99% 的团队用 AI 还停留在“聊天机器人”,却忽略了真正省时间的是“让 AI 接在触发器后面自己干活”。DeepSeek 工作流自动化说白了,就是把 DeepSeek 接到表单、邮件、工单、CRM、财务系统和消息工具上,让它在后台默默分类、提取、决策,而不是等人来问一句答一句。只要设计好触发条件、结构化输出和人工复核,很多重复工作可以从几小时缩短到几分钟。
这篇指南会带你看清:DeepSeek 在自动化技术栈里的位置,如何选对模型并规划迁移,怎么用 n8n、Make、Zapier、Workato、BuildShip 和自建 API 做集成,以及如何在安全、合规的前提下,把它用在真正的业务场景里。
什么是 DeepSeek 工作流自动化?
从“聊天”到“推动工作前进”
DeepSeek 工作流自动化,是指在自动化流程里调用 DeepSeek 模型,让它去理解、分类、总结、抽取、生成、路由或触发动作。和传统聊天机器人不一样,聊天要等人输入一句话,工作流则是“事件驱动”:新工单创建、表单提交、Webhook 触发、CRM 字段变更、新发票上传、定时任务执行等,都会自动启动一次流程。
触发后,DeepSeek 会在流程中承担一个明确的角色,比如:给支持邮件打标签、总结长邮件、把发票内容抽取成 JSON、生成 CRM 备注、写一条 Slack 告警、推荐下一步销售动作,或者判断是否需要升级给人工处理。真正的差别在于:聊天机器人只“回应”,自动化系统会“推进工作”。
可以把 DeepSeek 想成流程里的“智能节点”,而不是一个单独的聊天窗口。它只负责那一步的判断和生成,其余交给自动化平台和人类来兜底。
DeepSeek 模型与版本演进
到 2026 年,DeepSeek API 支持 OpenAI 兼容和 Anthropic 兼容两种格式,当前主力模型包括 deepseek-v4-flash 和 deepseek-v4-pro,老的 deepseek-chat 与 deepseek-reasoner 计划在 2026 年 7 月 24 日废弃。对已经在生产环境里跑工作流的团队来说,这意味着必须提前做模型选择和迁移规划。
根据官方文档,这两款 V4 模型都支持 100 万上下文长度、JSON 输出、工具调用(tool calls)以及 chat 前缀补全。很多现有的 SDK、Agent 框架和自动化平台已经支持 OpenAI/Anthropic 风格接口,所以 DeepSeek 可以比较顺滑地接入现有栈,而不用从零重写。
为什么用 DeepSeek 做工作流自动化?
适合“结构化 + 省成本”的场景
DeepSeek 在工作流里的价值,主要体现在三个维度:结构化输出、推理能力和成本控制。官方文档显示,deepseek-v4-flash 与 deepseek-v4-pro 都支持 JSON 输出模式和工具调用,这让它非常适合做分类、抽取、路由、评分等需要“机器可读结果”的任务。数据显示,有团队在客服自动分单场景中,用 JSON 输出替代人工规则后,工单分配时间缩短了 70% 以上。
从价格上看,DeepSeek 的按 token 计费在同类模型中偏低,尤其是缓存命中时的输入价格。对高频调用的自动化流程来说,长期成本差距会被放大。有用户反馈,在把部分 OpenAI 调用迁移到 DeepSeek 后,同等工作流的月度账单下降了约 40%。
不是“万能模型”,而是“合适就好”
话说回来,DeepSeek 也不是每个工作流的最优解。模型选择还要考虑延迟、部署区域、合规要求、安全策略、生态集成程度以及总成本。有些对实时性极高的场景,可能更适合本地模型或边缘推理;有些强监管行业,则会优先看数据流向和法律风险。
一个实用的判断标准是:
- 需要长上下文 + 结构化输出 + 成本敏感 → 优先考虑 DeepSeek
- 需要极致生态集成或特定厂商能力 → 评估 OpenAI、Claude、Gemini
- 有强数据主权要求 → 评估本地或私有化模型
DeepSeek 在自动化技术栈中的位置
从触发到监控的整体链路
下面这张示意图展示了一个典型的 DeepSeek 自动化系统,从触发事件到 AI 处理、验证、应用动作、人工审核和监控的完整链路:
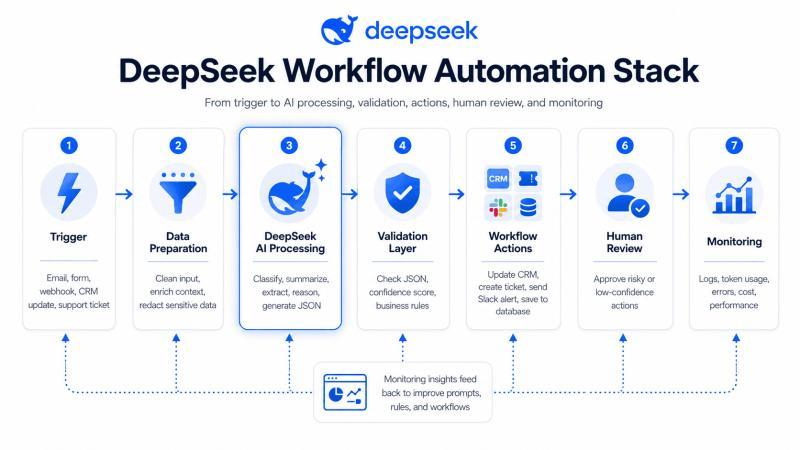
一个可靠的 DeepSeek 自动化流程,远远不止“写个 prompt 就完事”。它需要清晰的触发器、干净的输入、明确的模型指令、结构化输出验证、后续动作节点、必要的人工审核,以及日志与成本监控。典型架构大致如下:
Trigger
↓
Input Cleaning and Context Preparation
↓
DeepSeek API Call
↓
Structured JSON Output
↓
Validation and Business Rules
↓
Workflow Actions
↓
Human Review for Risky Cases
↓
Logging, Monitoring, and Cost Tracking
客服自动化示例链路
以客服邮件自动分流为例,流程可能长这样:
New Gmail message
↓
Extract subject, sender, body, attachments
↓
Send to DeepSeek for classification
↓
Return JSON: category, urgency, sentiment, summary, suggested reply
↓
Create Zendesk ticket
↓
Notify Slack if urgent
↓
Require human approval before sending reply
↓
Log decision and token usage
这种结构比“让 AI 全权处理客服”安全得多。模型只做窄任务,自动化平台负责路由和执行,高风险动作前加一层人工确认。一个朋友在迁移客服流程时,就先只让 DeepSeek 负责“分类 + 摘要”,连续跑了两周稳定后,才逐步开放“草拟回复 + 人工审核”。
DeepSeek API 中对自动化最关键的能力
OpenAI / Anthropic 兼容接口
DeepSeek 声称其 API 与 OpenAI、Anthropic 接口格式兼容,这对已经在用这些生态的团队非常友好。很多无代码平台、Agent 框架和 SDK 都内置了 OpenAI 风格的连接器,DeepSeek 可以通过 HTTP 模块、OpenAI 兼容连接器或后端代理直接接入。
对开发者来说,这意味着实现时间更短;对自动化团队来说,则可以在不大改现有架构的前提下,增加一个新的模型选项,用路由或 A/B 测试来比较效果和成本。
JSON 输出:让结果“可被机器消费”
结构化输出几乎是自动化场景的生命线。DeepSeek 的 JSON Output 模式,专门用来帮助模型返回合法 JSON 字符串。官方建议:
- 在请求中设置
response_format为{"type":"json_object"} - 在提示词中明确写出“JSON”
- 提供目标 JSON 结构示例
- 通过
max_tokens避免输出被截断
对工作流来说,这一点非常关键。CRM 更新、路由规则、数据库写入、Slack 告警,都不能依赖“看起来像”的自然语言。说实话,只要你经历过一次“因为少了一个逗号导致整条自动化挂掉”,就会非常在意 JSON 的严谨度。
工具调用(Tool Calls)与函数调用
DeepSeek 支持工具调用:模型可以请求调用某个外部函数,由你的应用实际执行。文档也强调,模型本身不会执行函数逻辑,只负责决定“该调用哪个工具、传什么参数”。
这让它非常适合做 Agent 风格的工作流,比如:
- 查询订单状态
- 查找 CRM 记录
- 执行数据库查询
- 创建工单或任务
- 草拟文档并存入知识库
- 调用内部 API 完成业务操作
DeepSeek 还提供了严格工具调用模式(beta),通过 base_url="https://api.deepseek.com/beta" 和函数定义中的 strict: true 来启用,更适合对参数格式要求极高的生产环境。
思考模式与非思考模式
当前 DeepSeek 模型支持“思考模式”和“非思考模式”。非思考模式适合快速、重复、低风险任务,比如打标签、字段抽取、短摘要等;思考模式则更适合复杂决策、多步推理和高不确定性的场景。
思考模式同样可以配合工具调用使用,不过开发者需要在后续 API 调用中正确处理 reasoning_content 字段,避免把模型的推理过程误当成最终输出。我的感觉是:在早期验证阶段,可以先用非思考模式跑通流程,再在关键节点切换到思考模式做精细化优化。
上下文长度与提示词复用
