99% 的公司在上马 AI 时,都犯了同一个错误:先把数据丢进聊天框,再想安全和合规。你以为“试试又不花多少钱”,结果真正昂贵的,往往是数据泄露、错误决策和监管风险。DeepSeek 的确便宜又强大,但要让它成为生产力,而不是隐患,需要一套更精细的用法。
DeepSeek for business 指的是在企业各类场景中使用 DeepSeek AI 模型:客服回复、销售研究、营销内容、文档分析、软件开发、内部知识搜索和业务自动化等。企业可以通过聊天界面、API 接口,或自建开源权重模型来接入,选择取决于预算、技术能力和隐私要求。
据公开资料,DeepSeek 的 V4 系列在推理和编码上表现突出,API 价格相对较低,并支持 100 万上下文长度、JSON 输出、工具调用等特性。也正因为门槛不高,很多团队会冲动“全员上 AI”,忽略了数据分级、人审流程和密钥安全,这才是真正的高风险操作。
如果把 DeepSeek 当成一个“会写字的搜索框”,你大概率会失望;把它当成一名需要培训、需要监管的新人同事,反而更容易用出价值。
下面这份指南,会从使用方式、典型场景、落地步骤、小企业玩法,到 API 集成、安全与合规风险,一步步拆开讲清楚。
什么是 DeepSeek 商业应用?
DeepSeek 商业应用,说白了就是:把 DeepSeek 模型嵌进企业的日常工作流里,而不是只当一个“聊天玩具”。可能是创始人用 DeepSeek Chat 写邮件,也可能是市场团队用它把产品要点改写成落地页文案,或是开发用 API 做代码审查,甚至是技术团队自建开源权重模型,放在内网里跑。
三种典型接入方式
企业使用 DeepSeek,常见有三条路:
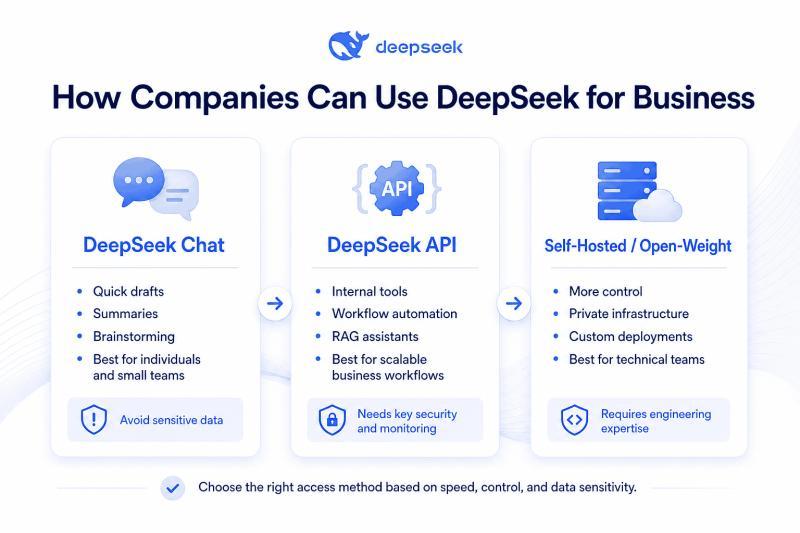
一是直接用官方聊天界面,适合个人效率提升和低风险内容创作;二是通过 API 接入,把 DeepSeek 嵌进现有系统和业务流程;三是下载开源权重,自建部署在自家服务器或云环境中,换取更高的可控性和数据掌控力。很多人误以为“DeepSeek 商业版”是一个完整的企业套件,其实更多时候,它指的是“用 DeepSeek 做企业级用途”。
DeepSeek 的开放平台条款明确:API 和开发者工具适用于个人开发者和企业开发者,且开发者需要对下游系统、终端用户管理、数据处理和合规负责。这意味着,一旦你把 DeepSeek 接进自己的产品或内部系统,责任不再只在供应商,而是你和它一起扛。
DeepSeek 模型与特性概览
从官方文档看,目前主推的模型是 deepseek-v4-flash 和 deepseek-v4-pro,支持 1M 上下文、JSON 输出、工具调用、前缀补全和 FIM 等能力。V4-Pro 更偏向“智能代理 + 编码 + 推理”,V4-Flash 则主打“更快更便宜,但推理能力接近 Pro”。
有用户反馈,在代码调试、SQL 编写、长文档总结等任务上,V4-Pro 的稳定性和细节把握更好,而 V4-Flash 更适合高并发、批量处理的场景,比如大规模文本分类或摘要。这些差异,直接影响你后面怎么选模型、怎么控成本。
为什么越来越多公司考虑用 DeepSeek?
