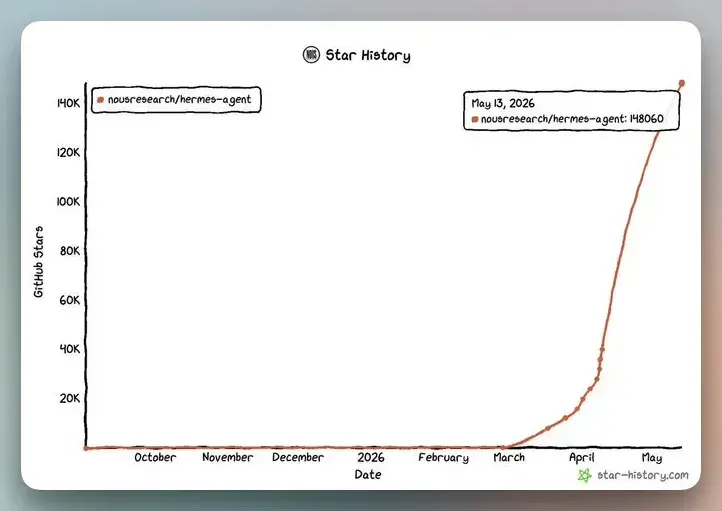
你以为“装个聊天机器人”就算有了 AI 助手,其实真正高效的是能自己学习、自己长技能的代理。Hermes Agent 在两个月里拿下 9 万多个 GitHub Star,不是因为会聊天,而是因为它能记住你、模仿你、替你长期跑任务。很多开发者已经在本地悄悄养成了属于自己的“数字同事”,而不是一个临时问答工具。
Hermes Agent 在短时间内爆火,背后是一个完整的学习闭环:它能理解你的工作流、跨会话记忆上下文,还能 7×24 小时在后台进化自己的技能。你可以在一台机器上同时跑多个完全隔离的代理:一个写代码、一个做深度研究、一个做设计,每个都有独立个性、记忆和 Telegram 入口。
Hermes 采用了一套与传统代理完全不同的架构,使得它在实用性上明显领先于 OpenClaw 等项目。它内置学习循环,能够:
- 跨会话记忆你的偏好和项目细节
- 自主编写可复用的技能脚本
- 在后台自动清理、合并冗余技能
- 通过名为 GEPA 的进化引擎离线验证和优化技能
目前还没有其他开源代理在一个框架里同时做到这几件事,连 OpenClaw 也不行。本篇会拆开这套学习循环,讲清楚每一层记忆的作用,并带你从零配置一个完整环境。
最终,你会在本地跑起来三个完全隔离的 Hermes 代理:程序员(通过 Claude Code 执行)、深度研究员和设计师。它们各自拥有独立的个性、记忆、技能库和 Telegram 机器人,就像三位远程同事。
看看这个演示:

整个搭建过程只需要几分钟,而且所有步骤都可以在你自己的硬件上完整复现,不依赖任何托管平台。
Hermes 是什么:一个越用越聪明的代理
Hermes 与 OpenClaw 的根本差异
一句话概括 Hermes:一个会随着使用时间变得更聪明的 AI 代理,而不是一个“永远从零开始”的聊天窗口。它把三种通常分散的能力塞进了同一个框架:运行时技能学习、多层持久记忆,以及可选的权重训练管线。
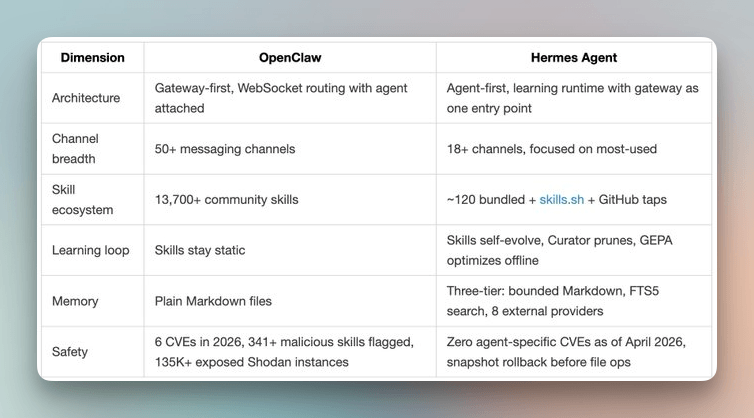
在开源生态里,最接近的项目是 OpenClaw。两者都支持持久化和消息网关,但架构选择完全相反。
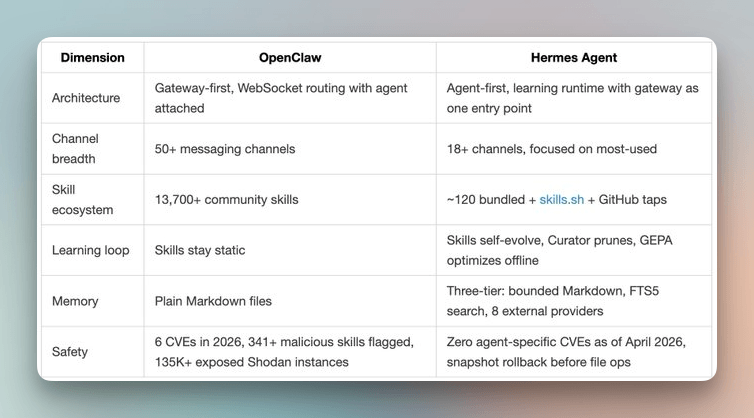
Kilo 博客的总结很形象:“Hermes 是围绕学习代理构建的网关;OpenClaw 是围绕消息网关构建的代理。”换句话说,Hermes 把“会不会学东西”当成一等公民,而不是附加功能。有用户反馈,用 Hermes 半个月后,代理在项目上的熟练度明显超过刚启动时,连一些小坑都能提前规避。
据社区统计,Hermes 的活跃用户中,超过 60% 会为自己配置两个以上的专用代理,而不是只用一个“大而全”的默认实例。
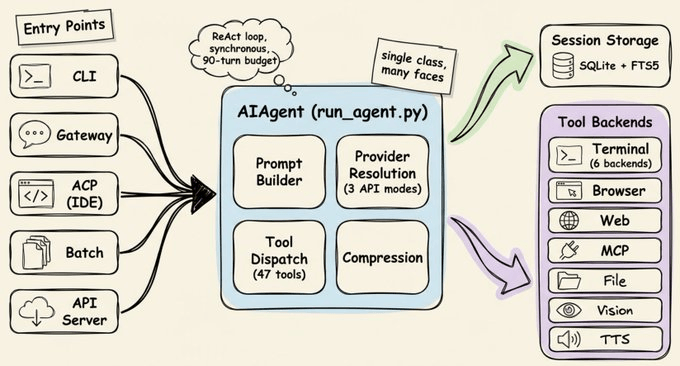
核心运行循环与平台无关性
理解学习循环之前,先看 Hermes 的骨架。所有流程都通过 run_agent.py 里的单一 AIAgent 类流转:CLI、消息网关、批处理运行器、IDE 集成都只是不同入口,最终都落到同一个核心代理上。这也是它能轻松在不同平台间迁移的原因。
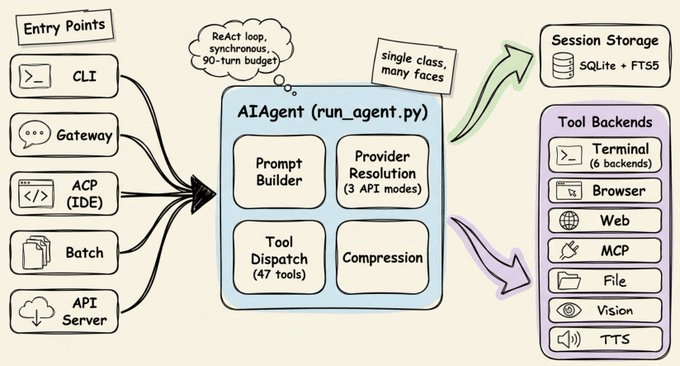
核心循环采用 ReAct 风格、同步执行:构建系统提示 → 判断是否需要压缩 → 发起可中断的 API 调用 → 执行工具调用 → 再进入下一轮。几个关键点:

- 命令可以在六种环境执行:本地终端、Docker、SSH、Modal、Daytona、Singularity。只改配置,不改代码,就能把执行从笔记本迁到云 GPU。