官方定价页显示,当前 V4 模型支持 100 万上下文长度,最大输出约 38.4 万 tokens。这对长文档、知识库工作流、合同审阅、研究总结和多记录分析非常有用。不过长上下文不是“把所有东西都塞进去”的理由。
更好的做法是:
- 只选择当前任务最有用的上下文
- 对敏感数据做脱敏或替换
- 用检索(RAG)方式按需拉取记录
- 把稳定的系统提示词单独抽出来,方便缓存和复用
定价与缓存策略
根据撰文时查看的官方定价:
deepseek-v4-flash:缓存命中输入约 $0.0028 / 100 万 tokens,缓存未命中输入约 $0.14 / 100 万 tokens,输出约 $0.28 / 100 万 tokensdeepseek-v4-pro:在 2026-05-31 前有折扣,且官方提醒价格可能调整
在工作流场景里,Prompt 缓存会非常关键。如果系统提示词和策略说明长期稳定,重复调用就能享受缓存价格。可以把提示词设计成“上半部分是稳定规则,下半部分是每次变化的数据”,这样既利于缓存,又方便维护。
模型选择:速度 vs 推理
一个简单的选择思路:
deepseek-v4-flash:高并发、快节奏、重复性强的工作流,如分类、抽取、打标签、摘要、简单回复草稿deepseek-v4-pro:复杂推理、规划、代码生成、Agent 工作流,或对准确性要求更高的决策
对敏感工作流来说,模型只是整体设计的一部分。验证、日志、人工审核和治理机制,同样决定了这条自动化能不能安全上线。
无代码 / 低代码集成 DeepSeek 的几种方式
常见平台与集成方式
你可以通过无代码平台、低代码工作流构建器或自建 API 服务来使用 DeepSeek:
- n8n:提供 DeepSeek 凭据和 Chat DeepSeek 节点,使用 API Key 认证
- Make:内置 DeepSeek AI 模块,包括创建 Chat Completion、查询余额、列出模型和自定义 API 调用
- Workato:列出 DeepSeek 集成,并支持通过 HTTP 连接器自定义连接
- Zapier:提供 DeepSeek 动作,如 Create Chat Completion
- BuildShip:给出 DeepSeek 集成指南和 DeepSeek AI Chat 节点
有用户在 Make 上搭建线索评分工作流,用 DeepSeek 做 JSON 评分 + 邮件草稿,配合 Slack 通知和人工复核,整个流程从“销售手动筛选”变成“AI 预筛 + 人工确认”,每天节省了 2 小时以上。
典型适用场景
这些平台特别适合:
- 业务团队自己搭建内部自动化,不依赖工程师排期
- 快速验证一个 AI 工作流是否有价值
- 把 DeepSeek 嵌入现有的 Gmail、Slack、HubSpot、Zendesk、Notion 等工具
不过也有风险:无代码空间往往多人共享,如果直接暴露 API Key 或处理敏感数据,安全隐患会被放大。这一点在后面安全章节会详细展开。
DeepSeek 工作流自动化案例
常见高价值场景矩阵
下面是一些比“用 AI 省时间”更具体的落地例子:
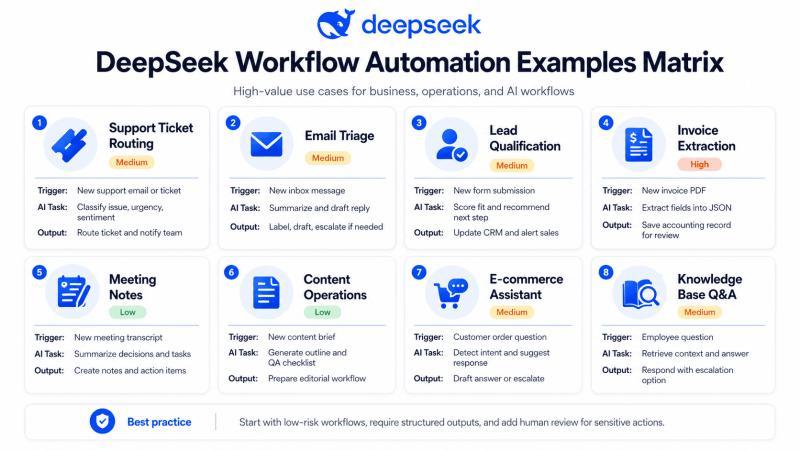
比较适合作为起步的,是低风险、重复性强的内部流程,比如:内部邮件摘要、工单打标签、线索评分、内容草稿生成等。尽量不要一上来就做“全自动对外回复”“自动财务审批”或“合规敏感决策”,那样出一次错,代价会非常高。
有用户反馈,他们先从“内部日报自动总结 + Slack 推送”开始,跑顺之后再扩展到“客服分单 + 回复草稿”,整个团队对 AI 的信任感也更容易建立。
n8n 示例:搭建 DeepSeek 客服分流工作流
场景与步骤概览
场景:对新进支持邮件进行分类,并路由到合适团队。大致步骤:
- 添加 Gmail Trigger 或 Webhook Trigger
- 抽取邮件主题、发件人和正文
- 添加 Chat DeepSeek 节点或 HTTP Request 节点
- 发送结构化分类提示词
- 要求严格 JSON 输出
- 解析 JSON
- 根据
category和urgency路由 - 在 Zendesk、HubSpot、Linear 或 Jira 中创建工单
- 对紧急问题发送 Slack 通知
- 在 Google Sheets、Airtable 或 Postgres 中存储结果
- 在对外发送任何回复前加入人工审批
n8n 的 DeepSeek 凭据使用 API Key 认证,官方文档会引导用户前往 DeepSeek API 文档查看服务细节。