很多团队在评估 DeepSeek 时,会拿它和 ChatGPT、Claude、Gemini 做对比。说实话,单看“聪明程度”,差距没想象中那么大,真正拉开差距的,是价格结构、API 兼容性和部署灵活度。
1. 成本优势:更适合做大规模试验
根据 DeepSeek 官方定价页(2026 年 5 月查看),deepseek-v4-flash 的缓存未命中输入价格为每 100 万 tokens 0.14 美元,输出为每 100 万 tokens 0.28 美元;deepseek-v4-pro 在 2026 年 5 月 31 日前有折扣价。官方也提醒价格可能调整,需要定期查看。
对企业来说,这不是小数目。有一位做客服机器人的负责人分享,他们用其他厂商模型做试点时,月账单一度冲到五位数美元,项目被财务直接叫停。换到 DeepSeek 后,在同等请求量下成本下降了约 40%,才有空间继续优化流程、打磨体验。
2. 推理与编码能力:更像“技术同事”
DeepSeek 官方把 V4-Pro 定位为“智能体能力 + 编码 + 世界知识 + 推理”的综合模型,而 V4-Flash 则是更快、更省钱的版本,推理能力接近 Pro。两者都可以通过 API 调用。
这让它在以下任务上很实用:调试代码、写 SQL、做代码审查、生成技术文档、设计测试用例、总结技术讨论记录等。有开发团队反馈,用 DeepSeek 做代码走查时,能帮他们发现一些边界条件和安全隐患,虽然不能替代人工 code review,但能明显减少重复劳动。
3. API 兼容:迁移成本低
DeepSeek 声称其 API 与 OpenAI、Anthropic 的格式兼容,很多基于 SDK 的现有工作流,只需要改 base URL、API Key 和模型名,就能跑起来。当前 API 文档中,deepseek-v4-flash 和 deepseek-v4-pro 是主推模型,而旧的 deepseek-chat 和 deepseek-reasoner 已标注将在 2026 年 7 月 24 日弃用。
对已经有 ChatGPT 或 Claude 原型的团队,这意味着迁移成本更像是“配置调整”,而不是“重写一遍系统”。
4. 长上下文:大文档场景更友好
V4 预览发布中提到,1M 上下文已成为官方服务的默认配置,定价页也列出了当前 V4 模型支持 1M 上下文。
这对企业很关键:长合同、政策手册、客户反馈导出、代码仓库、技术规格书、多轮分析任务,都可以直接丢进去,而不用再手动切片到崩溃。当然,长上下文不等于“永远不出错”,只是减少了你在文档拆分和拼接上的体力活。
5. 开源权重:自建部署的可能性
DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 已在 Hugging Face 上开源,模型卡中写明仓库和权重采用 MIT 许可证。
对有技术团队的公司来说,这意味着可以在内网或自有云上自建部署,做私有化测试、微调实验和更细粒度的访问控制。不过,自建大模型绝不是“下载即用”,你需要算力、安全、监控、服务框架和持续运维能力,否则很容易变成一堆昂贵的 GPU 在“烤空气”。
各部门的 DeepSeek 商业场景
从风险角度看,最适合先试水的,是低敏感度、低风险的场景,比如营销草稿、公开信息研究总结、内部模板、岗位说明、通用 SOP 等。最危险的,是涉及客户个人信息、受监管记录、保密合同、财务数据、核心源代码或商业战略的内容。
很多公司一开始就想“让 AI 看所有合同、所有代码”,听起来很爽,但一旦数据流向不清晰、权限控制不到位,后面补洞的成本会非常高。我自己的观察是:从“无敏感数据的内容生产”起步,成功率最高。