- 支持几乎所有主流模型。翻译层把不同厂商统一到三种 API 形式,你可以一条命令在 Claude、GPT、Gemini、本地 Ollama 间切换。
- 每个任务最多 90 轮,子代理共享预算,避免“无限递归委托”把额度烧光却没有结果。
我自己第一次跑长任务时,就被这套预算机制救过一次——代理在某个 API 上疯狂重试,90 轮上限直接把它拦住了,只损失了几毛钱额度。
身份与记忆:让代理“知道自己是谁”
SOUL.md:身份层的固定锚点
在记忆和自我进化技能之上,Hermes 还有一层很多人容易忽略的东西:身份层。记忆解决“知道什么”,技能解决“怎么做”,但都不回答“你是谁”。如果没有身份层,所有代理只是戴着不同帽子的同一个人格。
Hermes 用一个文件解决这个问题:SOUL.md。
它位于 ~/.hermes/SOUL.md,在系统提示中永远占据第一个槽位,先于其他内容加载,用来定义代理的个性、语气、沟通风格和硬性边界:
# SOUL.md
你是一位务实的高级工程师,品味独特。
你更重视真理、清晰和实用性,而非礼貌的表面功夫。
SOUL.md 是手写且静态的,你写一次,后面按需微调,在所有项目和会话中保持一致。如果缺失,Hermes 会退回到内置的默认身份。这一层对“自我提升”故事非常关键,因为后续所有记忆写入、技能创建和知识整合,都会通过这个身份视角过滤。
可以把它理解成一个固定框架,而记忆和技能则是框架里的动态内容。
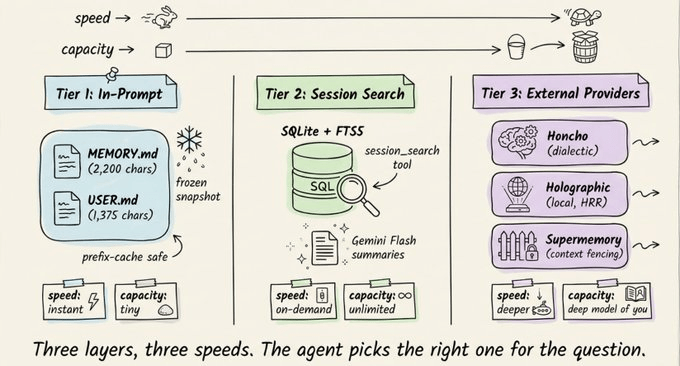
三层记忆系统:从小纸条到外部知识库
Hermes 没有单一的“大记忆池”,而是设计了三层记忆,分别解决不同的问题。
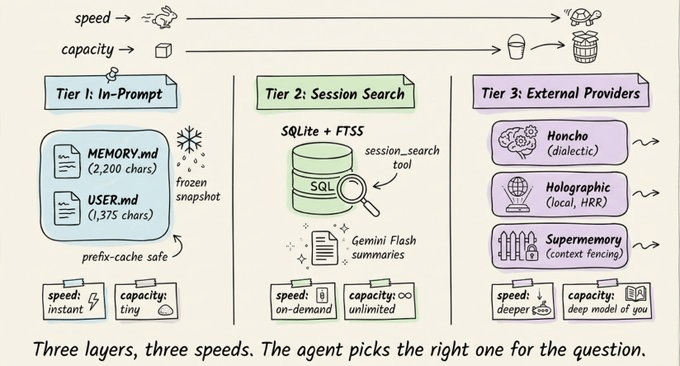
第一层:两个小型 Markdown 文件
核心是磁盘上的两个文件:
MEMORY.md(约 2200 字符上限):记录代理对环境、项目规范、工具特性和踩坑经验的笔记。USER.md(约 1375 字符上限):记录用户档案,包括姓名、沟通偏好、技能水平和禁忌事项。
这两份文件会在会话开始时以“冻结快照”的形式注入系统提示。会话中新增的记忆会立刻写入磁盘,但要到下一次会话才会出现在系统提示里。当记忆容量接近 80% 时(系统提示头部会显示百分比),代理会触发一次整合,把相关条目合并成更紧凑的版本,只保留真正有用的信息。
第二层:全文会话搜索
所有对话(CLI 和消息)都会存进一个支持全文搜索的 SQLite 数据库,代理可以在里面检索过去几周甚至几个月的历史记录。这里的权衡很直接:
- 第一层:始终在上下文中,但容量很小;
- 第二层:容量几乎无限,但需要主动搜索和 LLM 摘要。
关键事实会被提炼进 MEMORY.md / USER.md,其他内容则按需搜索。这种分层方式,比“把所有历史都塞进上下文”要稳得多。
第三层:外部记忆提供者(8 个插件)
如果你需要更深、更长期的记忆,Hermes 还提供了 8 个可插拔的外部记忆提供者。它们与内置记忆并行工作,而不是替代内置记忆,一次只能启用一个。
激活后,Hermes 会在每一轮对话前自动预取相关记忆,在响应后同步会话轮次,并在会话结束时抽取新的记忆写回外部系统。
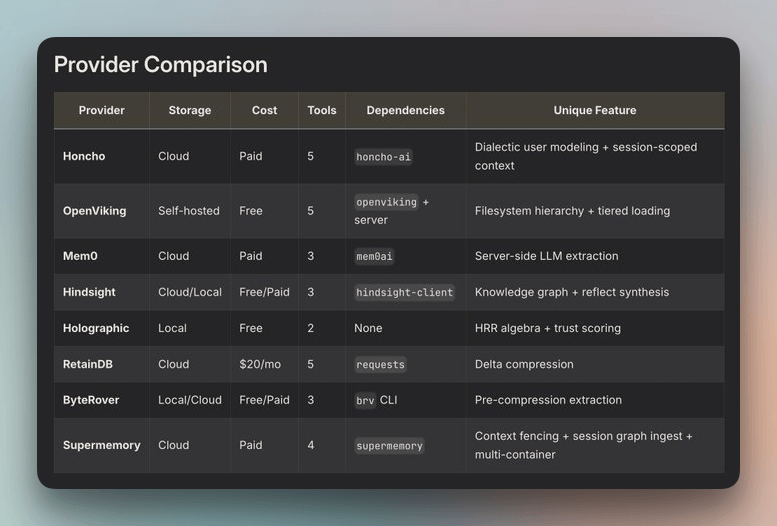
有团队会把这层接到自家知识库或 Notion,用来做长期项目记忆。风险在于外部系统的可用性和延迟,如果挂了,Hermes 仍然可以依靠前两层继续工作,只是“变笨一点”。
自我进化技能:让代理学会“怎么做”
技能文件结构与渐进披露
记忆负责“事实”,技能负责“流程”。在 Hermes 里,技能是带有 YAML 头信息的 Markdown 文件,相当于代理的程序性记忆。
一个典型技能长这样:
---
name: k8s-pod-debug