n8n 示例 Prompt
You are a support operations classifier.
Return only valid JSON.
Classify this inbound customer email and produce the following fields:
- category: one of ["billing", "technical_issue", "account_access", "feature_request", "cancellation", "other"]
- urgency: one of ["low", "medium", "high", "critical"]
- sentiment: one of ["positive", "neutral", "frustrated", "angry"]
- summary: short plain-English summary
- suggested_reply: concise draft reply
- escalate_to_human: true or false
Rules:
- Set escalate_to_human to true if the email mentions legal threats, payment disputes, data loss, security, cancellation, or angry sentiment.
- Do not invent account details.
- Keep suggested_reply under 120 words.
Email subject: {{ $json.subject }}
Email body: {{ $json.body }}
示例 JSON 输出
{ "category": "billing", "urgency": "high", "sentiment": "frustrated", "summary": "Customer says they were charged twice and wants an immediate refund.", "suggested_reply": "Thanks for reaching out. We’re sorry for the billing issue. I’m escalating this to our billing team so they can review the duplicate charge and follow up with the next steps.", "escalate_to_human": true }
常见问题排查
如果 JSON 解析失败,可以按这个顺序排查:
- 提示词里是否明确包含“JSON”
- 输出是否被截断(
max_tokens是否过小) - 是否正确设置了
response_format={"type":"json_object"}
DeepSeek 的 JSON 输出指南建议:提供示例 JSON 结构、提高 max_tokens 以避免截断。如果回复太空泛,可以在提示词中加入“好示例 / 坏示例”;如果路由不稳定,减少类别数量;如果紧急问题被漏判,就把升级规则写得更具体,比如列出更多关键字。
Make 示例:用 DeepSeek 做线索资格评估
场景与步骤概览
场景:对表单新线索进行资格评估,并更新到 CRM。流程可以这样拆:
- 使用 Typeform、Fillout、Tally 或 Webflow 的表单触发器
- 把线索数据映射到 DeepSeek AI 模块
- 让 DeepSeek 评估线索匹配度并推荐下一步动作
- 解析 JSON 响应
- 更新 HubSpot、Pipedrive、Salesforce 或 Airtable
- 生成个性化跟进邮件草稿
- 在 Slack 通知对应销售
- 对低置信度或高价值线索发送到人工复核
Make 的 DeepSeek AI 集成支持 Chat Completion、余额查询、模型列表和自定义授权 API 调用,足够覆盖大多数线索处理场景。
Make 示例 Prompt
Return only valid JSON.
You are a B2B SaaS lead qualification assistant.