如何安全高效地用 DeepSeek:7 步落地路线

Step 1:只选一个具体业务问题
不要一上来就搞“全公司 AI 赋能”,先挑一个具体流程做试点。适合作为起点的项目包括:
- 根据已审批 FAQ 起草客服回复
- 把产品要点整理成营销文案草稿
- 总结公开的竞品研究资料
- 用非敏感流程笔记生成 SOP
- 帮开发解释报错信息或生成测试用例
尽量避开高敏感领域,比如法律意见、医疗数据、客户金融记录、保密并购文件等。这些场景后面可以做,但一定要在合规和安全方案成熟之后。
Step 2:给数据做“敏感度分级”
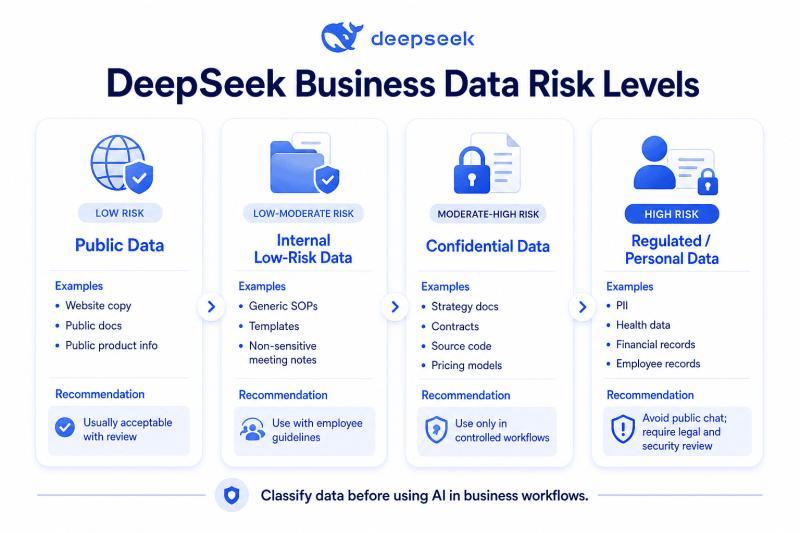
在把任何企业数据交给 DeepSeek 之前,先搞清楚:它属于哪一类数据?
一个常用的分级方法是:公开数据、内部普通数据、机密数据、受监管数据。DeepSeek 的隐私政策写明,个人数据可能包括用户输入内容,且用户有权选择不将个人数据用于模型训练或技术优化;同时也说明个人数据会在中华人民共和国境内处理和存储。
对跨境业务或受监管行业,这一点非常关键:你需要确认数据跨境、数据存储位置是否符合本地法规和客户合同要求。
Step 3:在 Chat、API、自建部署之间做选择
简单、低风险的效率类任务,用官方聊天界面就够了,比如写邮件、改写文案、整理会议纪要等。需要可重复、可审计的流程时,就该上 API:你可以加日志、脱敏、用户权限、提示词模板,并和现有业务系统打通。
自建部署开源权重,只适合有一定基础设施和安全能力的团队。你要能搞定访问控制、网络隔离、日志管理、模型更新和故障恢复,否则自建不但不更安全,反而多了很多攻击面。
Step 4:设计“业务级提示词”和工作流
一个合格的业务提示词,至少要包含:角色、任务、上下文、来源材料、输出格式和质量规则。比如客服场景,可以这样写:
你是一名客服专员。请只根据下面提供的已审批 FAQ,为客户起草一封友好的回复。不要编造任何政策细节。如果 FAQ 无法回答客户问题,请明确说明需要升级给人工客服处理。输出格式:邮件主题、简短回复正文、升级说明。
很多团队一开始提示词写得很随意,结果模型输出风格飘忽不定,员工也不知道该怎么审。把角色、边界和输出格式写清楚,其实就是在给 AI 立规矩。
Step 5:加上人工审核和质量把关
DeepSeek 开放平台条款中明确提到,AI 生成内容可能包含错误或遗漏,尤其在法律、医疗、金融等专业领域,只能作为参考。
对企业来说,这意味着:凡是会影响客户体验、品牌形象、财务结果或合规风险的输出,都必须有人审。可以按风险分级:低风险内容抽检,高风险内容必审,并记录修改意见,反向优化提示词和流程。
Step 6:衡量 ROI 和准确率
很多 AI 项目“看着很酷”,但到底值不值钱,得用数据说话。可以跟踪的指标包括:
- 人均处理工单数量变化
- 内容产出周期缩短比例
- 一次性解决率(FCR)变化
- 人工审核修改率
- 模型调用成本 / 每单成本
有团队在客服场景中统计发现,引入 DeepSeek 草稿后,客服平均响应时间缩短了 35%,但人工修改率一开始高达 60%。他们据此调整 FAQ 结构和提示词,三周后修改率降到 30% 以下,才算进入“可持续”状态。
Step 7:在治理框架下扩展到更多团队
当一个试点跑顺了,就可以考虑扩展。但扩展前,需要先搭好“护栏”:
- 制定公司级 AI 使用规范
- 列出允许和禁止的使用场景
- 统一提示词模板和知识来源
- 设计审核流程和责任人
- 配置 API 安全策略和访问控制
- 建立监控看板,跟踪成本、质量和异常
这样做的好处是:新团队接入时,有现成的“安全轨道”可用,而不是每个部门都重新踩坑。
中小企业如何用 DeepSeek 省钱又省力?