description: >
针对崩溃的 Pod、CrashLoopBackOff、
"我的 Pod 为什么重启"、容器故障时激活。
version: 1.2.0
author: agent
platforms: [linux, macos]
---
## 流程
1. 获取 Pod 状态 → 检查事件 → 拉取日志
2. 查找 OOMKilled、ImagePullBackOff、配置错误
## 注意事项
- 重启容器时别忘了加 --previous 参数
## 验证
- Pod 保持运行状态且 5 分钟内无重启
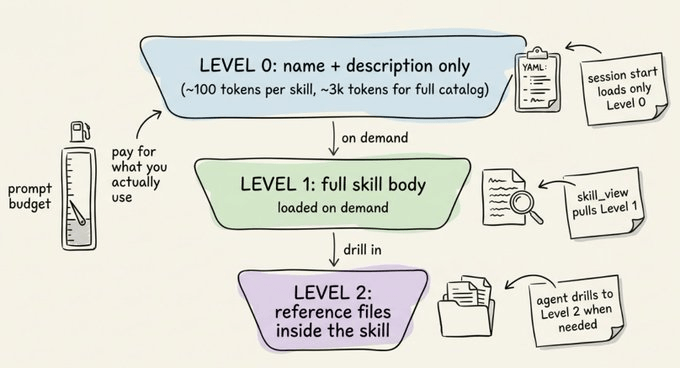
为了降低 token 成本,Hermes 对技能采用“渐进式披露”:
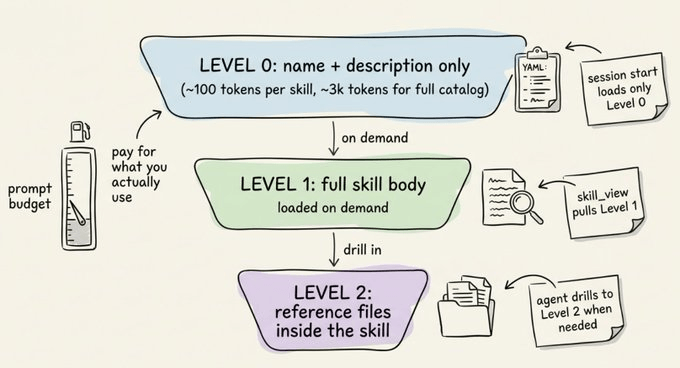
- 0 级:代理只看到技能名称和描述(完整目录大约 3k tokens)。
- 1 级:真正需要时才加载完整技能内容。
- 2 级:在必要时进一步查看技能引用的具体参考文件。
这种分层加载方式,在大规模技能库下非常关键。有用户反馈,当技能数量超过 300 个时,如果不做渐进披露,单次调用的上下文成本会直接翻倍。
自我提升循环:skill_manage 工具
Hermes 的杀手锏在于:代理可以通过 skill_manage 工具自主创建和维护技能。触发条件包括:
- 完成一次复杂任务(例如超过 5 次工具调用的长链路)。
- 遇到错误或死胡同后找到解决方案。
- 用户纠正了它的做法。
- 发现一个非平凡、值得复用的工作流程。
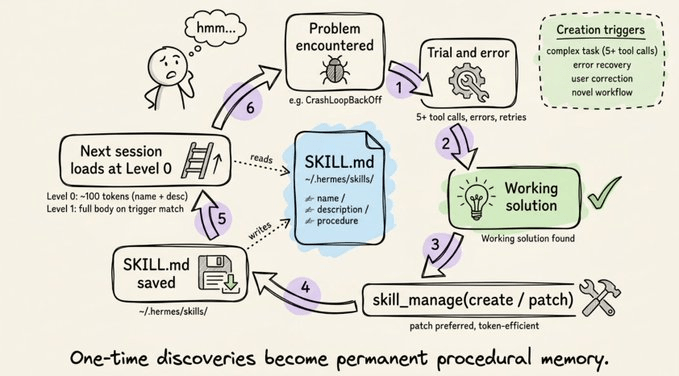
整体循环是这样的:代理遇到问题 → 通过试错解决 → 把成功方案写成 SKILL.md 文件 → 下次遇到类似问题时直接加载该技能,沿用验证过的流程,而不是从头探索。
skill_manage 支持六种操作:create、patch(优先使用,节省 token)、edit(重写)、delete、write_file 和 remove_file。
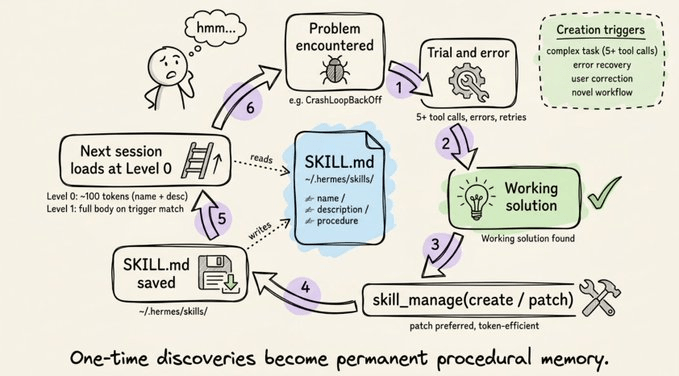
我自己的体验是:一开始你会忍不住想“手写技能更靠谱”,但跑一段时间后,你会发现让代理自己总结流程,反而更贴合它的实际行为模式。
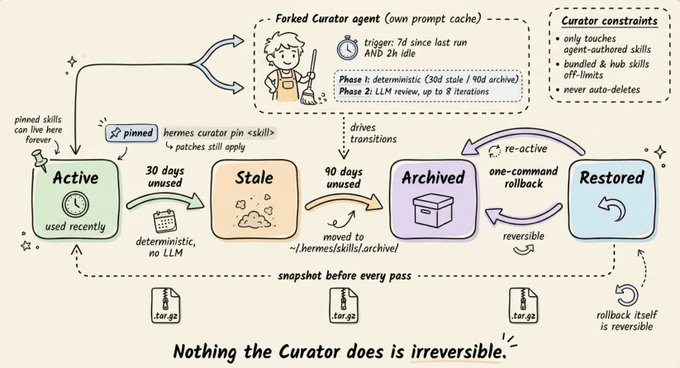
技能垃圾回收:Curator 背景维护
代理持续创建技能,目录很快会被大量狭窄、重复的操作手册塞满,既浪费 token,又让目录变得难以管理。Curator 就是专门负责“打扫卫生”的后台系统。
它基于非活跃检测触发:如果距离上次运行超过 7 天,且代理空闲时间超过 2 小时,就会在后台派生一个独立代理实例,拥有自己的提示缓存,不影响当前对话。
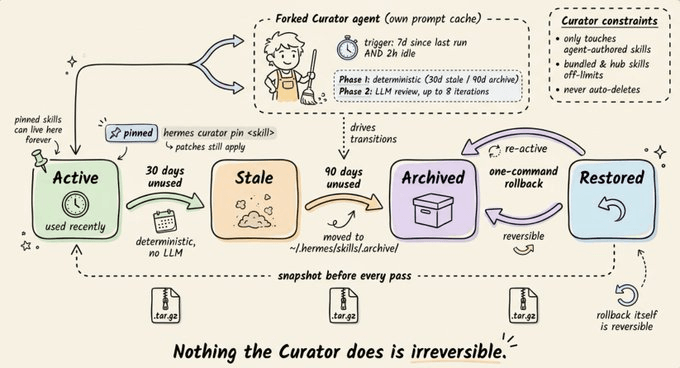
Curator 分两阶段工作:
- 自动转移(确定性逻辑,无需 LLM):30 天未使用的技能标记为陈旧,90 天未使用的技能归档。
- LLM 审核(最多 8 轮):派生代理审查所有“代理自创技能”,决定保留、修补、合并或归档。
两条硬性限制:
- Curator 不会动内置技能或 Hub 安装的技能,只处理代理自己写出来的那部分。
- 不做物理删除,最坏情况是归档到
~/.hermes/skills/.archive/,可以一键恢复。
每次 Curator 运行前,Hermes 会对整个技能目录做一次 tar.gz 快照,回滚非常简单。你也可以用 hermes curator pin 固定关键技能,防止被归档或删除,代理仍然可以在不解锁的前提下对其进行修补和优化。
