99% 的团队一提到「AI 客服」,脑子里只有网站角落里的那个小聊天框。真正在省钱省力的,其实是把 DeepSeek 嵌进整个客服工作流:自动分单、结构化标注、草拟回复、识别情绪和风险,再把复杂问题稳稳交给人工。只要你有工单系统、知识库、CRM,再配上清晰的升级规则,就能把 DeepSeek 变成一名靠谱的「AI 客服助理」,而不是一个失控的机器人。
据一些 SaaS 和电商团队反馈,引入大模型做客服后,常见问题的自动解决率能提升到 30%–50%,人工分单时间减少一半以上。我自己帮一个订阅制产品搭过类似方案,前两周就把夜间值班的压力降了不少,但也踩过「知识库太乱」「隐私没评估」这些坑。下面这份指南,会从架构、API 特性到 30-60-90 天落地计划,帮你少走弯路。
什么是 DeepSeek 客服自动化?
DeepSeek 在客服里的真实角色
DeepSeek 客服自动化,说白了就是把 DeepSeek 模型嵌入客服流程,让它替人完成重复、可标准化的工作:回答 FAQ、给工单打标签、起草回复、总结对话、识别情绪、路由紧急问题、把复杂案例升级给人工。它不是一个孤零零的聊天机器人,而是你现有客服系统里的「语言大脑」。
一个成熟的 DeepSeek 客服自动化方案,通常会覆盖这些场景:
- 回答高频、规则清晰的客户问题
- 按主题、紧急程度、语言、情绪给工单分类
- 为客服预写回复草稿,人工一键修改发送
- 在升级前自动总结长对话,减少人工翻阅
- 识别退款风险、流失信号、辱骂投诉和 SLA 风险
- 把工单路由到合适的团队或队列
- 从知识库中检索合规答案,而不是「瞎编」
- 通过 Tool Calls 或中间件触发后端查询或操作
更强的用法不是「替代所有客服」,而是让 DeepSeek 先处理低风险、重复性高的部分,再把情绪复杂、金额高、涉及合规的对话交给人类。这样既能控风险,又能把人力用在真正值钱的地方。
DeepSeek API 与模型概览
DeepSeek 当前的 API 文档列出了 deepseek-v4-flash 和 deepseek-v4-pro 两个主力模型,支持 OpenAI 和 Anthropic 兼容格式,还提供 JSON Output、Tool Calls、上下文缓存(KV Cache)、思考/非思考模式,以及最长 1M 的上下文长度。对客服来说,这些特性非常关键:
- 兼容主流 API 格式,方便接入现有中台或 AI 编排工具
- JSON 输出,便于做结构化工单分类和路由
- Tool Calls,可以安全地「请求」后端操作,而不是直接改数据
- 上下文缓存,让重复的系统提示、品牌语气、政策说明更省钱
- 1M 上下文,足够塞进长对话、历史工单和多篇知识库内容
有用户反馈,在同样的工单量下,用带缓存的长上下文模型,比传统 FAQ 机器人减少了约 40% 的「答非所问」情况,但前提是知识库结构要干净。
为什么越来越多团队考虑用 DeepSeek 做客服?
