通过虚拟 Key 做配额和审计。判断标准是:如果你已经在 Excel 里手动统计各个服务的 API 消耗,或者经常需要临时切换模型提供商,那 LiteLLM 基本就值得上了。部署时要注意:给 LiteLLM 配置数据库、LITELLM_MASTER_KEY 和 LITELLM_SALT_KEY,并确保代理本身也有鉴权和 TLS 保护。
Q:本地跑 DeepSeek R1 / distill,用 Docker Model Runner 和 Ollama 怎么选?
A:如果你更熟悉 Docker 命令行、希望用统一的 docker model 工作流管理模型,Docker Model Runner 会更顺手;如果你更在意聊天体验和 Web UI,Ollama + Open WebUI 会更友好。两者在底层都可以跑 DeepSeek R1 / distill 这类模型,但 Model Runner 更偏“工程化工作流”,Ollama 则偏“个人 / 小团队体验”。建议做法是:先用 Ollama 快速感受模型效果,再用 Model Runner 或正式推理栈把确定下来的模型接入到应用里,避免一开始就把所有东西绑死在某个工具上。
Q:自建 vLLM / SGLang 跑 DeepSeek V4,一般会踩哪些坑?
A:最常见的坑包括:低估显存需求、忽略 KV Cache 占用、错误设置并行参数,以及没有为长上下文预留足够内存。DeepSeek V4 Pro 和 Flash 都支持 1M 上下文,如果你随手把 max-model-len 拉满,却只配了少量 GPU,很容易出现 OOM 或性能极差的情况。还有一个风险是成本:GPU 集群在低负载时也要付钱,自建如果没有稳定高负载,往往比按量付费的 API 更贵。建议在自建前,先用托管 API 做压测,估算真实 QPS 和上下文需求,再对照 vLLM / SGLang 官方配方规划硬件和参数。
Q:如何判断自己该用托管 API 还是自建 GPU 推理?
A:可以从三个维度来判断:请求量曲线、数据合规要求和团队运维能力。如果你的请求量波动大、峰谷明显,托管 API 通常更划算;如果你有强数据主权或本地合规要求(比如数据不能出境),自建会更有必要;如果团队里没有熟悉 GPU 调优、推理服务和监控的人,自建的隐性成本会非常高。一个可操作的建议是:先用托管 API 跑一段时间,记录真实的 token 消耗和延迟需求,再用这些数据反推“如果自建需要多少 GPU、多少人力”,算一笔账再决定要不要上自建。