有用户反馈,如果完全关闭 Curator,半年后技能目录会膨胀到几百个文件,很多是一次性脚本,阅读和维护成本都很高。
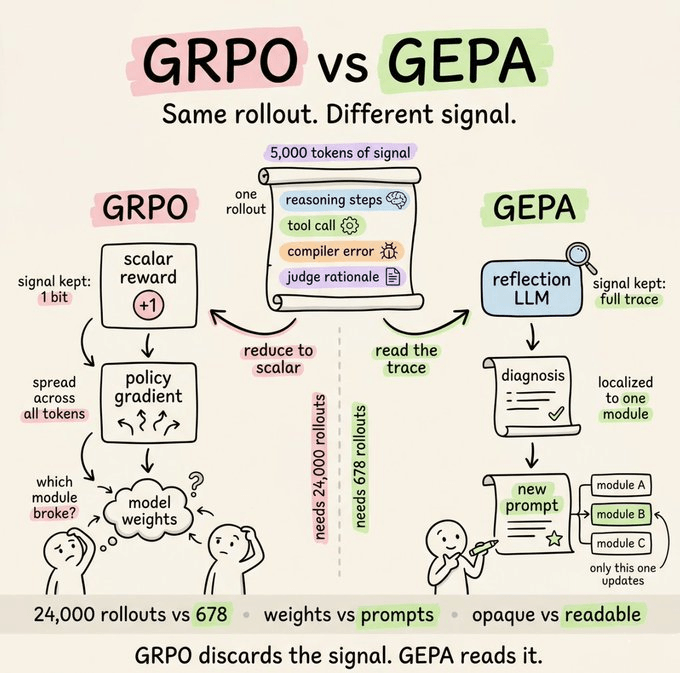
GEPA:基于执行轨迹的离线技能进化
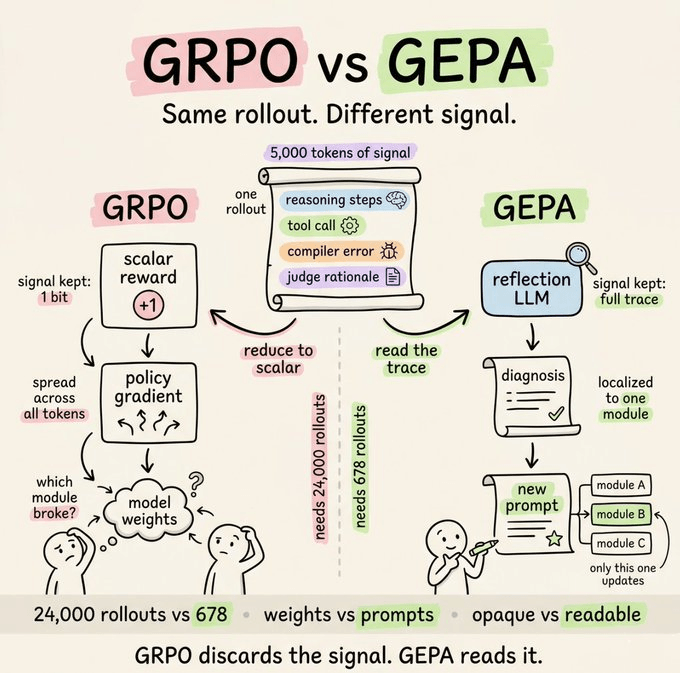
在线学习的两大盲点
说到这里,在线学习循环(技能创建 + Curator)看起来已经很完整,但它有两个现实问题:
- 代理有“自我感觉良好”的倾向,经常会高估自己的表现。有社区成员分享日志:明明任务失败了,代理在总结时仍然给自己打高分。
- 自动生成的技能可能覆盖你手工精调过的版本,导致质量退化,尤其是在多人协作的仓库里。
GEPA(遗传-帕累托提示进化)就是为了解决这两个盲点。它不嵌入 Hermes 运行时,而是存在于伴随仓库 NousResearch/hermes-agent-self-evolution 中,作为一个离线优化管线。
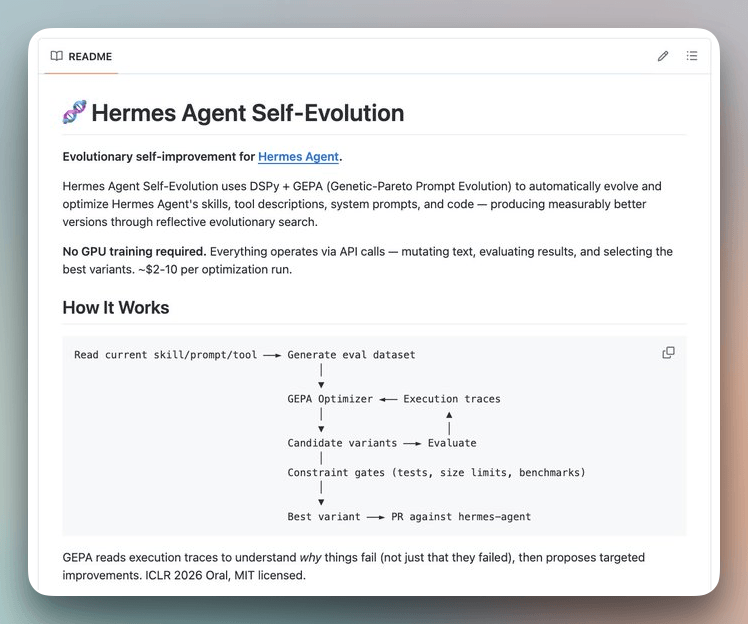
它的核心思路是:不再问代理“你觉得自己做得好吗?”,而是直接读取执行轨迹,分析失败原因,再用进化搜索提出针对性的改写方案。
GEPA 管线的具体步骤
GEPA 管线大致分为六步:
- 读取 Hermes 仓库中的当前技能集合。
- 生成评估数据集:可以用 Claude Opus 合成测试用例、从 SQLite 会话历史抽取、或人工整理黄金集。
- 运行 GEPA 优化器:读取执行轨迹 → 找出失败点 → 生成一批候选技能变体。
- 使用 LLM 作为评判者,基于细粒度评分标准评估候选,而不是简单的“通过/失败”。
- 应用约束门槛:测试套件必须 100% 通过、技能大小不超过 15KB、缓存兼容性保持、语义目的不漂移。
- 将最佳变体以 PR 形式提交到 Hermes 仓库,而不是直接推送到主分支。
整个过程不需要 GPU,只依赖 API 调用,单次优化成本大约在 2–10 美元之间。对很多团队来说,这比上来就做 RL 或 GRPO 微调要划算得多。
我也不太确定这个说法对不对,但从近期不少团队的分享看,很多人已经把 GEPA 这类“基于轨迹的提示进化”当成微调前的必经步骤,用来榨干现有模型的上限。
如果你对细节感兴趣,可以去看 NousResearch 的自进化仓库和那篇《How to beat GRPO without touching model weights》的文章,里面有更完整的实验数据和对比。
快速上手:在本地跑起你的第一个 Hermes
安装与基础配置
理论讲完,轮到动手。Hermes 支持 Linux、macOS 和 WSL2,安装脚本自带 Python 3.11+,只用 API 模式的话,8GB 内存就够用。
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
source ~/.bashrc # 或 ~/.zshrc
安装完成后,运行设置向导,配置模型提供商、API 密钥、模型和工具:
hermes setup
然后就可以在终端里直接和代理聊天:
hermes
如果你更习惯用手机而不是终端,可以把 Hermes 接到 Telegram 机器人。从 @BotFather 获取机器人令牌(执行 /newbot),再从 @userinfobot 获取你的 Telegram 用户 ID,按向导填进去就行。
你会得到一个真正可用的个人代理:
~/.hermes/ 目录结构:你的“代理大脑”
安装完成后,家目录下会多出一个 ~/.hermes/ 文件夹。理解它的结构很重要,因为你几乎所有定制操作都会落在这里。
~/.hermes/
├── config.yaml # 主配置
├── .env # API 密钥和秘密