现代客服团队的压力点
很多客服团队都遇到同一个矛盾:工单量涨得飞快,预算和人手却很难同步增加。招聘、培训一个合格客服往往要 1–3 个月,而且流失率还不低。AI 客服自动化的吸引力,就在于它能先接住那一大堆「重复问同一个问题」的工单,帮你把人工从机械劳动里解放出来。
DeepSeek 对那些已经在用 OpenAI、Anthropic 或自建 AI 中台的团队尤其友好。官方文档明确说明,DeepSeek API 支持 OpenAI 风格和 Anthropic 风格的调用格式,这意味着很多现成的聊天机器人平台、内部工具、编排服务,只需要改一下 base URL 和模型名,就能快速接入 DeepSeek。
从功能上看,DeepSeek 模型页列出的 1M 上下文、JSON 输出、Tool Calls 和上下文缓存,对客服场景都很实用。客服对话往往需要:反复引用系统指令、调用知识库、读取订单或 CRM 数据,还要输出结构化字段给工单系统使用,这些都离不开这些能力。
典型收益:不仅是「省人」,更是「提质」
很多团队看上 DeepSeek 的原因,其实很务实:
- 减少人工分单和标签工作
- 提高首响速度,缩短平均处理时长
- 让新人客服也能写出「像老员工」一样的回复
- 在升级前自动总结上下文,节省资深客服时间
- 更早识别情绪爆炸、潜在投诉或差评风险
有团队在试点阶段就发现,AI 参与后的工单,二次打开率(reopen)下降了约 15%,因为回复更完整、上下文更连贯。当然,也有人踩坑,比如一开始就让 AI 直接处理退款和投诉,结果被客户投诉「机器人乱承诺」。这也是为什么要从低风险场景起步。
DeepSeek 在现代客服技术栈中的位置
DeepSeek 不该是「唯一决策者」
在一个健康的客服架构里,DeepSeek 应该是语言理解和生成层,而不是「一切由它说了算」。尤其是涉及资金、法律、账号安全的场景,AI 只能给建议,不能直接做决定。
一个相对稳妥的客服技术栈,大致长这样:
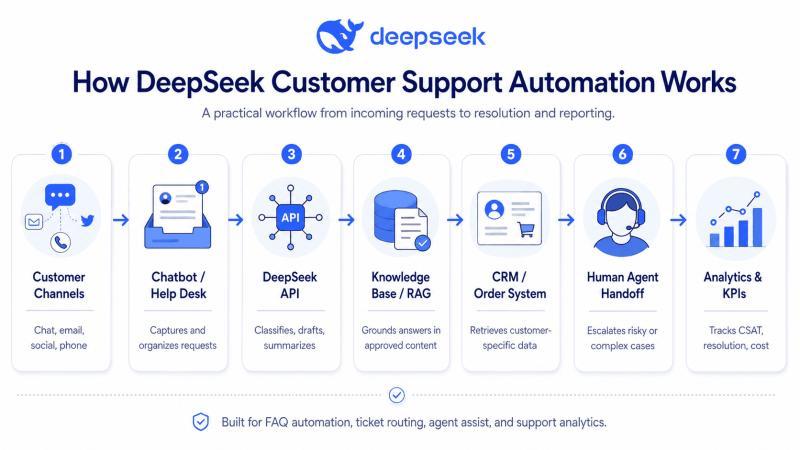
Customer Channel
↓
Website Chat / Email / Social DM / Help Desk
↓
Automation Layer
↓
DeepSeek API
↓
Knowledge Base / RAG System
↓
CRM / Order System / Subscription Platform
↓
Human Agent Handoff
↓
Analytics, QA, CSAT, and KPI Reporting
在这套架构里:
- DeepSeek 负责理解客户话语、生成回复或结构化结果
- 客服平台负责身份、工单历史、权限、会话状态和坐席工作流
- RAG 系统从帮助中心、政策文档、内部手册、版本说明中检索内容
- CRM / 订单系统提供客户级别的事实信息
最重要的一条规则:DeepSeek 只能基于「已批准的内容」回答问题,一旦信心不足或涉及高风险,就必须升级给人工。
DeepSeek 最适合的客服用例
DeepSeek 在客服里的最佳用法,是那些重复性高、可量化、易于人工复核的任务。可以优先考虑:
- FAQ 自动回复(如物流进度、发票开具、基础功能说明)
- 工单分类与打标签(主题、优先级、语言、情绪)
- 回复草稿生成(由人工快速审核后发送)
- 对话总结(用于升级或跨班次交接)
- 情绪与风险识别(退款倾向、辱骂、投诉预警)
不太建议一上来就让 DeepSeek 独立处理退款、销户、合规投诉、法律威胁或高价值大客户决策。这些场景更适合「AI 辅助 + 人工决策」。
DeepSeek API 中对客服最关键的能力
OpenAI / Anthropic 兼容格式:少踩集成坑
DeepSeek API 文档说明,提供 OpenAI 风格和 Anthropic 风格的 base URL,并支持 deepseek-v4-flash 和 deepseek-v4-pro。对客服自动化来说,这意味着:
- 很多现成的聊天机器人平台、内部工具已经支持这两种格式
- 迁移或并行测试 DeepSeek 时,改动量相对可控
- 可以在同一编排层里对比不同模型的表现
有团队的做法是:在现有 OpenAI 流程里,增加一个「AB 测试」开关,把一部分工单流量切给 DeepSeek,比较分类准确率、回复质量和成本,再决定是否扩大使用范围。
模型选择与能力边界
根据官方定价页,目前主要模型包括:
- DeepSeek-V4-Flash:偏高性价比、适合大规模自动化
- DeepSeek-V4-Pro:更强推理能力,适合复杂场景和高价值工单
同一页面还提到:1M 上下文、最大输出 384K、支持 JSON Output、Tool Calls、Chat Prefix Completion beta、FIM Completion beta(非思考模式)。另外,deepseek-chat 和 deepseek-reasoner 计划在 2026 年 7 月 24 日退役,并映射到 deepseek-v4-flash 的不同模式。
