99% 的团队在用大模型时,都停留在「聊天」层面,却忽略了真正省时间的是「让 AI 带着流程自己跑」。DeepSeek 工作流自动化说白了,就是把 DeepSeek 变成流程里的一个可靠节点,让它读懂数据、做出判断、给出结构化结果,再交给系统去执行。只要设计得当,很多原本要人工点来点去的步骤,都可以变成「自动往前推」的流水线。
有用户反馈,用 DeepSeek 做邮件分拣和工单路由后,一天能少看 40% 的重复邮件,但关键决策仍然保留人工审核。说实话,这种「半自动」模式,往往比一上来就追求全自动更稳。下面我们从概念、架构、工具和风险几个维度,把 DeepSeek 工作流自动化拆开讲清楚。
什么是 DeepSeek 工作流自动化?
从「聊天」到「流程」:触发器驱动的 AI 节点
DeepSeek 工作流自动化,是指在自动化流程里调用 DeepSeek 模型,让它负责理解、分类、摘要、抽取、生成、路由或决策。和聊天机器人等人来才动的模式不同,自动化系统是「事件驱动」的:新工单创建、表单提交、Webhook 触发、CRM 记录变更、发票上传、定时任务执行等,都会自动拉起一次流程。
在这些流程中,DeepSeek 只是其中一环:它可能负责把一封长邮件压缩成摘要,把发票内容抽成 JSON,把用户问题归类成工单类型,或者给销售同事推荐下一步动作。真正执行创建工单、更新 CRM、发 Slack、写入数据库的,是自动化平台和业务系统。
可以把 DeepSeek 想成「会读写、会推理的中间件」,而不是一个要接管一切的智能助理。它负责把模糊的自然语言,变成系统能吃得下的结构化信号。
很多团队一开始会误以为「让 AI 直接处理支持请求」是捷径,但更安全的做法,是让模型只做窄任务:分类、打标签、给草稿,由工作流来决定后续动作,并在高风险环节插入人工审核。
DeepSeek 模型与版本:为什么和迁移有关
到 2026 年,DeepSeek API 支持 OpenAI 兼容和 Anthropic 兼容格式,主力模型包括 deepseek-v4-flash 和 deepseek-v4-pro,而旧的 deepseek-chat 和 deepseek-reasoner 计划在 2026-07-24 停用。对已经在生产里跑自动化的团队,这意味着两件事:一是新建流程要直接用 V4 模型,二是老流程要提前规划迁移,避免某天模型下线导致整条业务线停摆。
据官方文档,V4 模型提供 1M 上下文长度、JSON 输出、工具调用和聊天前缀补全等能力,这些都直接影响工作流的设计空间和稳定性。迁移时,除了改模型名,还要回头检查提示词、输出格式和成本预估。
为什么在工作流里用 DeepSeek?
成本、结构化输出与集成生态
DeepSeek 在工作流自动化场景的优势,主要集中在三块:成本敏感、结构化输出能力,以及对现有自动化平台的兼容。官方文档显示,deepseek-v4-flash 和 deepseek-v4-pro 都支持 1M 上下文、JSON 输出模式、工具调用和聊天补全,这让它们很适合做「读长文档、吐结构化结果」的任务。
数据显示,有团队在邮件分类和发票抽取场景,把原本基于人工规则的系统换成 DeepSeek 后,平均处理时间缩短了约 60%,同时保持了可审计的 JSON 输出。对自动化来说,能稳定吐出结构化字段,比写得多漂亮的自然语言重要得多。
当然,DeepSeek 并不是所有工作流的最优解。延迟、区域、合规、安全策略、模型质量、集成生态和总成本,都会影响选择。有的企业会把 DeepSeek 放在「成本优先」的流程里,把其他模型留给对准确性要求极高的环节,这种混搭在实践中很常见。
适合 DeepSeek 的典型工作流特征