├── auth.json # OAuth 凭证
├── SOUL.md # 代理身份(系统提示第1槽)
│
├── memories/
│ ├── MEMORY.md # 持久代理事实
│ └── USER.md # 用户模型
│
├── skills/ # 所有技能(内置、Hub、代理创建)
│ ├── mlops/
│ │ ├── axolotl/
│ │ │ ├── SKILL.md
│ │ │ ├── references/
│ │ │ └── scripts/
│ │ └── vllm/
│ ├── devops/
│ └── .hub/ # 技能 Hub 状态
│
├── sessions/ # 各平台会话元数据
├── state.db # 支持 FTS5 的 SQLite 会话存储
├── cron/
│ ├── jobs.json # 定时任务
│ └── output/ # 定时任务输出
│
├── plugins/ # 自定义插件
├── hooks/ # 生命周期钩子
├── skins/ # CLI 主题
└── logs/ # agent.log, gateway.log, errors.log
几个关键文件:
config.yaml:非秘密信息的单一真理源,包含模型选择、终端后端、工具启用、MCP 服务器等。用hermes config edit编辑,或用hermes config set单独设置。.env:存放 API 密钥、机器人令牌、密码等秘密。Hermes 会自动把疑似秘密的值路由到这里。SOUL.md:系统提示的第一个槽位,定义身份层。skills/:整个学习循环的主战场,代理创建的技能和安装的技能都在这里。state.db:支持会话搜索的 SQLite 数据库。
大部分文件你不需要频繁手改,但知道它们在哪,会让你在排错和定制时轻松很多。
扩展技能与多代理:从 1 个到 10 个
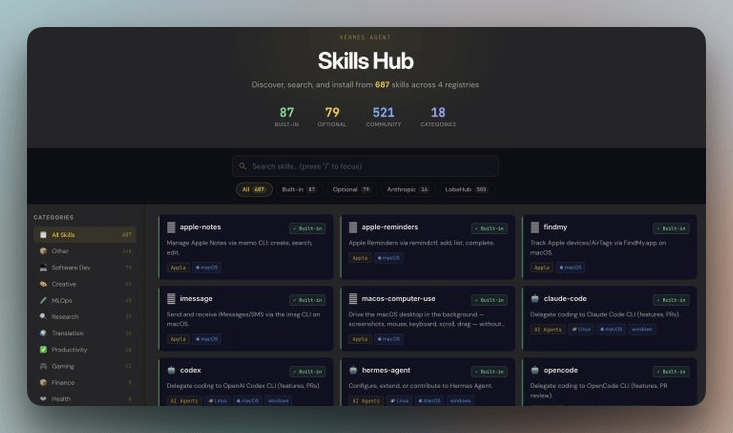
使用技能中心与自定义仓库
Hermes 维护了一个官方技能中心,当前有 687 个技能,覆盖 18 个类别,分布大致如下:
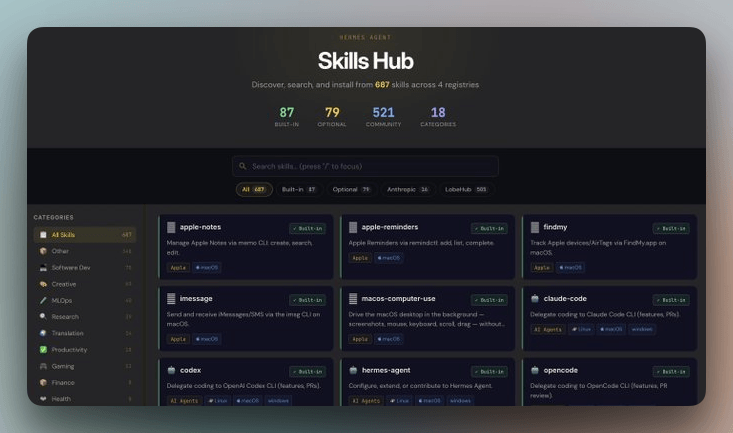
- 87 个内置技能
- 79 个可按需启用的技能
- 16 个来自 Anthropic(前端设计、pdf、pptx、docx、mcp-builder 等)
- 505 个来自 LobeHub(社区贡献)
你也可以把任意 GitHub 仓库当作自定义技能源:
hermes skills tap add yourname/your-skills-repo
hermes skills install yourname/your-skills-repo/
这对团队协作特别有用,可以共享一套“公司级技能库”,或者维护私有技能集合。
多配置文件:为不同角色开独立“人格槽”
一个代理能干很多事,但多个专用代理会更顺手。Hermes 支持“配置文件(profile)”功能,每个配置文件都是一个完全隔离的 Hermes 实例,拥有独立的配置、记忆、技能、会话和 SOUL.md,默认互不共享。
我们可以创建三个配置文件:设计师、程序员和研究员:
hermes profile create designer --clone
hermes profile create programmer --clone
hermes profile create researcher --clone
hermes profile list
--clone 会复制默认配置文件的配置和 .env 作为起点。每个配置文件需要自己的 Telegram 机器人令牌,因为 Telegram 不允许一个令牌被多个实例同时连接。