对客服团队来说,一个常见策略是:
- 大部分 FAQ、标签、情绪识别用 Flash
- 涉及复杂政策、跨系统排查、长对话总结时切到 Pro
JSON Output:让工单系统「听得懂」AI
DeepSeek 的 JSON Output 能力,支持返回严格的 JSON 字符串。官方建议:
- 在
response_format中设置{"type": "json_object"} - 在提示词中明确写出「json」和示例格式
- 合理设置
max_tokens,避免输出被截断
在客服场景里,JSON 输出特别适合:
- 工单意图(intent)识别
- 优先级(priority)和情绪(sentiment)打分
- 语言识别(language)
- 是否需要升级(escalation_required)
- 置信度(confidence_score)
- 推荐动作(recommended_action)和内部摘要(internal_summary)
有了这些字段,工单系统就能自动打标签、分配队列、触发 SLA 规则,甚至给客服展示「推荐下一步」。
Tool Calls:安全地「请求」而不是「执行」
DeepSeek 的 Tool Calls 允许模型发起函数调用请求,但真正的函数执行是在你自己的应用里完成。这一点非常关键:
- 模型只能说「我想调用
lookup_order_status」 - 后端会检查权限、参数、风控,再决定是否执行
在客服自动化里,一个安全的做法是:
- 允许模型调用:查询订单、查退款政策、创建升级工单等
- 禁止模型直接:发起退款、关闭账号、修改订阅等
这样既能提高自动化程度,又不会让 AI 直接「动真金白银」。
上下文缓存:让重复提示更省钱
官方说明 DeepSeek 默认开启 Context Caching,如果后续请求与之前的前缀重叠,就可能命中缓存、按更低价格计费。客服场景里,大量提示词是重复的,比如:
- 品牌语气和写作风格
- 安全与隐私规则
- 升级和合规要求
- 常用政策说明
通过把这些内容放在固定前缀里,并复用同一缓存 ID,可以在不牺牲效果的前提下,显著降低调用成本。
思考模式与非思考模式:别全程「开大招」
DeepSeek 文档中提到的思考模式,会在给出最终答案前生成一段推理内容,并支持调节推理强度。默认是开启的,但客服场景不必所有请求都用高推理:
- FAQ 回答、简单标签:用非思考模式即可
- 复杂政策冲突、多步骤排查、跨系统问题:可以开启思考模式
我也不太确定这个经验对所有团队都适用,但从一些试点数据看,「简单任务用轻量模式 + 复杂任务用高推理模式」的组合,在成本和质量之间的平衡还不错。
DeepSeek 客服自动化落地步骤
1. 审核历史工单:先看清「问题长什么样」
可以先抽样 500–2000 条历史工单,按主题、复杂度、渠道、解决方式和风险等级做个粗分类。重点观察:
- 重复率最高的问题有哪些
- 低风险、高频的场景有哪些
- 哪些工单几乎每次都用同一套政策回答
- 哪些工单需要查后端系统才能解决
- 哪些类型经常被升级
- 哪些工单里,客服花了很多时间在「整理上下文」而不是解决问题
这一步会直接决定你后面选哪些用例做试点。
2. 选择首批自动化用例
不要一口吃成胖子,先挑两三个用例做 MVP:
- FAQ 自动回复
- 工单分类与打标签
- 回复草稿生成
- 对话总结
- 情绪与紧急程度识别
可以暂时避开这些高风险场景:退款、销户、合规投诉、安全问题、法律威胁、大客户争议等。先把「不会出大事」的部分跑顺,再逐步扩展。
3. 清洗并结构化知识库
说句扎心的:AI 客服答错很多时候不是模型的问题,而是知识库太乱。一个 DeepSeek 客服机器人,可靠程度基本等于它能用到的信息质量。
建议整理这些内容:
- 帮助中心文章
- 退款与退货政策
- 物流与发货规则
- 故障排查指南
- 账号开通与设置步骤
- 价格与计费规则
- 升级与投诉处理规则
- 常用客服宏(Macros)
- 产品更新与版本说明
可以做几件小事:删掉过期内容、合并重复政策、给每篇文档加「最近更新时间」。如果源头是乱的,AI 再聪明也只能「乱中取一」。
4. 设计意图体系与升级规则
先定义一套清晰的意图(Intent)分类,比如:
billing_questiontechnical_issuerefund_requestorder_statusaccount_accesssubscription_cancellationbug_reportfeature_requestlegal_or_privacy_requesthuman_agent_request
然后在上线前就把升级规则写死,而不是边跑边想:
- 置信度低于 0.75 就升级
- 客户明确要求人工就升级
- 提到法律行动、监管投诉就升级
- 涉及支付、身份、健康、儿童或敏感个人信息就升级
- 高价值客户 + 明显愤怒情绪就升级
这些规则既可以写在提示词里,也可以写在你自己的业务逻辑里,双重保险。
5. 设计提示词与 JSON Schema
不同任务用不同提示词,不要指望一个提示词又分类、又总结、又回答、又触发工具,除非你已经做过大量测试。一个常见的工作流是:
- 分类提示词:识别意图、优先级、情绪等
- RAG 检索:从知识库拉出相关内容
- 回复生成提示词:基于检索结果起草回复
- 安全与政策检查:过滤违规承诺或敏感内容
- 决策:自动回复 or 升级人工
在 JSON Schema 里,把你需要的字段都定义清楚,比如 intent、priority、sentiment、escalation_required、confidence_score 等,方便后端解析。
6. 把 DeepSeek 接入工单系统和 CRM
通常会通过后端服务、中间件或自动化平台调用 DeepSeek API,常见对接对象包括:
- Zendesk
- Freshdesk
- Intercom
- Help Scout
- Gorgias
- Salesforce Service Cloud
- HubSpot Service Hub
- 内部运营后台
- 电商订单系统
- 订阅计费平台
有的平台可能暂时没有「DeepSeek 原生集成」,但只要支持 HTTP 请求、Webhook 或自定义 API 调用,就能接入。不要在对外宣传里写「原生集成」,除非你真的验证过。
7. 设计顺滑的人工接管体验
人工接管不是「兜底补丁」,而是产品体验的一部分。一个好的接管流程,至少要把这些信息带给人工客服:
- 客户问题摘要
- 检测到的意图
- 情绪和紧急程度
- 已尝试过的步骤
- 使用过的知识库来源
- 推荐下一步动作
- 风险标记(如退款、投诉、合规)
- 完整对话链接
这样人工接手时,不用从头翻聊天记录,效率和体验都会好很多。
8. 用历史工单做离线测试
在正式上线前,可以用历史工单做一轮「离线评估」:
- 分类准确率
- 升级判断准确率
- 回答正确率
- 政策合规度
- 幻觉(乱编)比例
- 不安全自动化尝试次数
- 人工审核平均节省时间
有团队会让资深客服抽样评估 AI 输出,给每条打「可直接发送 / 需修改 / 严重错误」三档评分,用来调整提示词和阈值。
9. 小范围试点上线
可以先选一个渠道、一个队列或一个主题做试点,比如:
- 只自动处理订单状态查询
- 只自动处理密码重置相关问题
试点阶段,所有对客户可见的回复都先经过人工审核。这样既能收集真实数据,又不会把风险暴露给终端用户。
10. 持续度量与迭代
上线后,用真实生产数据不断优化:
- 调整提示词和 JSON Schema
- 补充知识库盲区
- 优化路由和升级阈值
- 对比 AI 辅助工单与纯人工工单的表现
有团队会每周开一次「AI 复盘会」,挑出典型好案例和坏案例,和客服一起讨论怎么改提示词和规则,这种做法很有价值。
实用提示词示例:可直接改造使用
工单分类提示词
System:
You are a customer support classification assistant. Classify the ticket using only the provided message and context. Return valid JSON only.
User:
Classify this support ticket.
Customer message:
"""
{customer_message}
"""
Allowed intents:
billing_question, technical_issue, refund_request, order_status, account_access, subscription_cancellation, bug_report, feature_request, legal_or_privacy_request, human_agent_request, other
Return JSON with:
intent, priority, sentiment, customer_language, summary, escalation_required, confidence_score
Rules:
- Set escalation_required to true if the customer asks for a human, mentions legal action, reports account compromise, shares sensitive personal data, or expresses severe frustration.