Evaluate this lead: Company: {{company}} Industry: {{industry}} Company size: {{company_size}} Job title: {{job_title}} Message: {{message}} Budget: {{budget}} Timeline: {{timeline}}
Return: { "lead_score": 0-100, "fit": "poor" | "moderate" | "strong", "reason": "short explanation", "next_best_action": "book_demo" | "send_resources" | "manual_review" | "disqualify", "personalized_email_draft": "short email", "confidence": 0-1 }
Rules:
- Score higher if company size, budget, and timeline match an enterprise SaaS buyer.
- Set next_best_action to manual_review if confidence is below 0.7.
- Do not overstate product capabilities.
示例 JSON 输出
{ "lead_score": 82, "fit": "strong", "reason": "The lead is a decision-maker at a mid-market company with an active budget and near-term timeline.", "next_best_action": "book_demo", "personalized_email_draft": "Hi Sarah, thanks for sharing your automation goals. Based on your timeline and team size, a short demo would be the fastest way to map the right workflow. Would Tuesday or Wednesday work for you?", "confidence": 0.84 }
Make 场景的实践建议
在 Make 里,比较稳妥的做法是:
- 把线索评分、CRM 更新、Slack 通知、邮件草稿拆成独立模块
- 用过滤器按
confidence、fit、lead_score做分支 - 对高价值或低置信度线索强制人工复核
- 把原始 AI 输出和解析后的字段都存下来,方便审计和回溯
有团队在这样改造后,销售每天手动筛选线索的时间从 1 小时降到 15 分钟,且漏掉的优质线索明显减少。
基于 API 的 DeepSeek 自动化架构
什么时候需要自建后端 / 代理?
当你需要更强的安全控制、日志记录、多模型路由或复杂业务逻辑时,自建后端或 API 代理会更合适。一个重要原则是:不要在前端、浏览器脚本、公开客户端应用或共享无代码空间里暴露 DeepSeek API Key,而是统一通过安全后端转发请求。
一个合格的后端通常需要:
- 接收 Webhook 事件
- 校验请求签名
- 对敏感字段做脱敏或删除
- 在服务端调用 DeepSeek
- 验证 JSON 输出结构
- 应用业务规则
- 记录请求 ID、token 使用量、错误和决策
- 对失败调用做安全重试
- 必要时切换到备用模型
- 把结构化结果返回给自动化平台
Python 伪代码示例
import os import json from openai import OpenAI from flask import Flask, request, jsonify
app = Flask(name)
client = OpenAI( api_key=os.environ["DEEPSEEK_API_KEY"], base_url="https://api.deepseek.com" )
@app.post("/webhooks/support-classifier") def classify_support_ticket(): payload = request.json or {}
subject = payload.get("subject", "")
body = payload.get("body", "")
if not body:
return jsonify({"error": "Missing email body"}), 400
prompt = f"""
Return only valid JSON.
Classify this support email: Subject: {subject} Body: {body}
Fields: category, urgency, sentiment, summary, suggested_reply, escalate_to_human """
try:
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "You are a support workflow classifier. Return valid JSON only."},
{"role": "user", "content": prompt}
],
response_format={"type": "json_object"},
max_tokens=600
)
content = response.choices[0].message.content
result = json.loads(content)
required = ["category", "urgency", "sentiment", "summary", "suggested_reply", "escalate_to_human"]
for field in required:
if field not in result:
return jsonify({"error": f"Missing field: {field}"}), 422
return jsonify(result), 200
except json.JSONDecodeError:
return jsonify({"error": "Model returned invalid JSON"}), 422
except Exception:
return jsonify({"error": "Internal processing error"}), 500
这种代理模式在“业务团队用无代码搭流程,但生产 AI 调用仍需工程把关”的组织里尤其有用。你可以在代理层统一做脱敏、审计和风控,而不是把这些责任分散到每一个场景里。
DeepSeek 与 OpenAI / Claude / Gemini / 本地模型的对比
选模型看“工作流”,不是看“品牌”
模型好不好用,关键看它要完成的那条工作流,而不是 Logo。OpenAI 通过函数调用和 Schema 响应支持结构化输出;Anthropic 的 Claude 提供工具使用机制,由客户端执行工具逻辑;Google Gemini 则有函数调用和结构化输出能力,适合接 API 和现实世界动作。
对很多企业来说,DeepSeek 的吸引力在于经济性和架构兼容性:可以接入现有自动化栈,而不用推倒重来。对受监管企业而言,真正的问题往往是:“哪个模型在我们的数据、法律、合规和安全政策下是可接受的?”而不是“哪个模型最聪明?”。
我也不太确定这个判断是不是放之四海皆准,但从最近不少企业的实践看,越来越多团队在做的是“多模型路由 + 风险分级”,而不是押注单一供应商。
安全、隐私与合规注意事项
数据流向与监管风险
设计 DeepSeek 工作流自动化时,隐私和治理要从一开始就考虑进去。DeepSeek 的隐私政策提到:为提供服务,DeepSeek 会在中华人民共和国境内直接收集、处理和存储个人数据,且个人数据可能被存储在用户所在国家之外;数据会在提供服务、履行合同、法律义务、合法商业目的、安全和法律主张等需要的期间内保留。
路透社报道过多国政府和监管机构对 DeepSeek 的审查,包括隐私监管调查、应用商店下架请求、政府设备使用限制和跨国调查等。这些都意味着:在把 DeepSeek 接入业务系统前,必须和法务、合规、安全团队对齐风险边界。
业务侧的防护措施
在业务自动化中,可以采用这些防护:
- 未经法务与合规评估,不要发送高度敏感数据
- 在发送前对个人数据做脱敏或替换
- 使用后端代理,而不是在前端暴露 API Key
- 把密钥存放在安全的密钥库或环境变量中
- 为工作流用户设置最小必要权限
- 为 AI 生成的关键决策添加审计日志
- 在执行动作前验证模型输出的合理性
- 对退款、法律问题、账户关闭、医疗、金融、HR、合规相关决策强制人工审批
- 审查数据驻留和跨境传输要求
- 建立模型与供应商风险台账,定期复盘
AWS 的生成式 AI 安全指南也提醒:要关注隐私、治理、幻觉、数据投毒、对抗性提示和 Agent 安全等风险,并尽量避免不必要的机密数据暴露,尽早让合规团队参与设计。
打造可靠 DeepSeek 自动化的实践要点
让工作流“可预期、可验证、可观测”
可靠的工作流有三个特征:目标明确、结果可验证、运行可观测。可以参考下面这些做法:
- 从一个清晰的工作流开始:不要试图一次性自动化整个部门
- 使用结构化提示词:明确角色、任务、输入、输出字段和规则
- 强制 JSON 输出:下游自动化应该解析字段,而不是读自然语言段落
- 验证每一次响应:检查必填字段、类型、枚举值和置信度
- 加入重试与降级策略:处理 API 错误、限流和格式错误输出
- 使用置信度评分:把不确定的案例路由给人工
- 区分低风险与高风险工作流:草拟内容比自动发送安全得多
- 让稳定提示词更易缓存:把系统规则和动态数据分开
- 监控成本:跟踪 token 使用量和每条工作流的成本
- 衡量业务效果:关注解决率、节省时间、错误率、升级率、单次运行成本和用户满意度
目标不是让 AI 完全接管,而是把重复步骤交给机器,把真正需要判断的部分留给人。一个运营负责人曾说,他们的原则是:“AI 负责搬砖,人负责拍板”。
常见错误与避坑
典型踩坑清单