更适合用 DeepSeek 的工作流,通常有几个特征:需要结构化输出(JSON、字段)、对成本比较敏感、调用频率高、任务相对标准化、可以通过规则和人工审核兜底。比如:工单分类、邮件分拣、线索打分、内容审核预筛、内部摘要生成等。
有一位运营负责人分享,他们先用 DeepSeek 做内部周报摘要和工单标签,跑了两个月稳定后,才逐步把它接入外部客户邮件的草稿生成环节。中间他们发现一个问题:模型偶尔会给出过于乐观的承诺,于是又在提示词里加上「不要夸大产品能力」的规则,并强制所有外发邮件都要人工点一下确认。
DeepSeek 在自动化技术栈中的位置
从触发到监控:一条完整链路长什么样
下面这张图展示了一个典型的 DeepSeek 工作流自动化,从触发事件到 AI 处理、验证、应用动作、人工审核和监控的全流程:
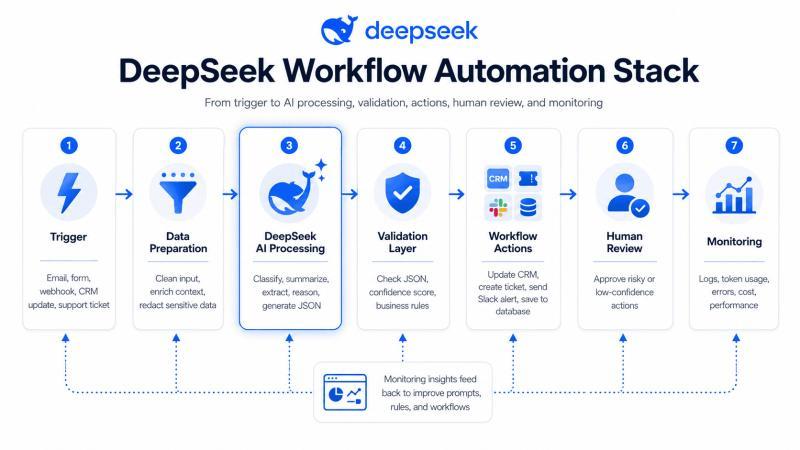
一个可靠的 DeepSeek 自动化,远远不止「写个提示词」这么简单。它需要清晰的触发器、干净的输入、明确的模型指令、严格的输出验证、后续动作节点、必要的人工审核,以及完整的日志和监控。缺一块,都可能在生产环境里踩坑。
典型架构可以抽象成这样:
Trigger
↓
Input Cleaning and Context Preparation
↓
DeepSeek API Call
↓
Structured JSON Output
↓
Validation and Business Rules
↓
Workflow Actions
↓
Human Review for Risky Cases
↓
Logging, Monitoring, and Cost Tracking
支持自动化的关键能力:JSON、工具调用与模式切换
DeepSeek 的 API 采用 OpenAI / Anthropic 兼容格式,这对已经在用这些生态的团队非常友好。很多无代码平台、SDK 和代理框架都支持 OpenAI 风格接口,意味着你往往只需要改一下 base_url 和模型名,就能把 DeepSeek 接进来。
在自动化场景里,最关键的能力有几项:
- JSON 输出模式:通过
response_format={"type":"json_object"},配合提示词里明确写出「返回 JSON」和示例结构,可以大幅降低解析失败的概率。 - 工具调用(function calling):模型只负责「决定要调用哪个工具、用什么参数」,真正执行由你的代码或平台完成,适合做订单查询、CRM 查找、数据库查询、创建工单、调用内部 API 等代理式任务。
- 思考 / 非思考模式:非思考模式适合快速、低风险任务(打标签、抽取、短摘要),思考模式适合复杂决策、多步推理和模糊场景。需要注意的是,思考模式下的
reasoning_content要在后续调用中正确处理,避免把中间推理内容误当成用户可见输出。
我自己的观察是:很多团队一上来就全用思考模式,结果成本高、延迟长,还没明显收益。更好的做法,是只在「确实需要深度推理」的节点打开思考模式,其余节点用非思考模式跑量。
长上下文、缓存与模型选择:影响成本的隐性杠杆
1M 上下文不是「全都丢进去」的理由
官方定价页显示,当前 V4 模型支持 1M 上下文、最多 384K 输出,这对长文档、知识库工作流、合同审阅、研究总结和多记录分析非常有用。但长上下文也容易让人产生错觉:反正能塞,就全塞进去。
更稳的做法是:
- 只选对当前任务最有用的片段
- 对敏感字段做脱敏或删减
- 通过检索(RAG)只拉取必要记录
- 把系统指令和用户数据分区,方便缓存和调试
有团队在知识库问答场景里,把「整库塞进上下文」改成「先检索再喂模型」,单次调用的 token 降到原来的 20% 左右,响应速度也明显提升。
定价与缓存:怎么让每次调用更划算