很多小公司最缺的不是点子,而是“有人帮忙写、有人帮忙整理”。DeepSeek 在这里很适合作为“多功能助理”:写产品描述、回客户邮件、做社媒日历、总结客户反馈、整理 FAQ、分析简单表格、把重复流程写成文档等。
关键原则只有一条:别把敏感数据往公开聊天框里扔,把它当“助手”,而不是“拍板的人”。
小企业最值得尝试的 DeepSeek 工作流
对小团队来说,一个简单好记的规则是:
- 让 DeepSeek 负责:草稿、结构、摘要、灵感
- 让人类负责:最终判断、对客户的承诺、法律条款、财务决策
有一位电商老板分享,他用 DeepSeek 先生成 10 个产品标题和卖点,再自己挑 2–3 个改一改,单品转化率提升了约 8%。但退款政策、售后承诺,他坚持自己写,因为“这玩意写错了,赔的是钱和口碑”。
DeepSeek 企业级:API、集成与自动化
当你不满足于“人手一台聊天框”,就该考虑用 API 把 DeepSeek 接进系统里,让它成为 CRM、工单系统、内部工具的一部分。官方文档显示,开发者可以申请 API Key,使用 OpenAI 风格或 Anthropic 风格的接口,调用 deepseek-v4-flash 和 deepseek-v4-pro 等模型。
API Key 安全基础
API Key 是你的应用访问 DeepSeek 的“通行证”,一旦泄露,就等于别人可以替你刷账单。开放平台条款要求用户妥善保管密钥,不得公开分享或暴露在浏览器端代码中。
更安全的做法包括:
- 把 API Key 存在专门的密钥管理服务中
- 禁止把密钥提交到 GitHub 等代码仓库
- 不在前端 JavaScript 中硬编码密钥
- 员工离职或怀疑泄露时,立即轮换密钥
- 开发、测试、生产环境使用不同密钥
- 监控调用量,发现异常峰值及时排查
模型选择策略
可以简单理解为:

deepseek-v4-flash:更便宜、更快,适合分类、抽取、摘要、简单客服草稿等高频任务deepseek-v4-pro:推理更强,适合复杂规划、编码、决策支持等高价值场景
新项目尽量不要再用即将弃用的旧模型名(如 deepseek-chat、deepseek-reasoner),避免未来迁移成本。
利用上下文缓存降本提速
DeepSeek 文档中提到的“上下文缓存”(KV Cache),可以在提示词前缀重复时,降低成本和延迟,比如:很长的系统提示、多轮对话、重复分析同一批文档、反复审查同一段代码等。
对企业来说,如果你每次调用都要带上同一份知识库或政策文本,就很适合用缓存机制,把“固定部分”变便宜。
工具调用与结构化输出
DeepSeek 的定价/模型页显示,当前 V4 模型支持 JSON 输出和工具调用。
这对自动化非常关键,因为业务系统往往需要结构化结果,而不是一大段自然语言。例如:
{ "customer_intent": "refund_request", "priority": "medium", "recommended_action": "send_refund_policy" }
有了结构化输出,你就可以根据字段自动分配工单、触发工作流,而不是再让人去读一遍 AI 的长段文字。
RAG:让 DeepSeek “只用你给的资料说话”
在企业里,一个常见架构是 RAG(检索增强生成)。不是指望模型“自己懂你公司”,而是先从知识库里检索相关文档,再让 DeepSeek 只基于这些文档回答。
一个简化版架构可以是:
业务应用 → 安全后端 → 文档检索 → DeepSeek API → 人工审核 / 看板
这种方式特别适合:客服知识库、内部制度查询、入职助手、开发文档问答、销售话术支持等场景。好处是:知识可控、可更新,回答范围也更容易被约束。
日志与监控:别让 AI 成为“黑盒”
使用 DeepSeek API 的公司,至少要监控这些维度:
- 提示词与回复质量(可抽样人工评估)
- 各团队或各工作流的 API 成本
- 错误率和超时情况
- 员工反馈的“幻觉”案例
- 安全事件和异常调用
- 违反内部政策的使用行为
如果需要记录提示词和回复内容,一定要先和法务、安全团队确认,避免在日志中长期保存敏感数据。
各业务团队可直接套用的提示词示例
1. 客户支持
Prompt:
You are a customer support specialist. Your task is to draft a helpful reply to a customer complaint. Context: use only the approved policy text below. Output format: subject line, reply, and escalation note. Quality constraints: do not invent refund terms, do not promise compensation, and escalate if the policy does not answer the issue.