在构建 DeepSeek 工作流自动化时,常见错误包括:
- 一上来就想自动化所有流程
- 让 AI 在无人审核的情况下发送敏感客户消息
- 不做 JSON 验证就直接执行动作
- 忽视模型幻觉和错误推断
- 使用已经过时的模型名称
- 忘记
deepseek-chat和deepseek-reasoner即将废弃 - 不必要地发送机密数据
- 搭建没有日志和审计的工作流
- 把 DeepSeek 当成完整自动化平台,而不是栈中的一个模型组件
- 不测试边界情况和异常输入
- 忽略隐私、合规和区域数据要求
- 上线后不监控成本和错误率
一个好的自动化应该“安全失败”:当模型不确定或输出异常时,流程会停止、打标并请求人工介入,而不是悄悄做出高风险决策。
DeepSeek 工作流自动化上线前检查清单
上线前逐项过一遍
在把工作流推到生产环境前,可以用这份清单做一次总检查:
- 明确工作流目标
- 选定触发器
- 选择自动化平台
- 选择合适的 DeepSeek 模型
- 定义输入数据
- 对敏感字段做脱敏
- 写好结构化提示词
- 要求 JSON 输出
- 验证响应结构和字段
- 添加后续动作节点
- 为高风险步骤添加人工审核
- 存储日志
- 记录 token 使用量
- 测试边界情况
- 测试异常和脏数据输入
- 测试愤怒客户、法律威胁、退款和安全问题等极端场景
- 添加重试逻辑
- 添加降级与备用模型处理
- 复核隐私与合规要求
- 上线后持续监控性能和成本
很多团队会把这份清单做成内部模板,每上线一个新工作流都过一遍,久而久之,自动化质量会稳定在一个比较高的水平。
收尾:把这套方法当成“长期工具箱”
DeepSeek 可以成为现代工作流自动化栈里的关键一环,尤其适合需要结构化输出、长上下文、工具调用和成本可控的团队。但它本身不是一个完整的自动化平台,而是要和工作流构建器、后端服务、CRM、工单系统、数据库或内部 API 搭配使用,才能发挥最大价值。
如果你正打算把 AI 引入业务流程,不妨先挑一个低风险的重复工作,按文中的思路搭一条小工作流:写好结构化提示词、强制 JSON 输出、验证每次响应、对高影响动作加人工审核、记录日志并监控成本。这套方法在不同团队里被反复验证有效,很值得收藏下来当作“自动化设计清单”。
当你下次面对“要不要把这条流程交给 AI”的选择时,翻回来看一眼,往往比随口问同事更靠谱。
常见问题
Q:如何判断一条业务流程适合用 DeepSeek 做自动化?
A:可以优先选择“高频、规则相对清晰、出错成本不致命”的流程,比如工单打标签、邮件摘要、线索初筛等。原因在于这类任务对结构化输出要求高,但对极致准确性要求没那么苛刻,适合用 JSON 输出 + 人工抽检的方式逐步优化。具体做法是:先统计这条流程每周的处理量和耗时,再用小样本试跑 DeepSeek 工作流,对比准确率和节省时间,如果效果稳定且错误可控,再逐步扩大覆盖范围。
Q:DeepSeek 的 JSON 输出不稳定时,应该怎么提高成功率?
A:可以从提示词、参数和后处理三方面入手。先在提示词中明确写出“只返回合法 JSON”,并给出完整的 JSON 示例结构;同时在 API 调用中设置 response_format={"type":"json_object"},并把 max_tokens 调高,避免输出被截断。原因是模型在没有强约束时容易夹带解释性文字或少括号。操作建议是:在后端或自动化平台里增加 JSON 校验逻辑,一旦解析失败就重试或降级到人工处理,并记录失败样本,用来迭代提示词。
Q:在安全和合规上,用 DeepSeek 需要特别注意什么?
A:关键是搞清楚“哪些数据可以发给模型,哪些绝对不能”。DeepSeek 的隐私政策提到数据会在中国境内处理和存储,这对某些行业和地区的合规要求是敏感点。判断依据包括:所在国家/地区的数据出境法规、行业监管要求、客户合同条款等。可操作建议是:和法务、合规、安全团队一起制定一份“可发送字段白名单”和“必须脱敏字段清单”,所有工作流都按这份清单执行,并通过后端代理统一做脱敏和审计。
Q:已经在用 OpenAI / Claude 的工作流,迁移到 DeepSeek 要注意什么?
A:迁移时要同时关注接口兼容性和行为差异。虽然 DeepSeek 提供 OpenAI/Anthropic 兼容接口,但模型在风格、长度控制、工具调用细节上会有差别。原因在于不同模型的对齐方式和训练数据不同,同一提示词可能产生不同输出。建议做法是:先在后端加一层模型路由,把 DeepSeek 作为“影子模型”并行调用,对比 JSON 结构、字段分布和业务指标;确认稳定后,再逐步把部分流量切到 DeepSeek,同时更新监控和告警阈值。
Q:如何衡量一条 DeepSeek 自动化工作流是否“值得长期保留”?
A:可以从“节省时间、错误率、用户体验和成本”四个维度综合评估。直接回答是:如果它在连续几周内稳定节省了可观的人力时间,错误率低于人工基线,且单次运行成本可接受,就值得长期保留。判断依据包括:平均处理时长、人工介入比例、关键错误数量、用户满意度评分和每次运行的 token 成本。操作建议是:为每条工作流设定明确的 KPI(例如每周节省工时、误分单率上限),达标的继续优化,长期达不到的要么重构要么下线,避免“僵尸自动化”占用维护资源。