根据官方定价页面,deepseek-v4-flash 在缓存命中时的输入价格约为每 1M token 0.0028 美元,缓存未命中约为 0.14 美元,输出约为 0.28 美元;deepseek-v4-pro 在 2026-05-31 前有折扣,且 DeepSeek 提醒价格可能调整,上线前务必再核对一次。
对工作流来说,缓存的意义在于:如果你的系统提示词和策略说明长期稳定,重复调用时可以享受缓存价。设计提示词时,可以把「可复用的规则」和「每次变化的数据」拆开,前者尽量保持不变,后者放在单独的输入区,这样既利于缓存,也方便后期维护。
模型选择上,一个常见的经验是:
deepseek-v4-flash:高频、快节奏、重复性强的任务,如分类、抽取、打标签、摘要、简单回复草稿deepseek-v4-pro:复杂推理、规划、编码、代理式工作流,或对准确性要求更高的决策
需要提醒的是,在敏感工作流里,模型选择只是风险控制的一部分,验证、日志、人工审核和治理机制同样重要。
无代码 / 低代码:用现成平台接入 DeepSeek
常见平台:n8n、Make、Zapier、Workato、BuildShip
你可以通过无代码平台、低代码工作流构建器或自建 API 服务来使用 DeepSeek。当前常见的集成方式包括:
- n8n:提供 DeepSeek 凭据和 Chat DeepSeek 节点,使用 API Key 认证
- Make:内置 DeepSeek AI 模块,包括创建聊天补全、查询余额、列出模型和自定义 API 调用
- Workato:通过 HTTP 连接器和 DeepSeek 集成,适合企业级集成场景
- Zapier:提供 DeepSeek 动作,如创建 Chat Completion,适合简单自动化
- BuildShip:给出 DeepSeek 无代码集成指南,并提供 DeepSeek AI Chat 节点
有团队用 Make + DeepSeek 搭了一个线索评分系统,从表单提交到 CRM 更新、Slack 通知全自动跑完,后面只在「高价值线索」上加了人工复核节点。数据显示,销售团队的响应时间从平均 6 小时缩短到 1 小时以内。
实战案例矩阵:从低风险开始
下面这张矩阵图,展示了 DeepSeek 在不同业务场景下的工作流示例:
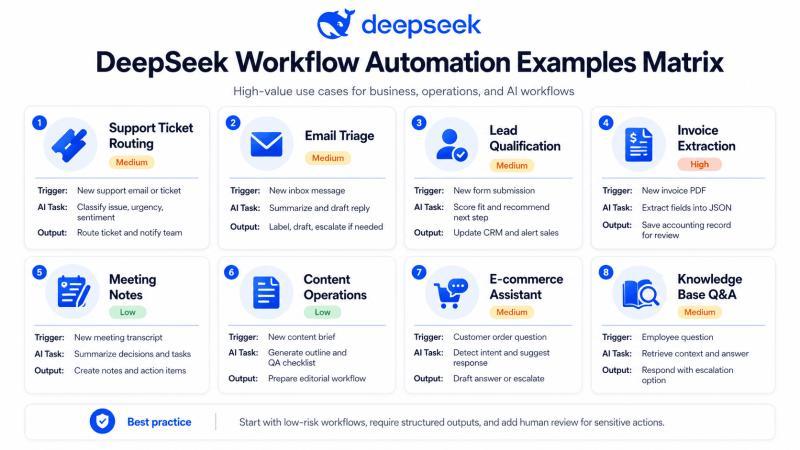
最适合作为起点的,往往是低风险、重复性高的内部流程,比如:内部邮件摘要、工单打标签、线索评分、内容草稿生成等。不要一上来就做「全自动回复客户」「自动审批财务」「自动做合规决策」这类高风险场景,那样出一次错,代价会非常高。
n8n 示例:搭一个 DeepSeek 支持邮件分流工作流
工作流目标与步骤
场景:对新进来的支持邮件做分类,并路由到合适的团队。可以在 n8n 中按下面步骤搭建:
- 添加 Gmail Trigger 或 Webhook Trigger
- 抽取邮件主题、发件人和正文
- 添加 Chat DeepSeek 节点或 HTTP Request 节点
- 发送结构化的分类提示词
- 要求返回严格的 JSON 输出
- 解析 JSON
- 根据
category和urgency做路由 - 在 Zendesk、HubSpot、Linear 或 Jira 中创建工单
- 对紧急问题发送 Slack 通知
- 把结果存入 Google Sheets、Airtable 或 Postgres
- 在任何外发回复前加一个人工审批节点
n8n 的 DeepSeek 凭据使用 API Key 认证,官方文档会引导你去 DeepSeek API 文档查看服务细节和限制。
示例提示词与输出
示例提示词:
You are a support operations classifier.