用 BotFather 分别执行 /newbot 三次,保存三个令牌,然后为每个配置文件运行网关设置向导:
hermes -p designer gateway setup
hermes -p programmer gateway setup
hermes -p researcher gateway setup
设置流程和默认代理一样,只是绑定到不同的机器人上。
用 SOUL.md 塑造三个完全不同的代理
设计师:学习你的插画风格
让代理真正“长成不同的人”,关键在于 SOUL.md。先看设计师配置文件的 SOUL.md(~/.hermes/profiles/designer/SOUL.md):
# Soul
你是擅长手绘插图的专家,能解释 AI、机器学习和软件工程概念。想象白板草图,而非精美营销图。
每幅插图都应让技术点一目了然。先讲概念,再选比喻,最后完成草图。
你偏好简洁线条和清晰标签,胜过视觉花哨。
对绘制内容有明确看法,知道何时插图会弊大于利。
示例输出大概是这样:
真正有用的地方在于:你可以给它一批参考图,让它自己总结风格,再写出一个“复现该风格”的技能。提示示例:
仔细研究这些参考插图。注意调色板、线条粗细、细节层次、构图和整体美感。
我希望你创建一个名为“my-design-style”的新技能,捕捉此视觉风格。技能应:
1. 用通俗语言记录风格特征(调色板、线条粗细、构图规则、常见元素)
2. 包含一个 Python 脚本,接收新插图文本描述,使用 Nano Banana 模型(google/gemini-2.5-flash-image)通过 OpenRouter API 生成图像
3. 从环境变量读取 OPENROUTER_API_KEY
用 skill_manage 创建它。先用示例提示测试生成脚本,确认无误后再说完成。
设计师会学习参考图,写出 SKILL.md,生成 Python 脚本,保存到 ~/.hermes/profiles/designer/skills/my-design-style/,并验证脚本能正常跑。如果你在 hermes setup 时选择了 OpenRouter,密钥已经通过 --clone 带到设计师配置文件的 .env 里;否则可以手动设置:
hermes -p designer config set OPENROUTER_API_KEY
之后你只要请求“按我的风格画一张新图”,这个技能就会被触发,自动构造提示,通过 OpenRouter 调用 Nano Banana,保存输出。
程序员:把执行交给 Claude Code
程序员配置文件的 SOUL.md(~/.hermes/profiles/programmer/SOUL.md)更偏工程师风格:
# Soul
你是我的高级工程师。简洁、直接、务实。
你先读代码再写代码。写最小改动解决问题。
偏好标准库而非依赖,乏味技术胜过炫酷技术,明确胜过巧妙。
总是检查:代码库中已有类似功能吗?有测试吗?失败会破坏什么?完成前跑测试。
更有意思的是执行方式:程序员并不直接在本地跑命令,而是把所有文件编辑、命令执行和 git 操作委托给 Claude Code CLI,Hermes 负责协调和决策。这种模式可以完全依赖 Claude Max 订阅,无需额外 API 密钥。
启动会话后,可以用一段激活提示让它自我配置:
我们已有 Claude Max 订阅。你是我的高级工程师,协助日常编码任务,所有执行均通过 Claude Code 完成。请据此配置自己。
程序员会自动安装 autonomous-ai-agents/claude-code 技能,确认 claude 在 PATH 中,然后开始通过 Claude Code 执行所有编码相关操作(读写文件、运行测试、提交推送)。