- Do not invent facts.
- Confidence score must be between 0 and 1.
情绪分析提示词
System:
You analyze customer sentiment for support prioritization. Return valid JSON only.
User:
Analyze the sentiment of this customer message:
"""
{customer_message}
"""
Return:
{
"sentiment": "angry | frustrated | neutral | positive | confused",
"urgency": "low | medium | high",
"risk_flags": [],
"reason": "short explanation"
}
客户回复草稿提示词
System:
You are a customer support reply assistant. Draft a helpful, concise reply for a human agent to review before sending.
Rules:
- Use only the provided knowledge base context.
- Do not promise refunds, discounts, compensation, timelines, or account changes unless the policy explicitly allows it.
- If the answer is not in the context, say that the agent should investigate.
- Keep the tone warm, clear, and professional.
Customer message:
"""
{customer_message}
"""
Knowledge base context:
"""
{retrieved_context}
"""
Draft the reply.
升级检测提示词
System:
You detect whether a customer support conversation should be escalated to a human. Return valid JSON only.
Conversation:
"""
{conversation_transcript}
"""
Escalation triggers:
- legal threat
- safety issue
- payment dispute
- account compromise
- privacy request
- angry VIP customer
- repeated failed resolution
- refund request outside standard policy
- customer asks for a human
Return:
{
"escalation_required": true/false,
"escalation_reason": "",
"recommended_team": "",
"confidence_score": 0.0
}
知识库回答提示词
System:
You answer customer questions using only approved knowledge base content.
Rules:
- Answer only from the provided context.
- If the answer is missing, say: "I do not have enough information to answer that accurately."
- Do not invent policies.
- Include the source article title used for the answer.
- Keep the answer short and customer-friendly.
Customer question:
"""
{customer_question}
"""
Approved context:
"""
{retrieved_knowledge_base_articles}
"""
JSON 输出示例:工单路由
{
"intent": "refund_request",
"priority": "medium",
"sentiment": "frustrated",
"customer_language": "en",
"summary": "Customer is requesting a refund after receiving a damaged product.",
"recommended_action": "Check order details, confirm refund eligibility, and route to ecommerce support team.",
"escalation_required": true,
"escalation_reason": "Refund request involving product damage and customer frustration.",
"confidence_score": 0.87
}
有了这样的结构,你的工单系统就能自动打标签、设置优先级、触发工作流、通知对应团队,或者在坐席界面里展示「推荐处理方案」。
无代码 / 低代码集成思路