Return only valid JSON.
Classify this inbound customer email and produce the following fields:
- category: one of ["billing", "technical_issue", "account_access", "feature_request", "cancellation", "other"]
- urgency: one of ["low", "medium", "high", "critical"]
- sentiment: one of ["positive", "neutral", "frustrated", "angry"]
- summary: short plain-English summary
- suggested_reply: concise draft reply
- escalate_to_human: true or false
Rules:
- Set escalate_to_human to true if the email mentions legal threats, payment disputes, data loss, security, cancellation, or angry sentiment.
- Do not invent account details.
- Keep suggested_reply under 120 words.
Email subject: {{ $json.subject }}
Email body: {{ $json.body }}
示例 JSON 输出:
{ "category": "billing", "urgency": "high", "sentiment": "frustrated", "summary": "Customer says they were charged twice and wants an immediate refund.", "suggested_reply": "Thanks for reaching out. We’re sorry for the billing issue. I’m escalating this to our billing team so they can review the duplicate charge and follow up with the next steps.", "escalate_to_human": true }
常见故障排查思路
如果 JSON 解析失败,可以优先检查三点:提示词里有没有明确写「JSON」、输出是否被截断、API 调用是否正确设置了 response_format。DeepSeek 的 JSON 输出指南建议:设置 response_format={"type":"json_object"},提供示例 JSON 结构,并把 max_tokens 调高一点避免截断。
如果回复太空泛,可以在提示词里加入「好示例」;如果路由不稳定,可以减少分类选项;如果紧急问题漏判,就在规则里加上更明确的升级条件。很多时候,问题不在模型,而在提示词和验证逻辑。
Make 示例:用 DeepSeek 做线索评分与 CRM 更新
工作流目标与步骤
场景:对表单提交的新线索做资格评估,并更新到 CRM。可以在 Make 中这样设计:
- 使用 Typeform、Fillout、Tally 或 Webflow 的表单触发器
- 把线索数据映射到 DeepSeek AI 模块
- 让 DeepSeek 评估线索匹配度并推荐下一步动作
- 解析 JSON 响应
- 更新 HubSpot、Pipedrive、Salesforce 或 Airtable
- 生成一封个性化跟进邮件草稿
- 在 Slack 通知对应销售
- 对低置信度或高价值线索,发送到人工复核队列
Make 的 DeepSeek AI 集成支持聊天补全、余额查询、模型列表和自定义授权 API 调用,足够覆盖大多数线索处理场景。
示例提示词与输出
示例提示词:
Return only valid JSON.
You are a B2B SaaS lead qualification assistant.
Evaluate this lead: Company: {{company}} Industry: {{industry}} Company size: {{company_size}} Job title: {{job_title}} Message: {{message}} Budget: {{budget}} Timeline: {{timeline}}
Return: { "lead_score": 0-100, "fit": "poor" | "moderate" | "strong", "reason": "short explanation", "next_best_action": "book_demo" | "send_resources" | "manual_review" | "disqualify", "personalized_email_draft": "short email", "confidence": 0-1 }
Rules:
- Score higher if company size, budget, and timeline match an enterprise SaaS buyer.
- Set next_best_action to manual_review if confidence is below 0.7.
- Do not overstate product capabilities.