2. 市场营销
Prompt:
You are a B2B SaaS copywriter. Create a landing page outline for [product] targeting [audience]. Context: [features, benefits, objections]. Output format: headline, subheadline, sections, CTAs, and FAQ ideas. Quality constraints: avoid hype, avoid unsupported claims, and keep the tone professional.
3. 销售拓客
Prompt:
You are a sales development representative. Draft a personalized cold email to [buyer persona] at [company type]. Context: [public company notes] and [offer]. Output format: subject line plus email under 120 words. Quality constraints: no fake familiarity, no exaggerated ROI, and include one clear CTA.
4. 会议纪要
Prompt:
You are an executive assistant. Summarize these meeting notes into decisions, action items, owners, deadlines, risks, and unresolved questions. Output format: table. Quality constraints: do not add items that are not in the notes.
5. 表格分析
Prompt:
You are a business analyst. Analyze this anonymized sales table. Identify trends, anomalies, and five follow-up questions. Output format: summary, observations, risks, and recommended next analysis. Quality constraints: do not infer customer identities or make unsupported financial forecasts.
6. 竞品研究
Prompt:
You are a market research analyst. Compare these public competitor pages. Output format: positioning, pricing signals, messaging themes, strengths, weaknesses, and opportunities. Quality constraints: use only the provided source text and label assumptions clearly.
7. SOP 生成
Prompt:
You are an operations manager. Turn these notes into a standard operating procedure. Output format: purpose, scope, tools needed, steps, quality checks, and escalation rules. Quality constraints: use plain English and flag missing information.
8. 代码审查
Prompt:
You are a senior software engineer. Review this code for readability, bugs, security risks, and test coverage. Output format: summary, issues by severity, suggested fixes, and test cases. Quality constraints: do not rewrite the entire file unless requested.
9. 管理决策简报
Prompt:
You are a strategy advisor. Create a one-page decision brief about [decision]. Context: [facts, constraints, options]. Output format: recommendation, options considered, pros, cons, risks, assumptions, and next steps. Quality constraints: separate facts from assumptions.
DeepSeek 带给企业的核心价值
降低 AI 试验门槛
DeepSeek 的价格结构,让很多团队可以先做小规模、可控的实验,而不用一开始就签高额企业合约。对初创公司和中小企业来说,这意味着可以先验证“AI 客服”“AI 营销”“AI 办公”到底有没有用,再决定要不要加大投入。
加速内容与研究流程
团队可以用 DeepSeek 生成初稿、总结研究资料、把技术内容翻译成非技术语言、把散乱的会议笔记整理成结构化输出。很多人会发现,真正花时间的不是“写第一版”,而是“从零开始想结构”,而这正是模型擅长的部分。
提升开发效率
在研发侧,DeepSeek 可以帮忙解释报错、生成测试、做代码审查、写文档、设计调试步骤。它不能替代安全审计和正式 code review,但能显著减少重复性工作,让高级工程师把时间花在更关键的设计和评审上。
支撑自动化与智能功能
借助 API、JSON 输出、工具调用和工作流集成,企业可以把 AI 能力嵌入 CRM、工单系统、看板、文档平台和内部工具中。比如:自动给工单打标签、根据客户意图触发不同流程、从长文档中抽取关键字段等。
支持长文档分析
官方文档中提到的 1M 上下文,让 DeepSeek 在大文档场景下更有优势。合同审阅、政策比对、技术方案评估,都可以在一轮对话中完成更多上下文关联分析,只是依然需要人工核对关键结论。
开源权重带来的灵活性
V4-Pro 和 V4-Flash 在 Hugging Face 上以 MIT 许可证开源,为技术团队提供了更多部署和实验选择。你可以在内网做性能对比、微调特定任务,甚至和其他模型组成“模型集群”,按任务动态路由。
风险、隐私与安全:企业必须看清的坑
DeepSeek 的价值不只取决于模型本身,更取决于你怎么管它。真正的大坑往往不是“模型不够聪明”,而是数据外泄、合规踩雷、员工误用和对 AI 输出的过度迷信。
敏感数据泄露风险
员工可能会把客户记录、合同、源代码、财务数据或战略文件直接粘进公开聊天工具,这会带来严重的保密和合规风险。
DeepSeek 的隐私政策写明,个人数据可能被用于改进和训练技术,并赋予用户选择不将个人数据用于训练或技术优化的权利;同时也指出个人数据会在中国境内处理和存储。对有数据本地化要求或跨境限制的企业,这一点必须纳入供应商风险评估。
监管与政府审查
据路透社报道,澳大利亚曾禁止在政府设备上使用 DeepSeek,捷克在公共行政系统中禁用,德国曾要求苹果和谷歌因数据安全担忧下架 DeepSeek 应用,意大利也因隐私政策问题短暂封禁过该应用。
私营企业不必机械照抄政府禁令,但如果你所在行业监管严格(金融、医疗、公共服务等),就需要格外关注数据存储位置、供应商合规能力、员工访问控制和合同条款中的责任划分。
安全事件与供应商风险
2025 年 1 月,Wiz Research 报告称发现一个公开可访问的 DeepSeek 数据库,其中包含聊天记录、密钥、后端细节等敏感信息,并表示在负责任披露后,DeepSeek 已修复该暴露问题。
这并不意味着“所有 DeepSeek 部署都不安全”,但提醒我们:任何第三方 AI 供应商都可能出现安全事件,企业需要有自己的供应商评估流程、密钥管理策略和最小化数据暴露原则。
幻觉与错误输出
所有大模型都会“一本正经地胡说八道”。DeepSeek 的隐私政策也提示,模型生成的是“最可能的下一个词”,不保证事实准确,用户不应完全依赖其输出的真实性。
对企业来说,一个简单可行的做法是:
- 把模型输出视为“草稿”或“建议”,而不是“结论”
- 对高风险场景(法律、医疗、金融、合规)强制人工复核
- 对外发布前,要求员工标记“AI 参与生成”,内部可留痕
绝不能粘进公开 AI 聊天框的内容
无论是 DeepSeek 还是其他公开聊天工具,以下内容都不建议直接输入:
- 客户个人信息:姓名、电话、邮箱、地址、证件号、支付信息等
- 保密合同全文或关键条款
- 密码、账号、私钥、API Key 等凭证
- 原始财务记录和未披露报表
- 含有密钥或内部地址的源代码
- 医疗、法律、保险等受监管数据
- 员工人事档案和绩效信息
- 未公开的商业战略和投标方案
- 未发布的产品规划
- 并购、投资、董事会材料
什么时候不适合上 DeepSeek?
有些情况下,与其硬上,不如先停一停:
- 公司没有任何 AI 使用规范和培训
- 员工极有可能把敏感数据粘进公开聊天工具
- 业务对数据本地化有刚性要求,而 DeepSeek 无法满足
- 输出会被直接当作专业法律、医疗、金融意见使用
- 公司缺乏监控 API 使用和保护密钥的能力
- 工作流涉及受监管个人数据,但尚未通过法务审查
DeepSeek vs ChatGPT vs Claude vs Gemini:怎么选?