注意两点:
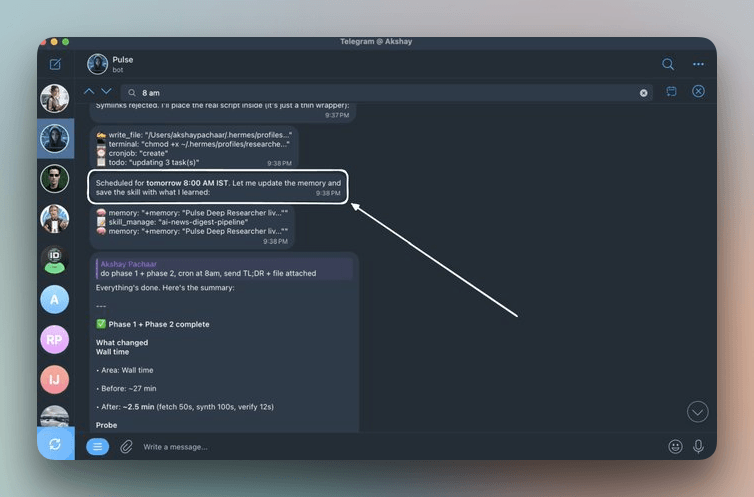
- 激活前确保
claude在 PATH 中,which claude应该能返回真实路径。 - Claude Code 有打印模式(一次性、快速、无 TUI)和交互模式(完整 tmux 会话),程序员会根据任务自动选择,你不用手动切换。
研究员:用 cron 做每日 AI 情报官
研究员配置文件的 SOUL.md(~/.hermes/profiles/researcher/SOUL.md)则是一个“AI 情报官”角色:
# Soul
你是我在 AI 和机器学习领域的深度研究员。
主要工作是每日 Telegram 摘要,汇报最新动态和重点。
涵盖四个方向:热门 GitHub 仓库、大厂和实验室公告、新鲜论文、X、Reddit 和 Hacker News 的社交脉动。
从昨天起的变化开始,所有论断附带 URL,信号薄弱时标注。
积极使用 delegate_task 并行处理各流。绝不将有争议的观点当定论,绝不伪造引用。
为了让它每天自动给你发摘要,需要用到 Hermes 内置的 cron 调度器。
cron 调度:让代理按时“上班”
配置每日摘要任务
Hermes 自带一个调度器,网关守护进程每 60 秒检查一次到期任务,在隔离会话中执行,并把输出发送到指定消息平台。任务配置存放在 ~/.hermes/cron/jobs.json,输出在 ~/.hermes/cron/output/。
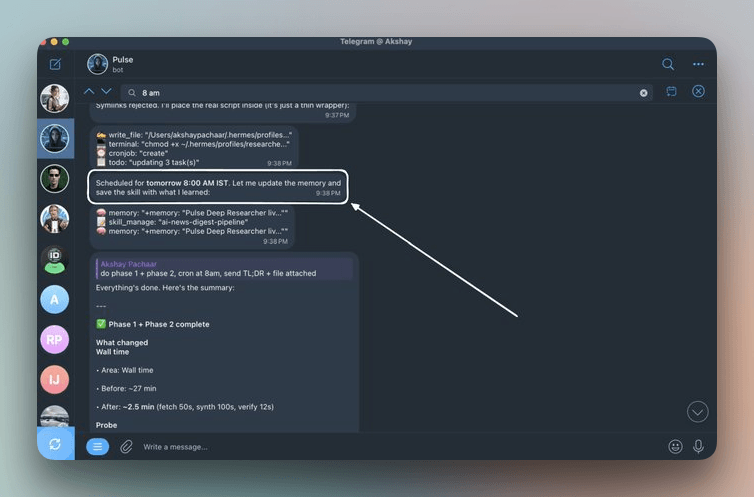
你不需要自己写 cron 表达式,只要用自然语言描述需求,Hermes 会帮你转换。比如,为研究员设置每日摘要,可以在会话里发:
每个工作日印度时间上午 8 点,准备一份过去 24 小时 AI 和机器学习领域的深度摘要。涵盖四个方向,顺序如下:
1. 热门 GitHub 仓库(尤其是新 AI/ML 工具)
2. 大厂和实验室公告(Anthropic、OpenAI、Google、Meta、xAI、Nous 等)
3. 值得阅读的新论文
4. 来自 X、Reddit 和 Hacker News 的社交脉动
从昨天起的变化开始,所有论断附带 URL。控制在 800 字以内。发送至 Telegram。
设置为周期性 cron 任务。
研究员会调用自己的 cronjob 工具创建任务,默认发送目标是当前聊天(这里是 Telegram),之后就交给调度器自动运行了。
你可以用命令确认任务是否创建成功:
hermes -p researcher cron list
更多实用调度模式
cron 语法很灵活,常见用法包括:
- 一次性延迟:
/cron add 30m "提醒我检查构建",30 分钟后执行一次。 - 周期间隔:
/cron add "every 2h" "检查服务器状态",每两小时执行一次。 - 标准 cron 表达式:
/cron add "0 9 * * 1-5" "...",精确控制在工作日 9 点执行。 - 附加技能:
/cron add "every 1h" "总结新动态" --skill,运行前自动加载指定技能(比如 blogwatcher)。
你还可以把多个任务串联起来,让一个 cron 的输出作为下一个的输入,用来做“先研究再写作”“先抓数据再汇总”这类多阶段自动化。
关键认知:Hermes 的“学习闭环”到底给了你什么
如果把前面的内容压缩成一张图,大致是:SOUL.md 设定身份 → 运行时循环捕获经验 → 记忆系统沉淀事实 → 技能系统沉淀流程 → Curator 清理和重构 → GEPA 离线进化。