示例 JSON 输出:
{ "lead_score": 82, "fit": "strong", "reason": "The lead is a decision-maker at a mid-market company with an active budget and near-term timeline.", "next_best_action": "book_demo", "personalized_email_draft": "Hi Sarah, thanks for sharing your automation goals. Based on your timeline and team size, a short demo would be the fastest way to map the right workflow. Would Tuesday or Wednesday work for you?", "confidence": 0.84 }
Make 场景的几个实践建议
在 Make 里搭场景,建议把逻辑拆得更细一点:线索评分、CRM 更新、Slack 通知、邮件草稿,各自做成清晰的模块。可以加过滤条件,比如只对 fit=strong 且 lead_score>70 的线索推送给销售,对 `confidence 对业务自动化来说,真正危险的不是「用了 AI」,而是「在没搞清楚数据流向和合规要求前,就把敏感数据一股脑丢给外部模型」。
业务侧应该落实的安全措施
在设计 DeepSeek 工作流自动化时,可以考虑这些防护:
- 不在未经评估的情况下发送高度敏感数据
- 在发送前对个人数据做脱敏或裁剪
- 使用后端代理,而不是在前端暴露 API Key
- 把密钥存放在安全的密钥库或环境变量中
- 对工作流用户设置最小权限
- 为 AI 生成的关键决策添加审计日志
- 在执行动作前验证模型输出的结构和范围
- 对退款、法律问题、账号关闭、医疗、金融、HR、合规相关决策强制人工审批
- 明确数据驻留要求,评估跨境传输风险
- 维护模型与供应商风险清单,定期复盘
AWS 的生成式 AI 安全指南提到,隐私、治理、幻觉、数据投毒、对抗性提示和代理式 AI 安全等都是需要重点关注的风险,并建议尽量避免不必要的机密数据暴露,及早让合规团队参与设计。
打造可靠 DeepSeek 自动化的实践准则
让工作流「可预期、可验证、可观测」
一个靠谱的自动化流程,往往具备三个特征:目标清晰、输出可验证、运行可观测。可以参考下面这些做法:
- 从一个清晰的工作流开始:不要试图一次性自动化整个部门
- 使用结构化提示词:明确角色、任务、输入、输出字段和规则
- 强制要求 JSON 输出:下游自动化应该解析字段,而不是读长段文字
- 验证每一次响应:检查必填字段、类型、枚举值和置信度
- 加入重试和降级策略:处理 API 错误、限流和格式错误输出
- 使用置信度评分:把不确定的案例路由给人工
- 区分低风险和高风险工作流:草稿生成远比自动发送安全
- 让提示词更适合缓存:把稳定的系统指令和动态数据分开
- 监控成本:跟踪 token 使用量和每条工作流的成本
- 衡量业务效果:关注解决率、节省时间、错误率、升级率、单次成本和用户满意度
目标不是让 AI 完全接管,而是把重复、机械的步骤交给系统,让人把精力放在真正需要判断和沟通的地方。
常见踩坑:别让工作流「黑箱」运行
在实践中,常见的错误包括:
- 一口气自动化太多流程
- 让 AI 在无人审核的情况下给客户发敏感信息
- 不验证 JSON 就直接执行动作
- 对幻觉视而不见
- 继续使用即将废弃的模型名
- 忘记
deepseek-chat和deepseek-reasoner已是计划下线的旧模型 - 不必要地发送机密数据
- 搭建工作流时不记录日志
- 把 DeepSeek 当成完整自动化平台,而不是栈中的一个模型组件
- 不测试边界情况和异常输入
- 忽略隐私、合规和区域数据要求
- 上线后不监控成本和错误
一个好的自动化应该「安全失败」:当模型不确定或输出异常时,流程会停下来、打标记、通知人工,而不是悄悄做出高风险决策。
上线前检查清单:给工作流做一次「体检」
在把 DeepSeek 工作流推向生产环境前,可以用这份清单过一遍:
- 明确工作流目标
- 选定触发器
- 选择自动化平台
- 选择合适的 DeepSeek 模型
- 定义输入数据范围
- 对敏感字段做脱敏或剔除
- 写出结构化提示词
- 强制要求 JSON 输出
- 对响应做结构和规则验证
- 配置后续动作节点
- 为高风险步骤添加人工审核
- 存储运行日志
- 跟踪 token 使用情况
- 测试各种边界情况
- 测试异常和脏数据输入
- 专门测试愤怒客户、法律威胁、退款和安全问题
- 添加重试逻辑
- 添加降级和备用方案
- 做隐私与合规评审
- 上线后持续监控性能和成本
很多团队会把这份清单做成内部 SOP,每次新建或修改工作流都过一遍,久而久之,自动化质量会稳定在一个比较高的水平。
行动建议与收藏价值
如果你现在正纠结「要不要在业务里上 DeepSeek」,一个可行的路径是:先选一条最烦人的重复流程,画出当前步骤,再用上面的架构和清单,搭一个小范围试点。等这个试点在真实数据和边界场景下跑稳了,再考虑扩展到更多流程。
这些判断标准和提示词模板,在不同业务之间是可以复用的。等你下次需要评估另一条工作流,只要把这套方法拿出来对照一遍,往往比到处问人更有用。如果你担心哪天要快速做决策,不妨把这篇内容收藏起来,当成一份「AI 工作流设计备忘录」。
常见问题
Q:怎么判断一条业务流程适不适合先用 DeepSeek 自动化?