不想一上来就搭完整后端,也可以用无代码或低代码工具先做验证。常见做法包括:
- 用自动化平台(如 Make.com、Zapier 类工具)监听新工单或新消息
- 通过 HTTP 请求节点调用 DeepSeek API
- 把 JSON 结果写回工单系统的自定义字段
- 在客服界面里用备注或侧边栏展示 AI 建议
有些聊天机器人平台(如 Manychat 等)也支持自定义 API 调用,可以用来做简单的 FAQ 自动回复。不过每个平台的能力差异很大,上线前要自己验证,而不是想当然地认为「都能接」。
DeepSeek vs 传统客服机器人
传统规则型机器人,更多是「关键词 + 流程图」:
- 优点:可控、可预期、合规风险相对可管理
- 缺点:理解能力弱,一旦超出预设流程就崩
DeepSeek 这类大模型驱动的客服机器人,优势在于:
- 能理解自然语言、模糊表达和长句抱怨
- 可以在一个回复里综合多条信息
- 支持结构化输出,方便和现有系统联动
但风险也更现实:如果不做 RAG、不设置信心阈值、不做人审,模型可能会「一本正经地胡说八道」。所以更好的姿势,是把 DeepSeek 当成「自动化层」,叠加在现有客服软件之上,而不是替代一切。
成本规划与 ROI 估算
DeepSeek 官方定价页按每 1M Token 计费。以当前文档为例:
deepseek-v4-flash:缓存命中输入约 $0.0028 / 1M Token,缓存未命中输入约 $0.14 / 1M Token,输出约 $0.28 / 1M Tokendeepseek-v4-pro:截至 2026 年 5 月 31 日有折扣,缓存命中输入约 $0.003625 / 1M Token,缓存未命中输入约 $0.435 / 1M Token,输出约 $0.87 / 1M Token
价格可能调整,上线前务必再查一次官方定价页。估算 ROI 时,可以先算「每条自动化或辅助工单的成本」。关键变量包括:
- 每条工单平均输入 Token 数
- 每条回复平均输出 Token 数
- 每条工单调用分类模型的次数
- 每条工单调用 RAG 的次数
- 是否大量命中缓存
- 选择的模型类型
- 完全自动化的工单占比
- 仅 AI 辅助(仍由人工发送)的工单占比
- 中间件、工单系统和 QA 审核的额外成本
一个简单的月度节省公式:
Monthly savings = automated tickets × average handling cost − AI/tooling cost
例如:
Automated tickets per month: 20,000
Average manual handling cost: $2.50
AI/tooling cost: $6,000
Monthly savings = 20,000 × $2.50 − $6,000
Monthly savings = $44,000
这个公式只算了钱,还没算体验。更完整的评估还要看:客户满意度(CSAT)、工单重开率、升级质量、错误回答率等。如果省了钱却把口碑搞砸,那就得不偿失。
安全、隐私与合规:上线前必须过的一关
客服数据往往包含大量个人信息:姓名、邮箱、电话、地址、账单问题、截图、订单号,甚至可能涉及健康、法律投诉或账号安全细节。DeepSeek 的隐私政策中提到:
- 服务并非为处理「敏感个人数据」而设计或打算使用
- 建议用户不要提供敏感个人数据
- 个人数据可能会在政策所述目的下被保留
- 数据可能在中华人民共和国境内被收集、处理和存储
这并不意味着所有公司都不能用 DeepSeek,而是说明:在把客服数据发给任何 AI 提供商之前,都应该让法务、安全和合规团队参与评估。
可以用下面这份小清单做自查:
- 在发送给模型前,尽量脱敏或去掉不必要的 PII
- 避免发送敏感个人数据(如健康、宗教、政治等)
- 明确数据保留策略和删除机制
- 使用基于角色的访问控制(RBAC)
- 记录 AI 的关键决策和操作日志
- 区分「草稿生成」和「最终发送」,高风险场景必须人工审核
- 不要把密码、银行卡号、证件照、详细病历等发给模型
- 评估 GDPR、CCPA 等地区法规以及行业监管要求
- 写清楚「哪些数据、为什么要发给模型」,并形成文档
有一位朋友在金融行业做客服自动化项目,前期花了整整一个月只做数据流梳理和合规评审,虽然进度慢,但后面上线时几乎没被法务「打回重做」,长远看反而省了时间。
如何降低 DeepSeek 客服机器人的「幻觉」风险
1. 用 RAG 连接「已批准」的内容源
把 DeepSeek 接到一个只包含已审核内容的检索系统:
- 帮助中心文章
- 正式政策文档
- 产品说明书和内部 FAQ
模型只能基于检索到的内容回答问题,减少「凭空编造」。
2. 在提示词里明确告诉模型「不要做什么」
可以在系统提示词里写得很直白:
Do not invent policies.
Do not promise refunds unless the policy says so.
Do not provide legal, medical, or financial advice.
If the answer is not in the provided context, escalate to a human.
这种「负向约束」比泛泛而谈的「请谨慎回答」有效得多。
3. 要求结构化输出
对分类、路由、升级判断等任务,尽量使用 JSON Output。结构化输出能让你在后端做更多校验,比如:
- 置信度低于某值就强制升级
- 情绪为「angry」且金额高就打特殊标记
4. 设置置信度阈值
可以在业务逻辑里写类似规则:
If confidence_score < 0.75, do not send an automatic answer. Route to a human agent.