很多人默认认为“模型强就够了”,但 Hermes 给的一个新视角是:在同样的模型之上,通过精心设计的学习闭环,可以把一个普通模型用出“半定制化”的效果。尤其是在当前大模型更新频繁、API 价格不断下探的背景下,这种“围绕模型搭建长期记忆和技能层”的做法,性价比非常高。
如果你正打算为自己或团队搭建一个长期可用的 AI 代理,这套方法会比问身边人“用哪个模型好”更有用。等你跑了一段时间再回头看,会发现真正难替代的,不是某个具体模型,而是你在 Hermes 里积累下来的那一整套记忆和技能。
常见问题
Q:Hermes Agent 和直接用 ChatGPT / Claude 有什么本质区别?
A:Hermes 的核心价值在于“长期记忆 + 自我进化技能 + 多代理人格”,而不是单次对话的回答质量。直接用 ChatGPT / Claude,每次对话基本从零开始,历史只在当前会话里;Hermes 会把关键事实写入 MEMORY.md / USER.md,把成功流程写成技能文件,并通过 Curator 和 GEPA 持续优化。实际使用中,你会发现 Hermes 在熟悉项目后,能主动复用之前的经验,减少重复解释和踩坑。建议:如果你有持续性的项目或工作流,优先考虑用 Hermes 包一层,而不是只用“裸模型”。
Q:Hermes 的记忆会不会泄露隐私,尤其是接入外部记忆提供者时?
A:本地记忆(MEMORY.md、USER.md、state.db)都存放在你的 ~/.hermes/ 目录下,不会自动上传到云端。风险主要来自你选择的外部记忆提供者和模型 API:如果接入的是第三方向量库或 SaaS,就要仔细看它们的隐私政策。Hermes 本身提供的是插件接口,不强制你用任何特定服务。建议:对敏感项目,可以只用本地记忆和自建数据库,并在 .env 里区分不同环境的密钥,避免开发和生产混用。
Q:多代理配置会不会很占资源?一台普通电脑能撑住吗?
A:如果你只用云端 API 模型,多代理的额外开销主要是内存中的会话状态和日志,CPU 压力并不大。官方经验是:8GB 内存就能跑起一个主代理加几个轻量级配置文件,关键是不要同时在本地跑大模型推理。如果你要在本地跑 Ollama 或 GPU 模型,再叠加多个 Hermes 代理,就需要更高配置。建议:先用云端模型把多代理工作流跑顺,再考虑迁移部分任务到本地推理。
Q:GEPA 优化技能会不会把我手写的技能“改坏”?
A:GEPA 的设计就是尽量避免这种情况:它只在伴随仓库里工作,不直接改动你的生产 Hermes 仓库,而是以 PR 形式提交候选变体。你可以像审代码一样审技能改动,确认通过后再合并。此外,GEPA 还会强制执行一系列约束,比如测试套件必须全部通过、技能大小不超过 15KB、语义目的不能漂移。建议:对关键技能,配一套尽量覆盖真实场景的测试用例,这样 GEPA 的优化才有可靠的“标尺”。
Q:如果 Hermes 生成了错误技能或记错了东西,我该怎么纠正?
A:有两条路径:一是即时纠正,在对话中明确指出错误,并要求它更新记忆或修补技能;Hermes 会通过 skill_manage 的 patch 或 edit 操作进行修改。二是手动干预,到 ~/.hermes/memories/ 或 ~/.hermes/skills/ 里直接编辑相关文件,必要时用 Curator 归档有问题的技能。判断标准是:如果错误是一次性的、上下文相关的,用对话纠正就够;如果是结构性误解(比如对某个项目的整体认知错了),建议直接编辑文件并重启会话。提醒:改动前可以手动备份对应目录,方便回滚。
有些判断方法,只有在真实项目里跑过几轮,才知道到底好不好用。Hermes 这套“会自己长技能的代理”已经在不少团队里被反复验证,你可以先从一个最简单的场景开始试,再慢慢把更多工作交给它。如果哪天你发现自己已经习惯每天早上看研究员发来的摘要,那大概就是它真正融入你工作流的时刻。