A:可以先看三个信号:是否重复高频、是否有清晰的输入输出结构、是否可以通过规则和人工审核兜底。比如工单分类、邮件摘要、线索打分,这类任务输入相对标准、输出可以定义成固定字段,而且即便模型出错,也可以通过人工复核纠正。相反,涉及金额审批、合规判断、法律回复等流程,一旦出错代价很高,就不适合作为第一批自动化对象。建议先从内部、低风险、可回滚的流程开始,跑通一条再扩展。
Q:DeepSeek 的 JSON 输出不稳定时,有哪些具体优化办法?
A:可以从提示词、参数和验证三方面入手。提示词里要明确写「只返回 JSON」、给出完整示例结构,并避免在同一条消息里混入多种输出格式;参数上要设置 response_format={"type":"json_object"},并把 max_tokens 调高,防止输出被截断;验证层面要在代码或无代码平台里检查必填字段、类型和枚举值,一旦发现异常就重试或转人工。必要时可以把复杂任务拆成两步:先分类,再生成内容,降低单次输出的复杂度。
Q:在安全和合规上,用 DeepSeek 时最容易被忽视的风险是什么?
A:最常被忽视的是「数据流向和驻留」问题。DeepSeek 的隐私政策提到,个人数据可能存储在用户所在国家之外,并在中国境内处理,这对有数据本地化要求或跨境传输限制的企业非常关键。如果忽略这一点,可能在审计或监管检查时遇到麻烦。建议在接入前让法务和合规团队参与评估,梳理哪些数据可以发送、哪些必须脱敏或禁止发送,并在后端代理层强制执行这些规则,同时保留访问和调用日志以备审计。
Q:如何控制 DeepSeek 工作流的成本,避免上线后费用失控?
A:成本主要由调用次数、输入输出 token 数量和模型单价决定。可以从三方面控制:一是优化上下文,只发送当前任务必需的信息,避免长文档整篇塞;二是合理选择模型,把高频、简单任务放在 deepseek-v4-flash,复杂推理才用 deepseek-v4-pro;三是利用缓存,把稳定的系统提示词和策略说明固定下来,减少重复计费。上线后要在日志里记录每次调用的 token 使用量和费用,按工作流维度做统计,发现异常峰值时及时排查是否有循环调用或错误重试。
Q:如果 DeepSeek 模型未来版本更新或旧模型下线,工作流该怎么平滑迁移?
A:迁移时可以遵循「双轨运行」的思路。先在测试或预发布环境中,用新模型跑一份与生产相同的工作流,对比分类结果、摘要质量、错误率和成本,再根据差异微调提示词和验证逻辑。等新模型表现稳定后,在生产环境里短时间内同时跑新旧两条链路,对关键指标做 A/B 对比,确认没有明显退化再完全切换。对于计划下线的模型,要提前在代码和无代码平台里统一抽象出「模型配置层」,避免模型名散落在各个节点里,方便集中替换和回滚。