阈值可以根据历史评估结果调整,不同业务线也可以用不同阈值。
5. 关键场景保留人工参与
对高风险类别(退款、合规、账号安全、大客户等),让 DeepSeek 只做「助手」:
- 帮忙总结对话
- 提供政策引用
- 起草回复草稿
最终发送和决策由人工完成。
6. 持续监控真实对话
每周抽样检查 AI 参与的对话,关注:
- 明显错误或幻觉回答
- 不该自动化却被自动化的场景
- 客户投诉和差评
- 客服对 AI 建议的覆盖或修改情况
7. 持续更新知识库
很多 AI 错误,其实是内容错误。产品改版、政策调整后,如果知识库没及时更新,AI 只能继续用旧规则回答。可以把「知识库更新」当成客服运营的固定动作,而不是一次性项目。
如何衡量 DeepSeek 客服自动化的成效
不要只盯着「工单拦截率」。一个健康的 DeepSeek 客服方案,应该在速度和成本提升的同时,保持甚至提升体验。可以重点跟踪:
- 首次响应时间(FRT)
- 平均处理时长(AHT)
- 工单重开率(Reopen Rate)
- 客户满意度(CSAT / NPS)
- 升级率和升级质量
- AI 回答错误率和严重错误数量
有团队会把「AI 参与工单」单独拉出来做对比,看它们在 CSAT 和重开率上的表现,避免只看「省了多少人力」。
常见踩坑:提前避一避
自动化范围铺得太大太快
一上来就想「全自动」,很容易翻车。更稳的做法是:
- 先从低风险、高频场景开始
- 先做「AI 辅助 + 人工审核」,再逐步放开自动发送
- 高风险场景永远保留人工决策权
没有清晰的人工接管路径
没有人工接管的机器人,很容易把客户逼疯。客户应该随时能看到「联系人工」的选项,而不是被迫在机器人那儿兜圈子。
知识库质量差
DeepSeek 再强,也没法从「缺失、过期、互相矛盾」的政策里给出完美答案。知识库建设是 AI 客服的地基,偷懒迟早要补课。
忽视隐私与合规评审
客服数据往往涉及隐私和合规,一旦出问题,代价很大。上线前就把数据流、存储位置、访问权限、第三方处理方都梳理清楚,比事后补救靠谱得多。
提示词太模糊
比如:
Answer the customer.
这种提示词几乎等于没写。更好的写法是:
Answer using only the approved knowledge base. If the answer is missing, escalate to a human. Do not invent policies or make promises.
没有置信度阈值
如果不设置信心阈值,模型在「半懂不懂」时也会硬给答案。加一个简单的阈值判断,就能挡掉很多潜在事故。
只看拦截率,不看质量
只追求「AI 接住了多少工单」,很容易把团队带偏。更有价值的问题是:「这些被 AI 接住的工单,客户满意吗?有没有被迫再来一次?」
30-60-90 天落地路线图
前 30 天:审计与试点设计
重点工作:
- 审核历史工单,识别高频场景
- 选出 2–3 个首批自动化用例
- 清洗和重构知识库
- 设计意图体系和升级规则
- 选定模型和集成方式
- 写出首版提示词
- 定义成功指标和监控方式
阶段产出:
- 工单分类与意图体系
- 试点工作流图
- 知识库清理清单
- 提示词与 JSON Schema 库
- 隐私与合规检查清单
- KPI 基线数据
第 31–60 天:搭建、测试与小范围内测
重点工作:
- 在测试环境接入 DeepSeek
- 实现 JSON 格式的工单分类
- 接通 RAG 或已批准的帮助中心检索
- 测试回复草稿生成
- 用历史工单做离线评估
- 加入人工接管流程
- 在内部小范围上线,由客服审核 AI 输出
阶段产出:
- 可运行的原型系统
- 测试与评估报告
- 路由与升级 Schema
- 升级工作流文档
- 客服团队反馈报告
- 调整后的提示词与规则
第 61–90 天:扩展、监控与优化
重点工作:
- 在一个真实队列或主题上正式上线
- 每日监控关键指标和异常案例
- 对比 AI 辅助工单与纯人工工单
- 持续优化提示词和知识库
- 在试点稳定后,逐步增加新工作流
阶段产出:
- 生产环境监控与看板
- QA 评审流程与抽检机制
- 优化后的提示词与策略
- 成本与节省报告
- 是否扩大上线的决策建议
- 下一批用例的路线图
DeepSeek 适不适合你的客服团队?
比较适合的情况
如果你的团队具备这些条件,DeepSeek 往往能发挥不错的效果:
- 工单量大且重复问题占比高
- 有结构化的帮助中心或内部知识库
- 支持政策相对清晰、可文档化
- 有一定技术能力做 API 集成
- 有客服运营数据可用于评估
- 能安排人工审核 AI 输出
- 有明确的成本压力和自动化诉求
- 需要结构化输出和智能路由
不太适合的情况
这些场景下,DeepSeek 可能不是最佳选择:
- 知识库严重过期或几乎不存在
- 团队无法投入人力审核 AI 输出
- 大部分工单涉及法律、医疗、金融等高度敏感领域
- 合规或法务团队尚未评估数据流
- 希望买到「开箱即用、全托管」的原生 AI 客服产品
- 无法持续监控幻觉和升级质量
拿不准时,可以先做一个小试点
如果你还在犹豫,最稳的做法是:
- 选 1–2 个低风险、高频工作流
- 只在内部或小流量渠道试点
- 所有回复先由人工审核
- 用 4–8 周时间收集数据和反馈
很多团队在做完这样一个试点后,会对「AI 能做什么、不能做什么」有更清晰的感受,也更容易说服管理层和合规团队。
小结与行动建议
DeepSeek 客服自动化的价值,不在于「把人换成机器人」,而在于:让 AI 先干掉那些机械、重复、可标准化的工作,再把真正需要判断力和共情能力的部分留给人。配合结构化 JSON 输出、Tool Calls、RAG、隐私控制和清晰的升级规则,它可以成为你客服体系里一块很有力的「加速踏板」。
如果你正纠结要不要上 AI 客服,不妨先做一件小事:抽取最近 1000 条工单,找出一个高频低风险场景,用上文的提示词和流程搭一个「人工审核版」试点。等你亲眼看到节省的时间和更完整的回复,再决定要不要扩大范围,这比问十个朋友都更有参考价值。
常见问题
Q:用 DeepSeek 做客服自动化,怎么判断哪些工单可以完全自动回复?
A:可以优先选择高频、规则清晰、金额和风险都较低的场景,比如订单状态查询、基础功能说明、密码重置指引等。判断标准包括:历史上几乎没有投诉或升级、答案高度标准化、对客户影响可控。建议先用历史工单做离线评估,给每类问题打上「可自动 / 需人工审核 / 必须人工」标签,再在系统里用意图识别 + 置信度阈值控制自动化范围,初期宁可保守一些,逐步放开。
Q:DeepSeek 的 JSON Output 在工单系统里具体怎么用?
A:JSON Output 可以把模型输出变成结构化字段,比如 intent、priority、sentiment、escalation_required 等。工单系统收到这些字段后,就能自动打标签、分配队列、设置 SLA、触发通知或自动回复。实现时,可以在中间件里解析 JSON,把字段映射到工单系统的自定义字段或标签,再根据这些字段配置自动化规则。要注意的是,解析前最好做一次 JSON 校验和兜底处理,防止异常输出影响生产流程。
Q:如何控制 DeepSeek 不乱承诺退款、赔偿或时效?
A:可以从三层入手:提示词、业务逻辑和人工审核。提示词层面,明确写出「不得承诺退款、折扣、赔偿或具体时效,除非上下文政策明确允许」;业务逻辑层面,对涉及金额、时效的回复增加规则校验,比如检测关键词并强制人工审核;人工层面,对退款、投诉等高风险类别设置「只生成草稿、不允许自动发送」。同时,定期抽样检查相关对话,一旦发现越权承诺,及时调整提示词和规则。
Q:DeepSeek 部署在客服场景下,隐私和合规风险主要有哪些?
A:主要风险包括:向第三方发送过多个人信息或敏感数据、数据跨境传输不符合当地法规、缺乏清晰的数据保留和删除策略、内部访问控制过于宽松等。应对方式是:在发送前做脱敏和字段筛选,避免传输不必要的 PII;与法务和合规团队确认数据存储位置和处理方;在文档中写清「哪些数据、出于什么目的」会被发送给 DeepSeek;对高敏感业务线(如金融、医疗)单独评估是否适合使用公有云模型,并考虑本地化或专用实例方案。
Q:如果团队技术能力有限,还值得尝试 DeepSeek 客服自动化吗?
A:依然可以尝试,但更适合从小范围、低代码方案入手。比如先用 Zapier、Make.com 这类工具,把新工单内容发给 DeepSeek,再把分类结果写回工单系统的标签字段,用于辅助人工分单。这样技术门槛较低,也能直观看到效果。等团队熟悉 AI 在客服里的价值和边界后,再考虑投入开发资源做更深的集成。过程中要记得保留人工审核和监控机制,避免因为技术实现不完善带来体验或合规风险。