真正重要的不是“谁更火”,而是“谁更适合你的业务约束”。
- 想低成本做 API 实验、快速迭代原型:DeepSeek 很有吸引力
- 需要强合同保障、复杂合规条款:可能更偏向传统大厂或本地云厂商
- 内部系统高度依赖 Google 生态:Gemini 集成更顺手
- 内容创作占比极高、重视长文写作体验:很多团队会偏向 Claude
不少公司最后会选择“多模型共存”:不同场景用不同模型,并在网关层做统一审计和风控。
DeepSeek 商业落地检查清单
在把 DeepSeek 大规模推向全公司之前,可以对照这份清单逐项确认:
- 明确哪些场景允许使用 DeepSeek
- 明确哪些场景禁止使用 DeepSeek
- 制定公司级 AI 使用规范
- 对员工进行安全提示词与数据保护培训
- 在调用前对敏感数据做脱敏或删减
- 对可控场景优先采用 API 工作流,而非公开聊天
- 把 API Key 存入安全的密钥管理系统
- 禁止在前端或客户端代码中暴露密钥
- 对客户相关或高影响输出强制人工审核
- 持续监控调用成本、质量和错误率
- 由法务和合规团队审查相关流程和条款
- 评估数据存储位置与跨境传输的影响
- 维护统一的提示词模板和知识来源清单
- 定期抽查输出中的幻觉和错误
- 随着 DeepSeek 模型、价格和条款变化,及时更新工作流
小结与行动建议
如果你读到这里,大概率已经在考虑:要不要把 DeepSeek 真正接进业务,而不只是让几个人“玩一玩”。与其纠结模型孰强孰弱,不如先用这套 7 步路线,在一个小场景里跑通:选问题、分级数据、定接入方式、写好提示词、加人审、算 ROI、再扩展。
这套方法在不同公司反复验证过,只要守住数据和合规的底线,DeepSeek 能帮团队省下的时间和试错成本,远比 API 账单可观。等你真的要做更大规模的 AI 改造时,这些早期积累的经验,会比任何一场“趋势分享会”都更值钱。
如果你正站在“要不要上 DeepSeek”的十字路口,不妨先把这篇收藏下来,按清单做完一个小试点,再决定要不要加速前进。
常见问题
Q:企业用 DeepSeek 时,怎么快速判断一个场景适不适合先试?
A:先看两个维度:数据敏感度和业务风险。数据是否包含客户个人信息、财务数据、保密合同等高敏内容?输出是否会直接影响客户权益、法律责任或重大财务决策?如果两者都偏高,就不适合作为首批试点。更稳妥的做法是,从“公开信息 + 内部低敏数据”的内容生产和分析场景起步,比如营销草稿、公开竞品研究、内部培训材料等,再逐步向更复杂场景扩展,同时补齐合规和安全能力。
Q:DeepSeek 的数据在中国存储,会对跨国公司有什么影响?
A:影响主要体现在数据跨境合规和客户合同义务上。部分国家或行业对个人数据出境有严格限制,要求明确数据存储地点、处理方和用途。如果你的业务涉及欧盟、金融、医疗等高监管地区,就需要评估 DeepSeek 的数据处理方式是否符合当地法规,并在与客户的合同中清晰披露。可操作建议是:与法务团队一起审阅 DeepSeek 的隐私政策和开放平台条款,必要时限制只在低敏场景使用,或采用自建部署方案减少数据外流。
Q:怎么降低 DeepSeek 在企业使用中的“幻觉”和错误风险?
A:核心思路是“缩小自由度 + 强制人审”。一方面,通过 RAG 让模型只基于指定文档回答,提示词中明确“不得编造信息,如资料不足请说明”;另一方面,对高风险输出(如合同条款、政策解读、财务分析)设置人工审核为必经步骤。还可以建立“错误案例库”,把典型幻觉样例收集起来,反向优化提示词和流程。技术上,可以在系统中增加“置信度标记”或“需复核”标签,提醒使用者不要盲信模型输出。
Q:中小企业没安全团队,也能安全用 DeepSeek 吗?
A:可以,但要刻意把复杂问题简单化。做几件事就能显著降低风险:一是制定一页纸的“AI 使用红线”,明确禁止粘贴哪些数据;二是统一用一个公司账号或 API 网关管理调用,避免员工各自乱注册;三是把密钥放在云厂商的密钥管理服务中,而不是写在代码里;四是对外发出的 AI 内容,要求至少一人复核。没有安全团队时,更要避免自建大模型集群,把精力放在流程和培训上,比堆技术堆栈更有效。
Q:已经在用 ChatGPT 或 Claude 了,还有必要上 DeepSeek 吗?
A:要看你的目标是“多一个玩具”,还是“优化整体 AI 成本和能力组合”。DeepSeek 在价格和开源权重上有优势,适合高并发、成本敏感或需要私有化部署的场景;ChatGPT、Claude、Gemini 在生态、插件或特定任务上各有长处。更现实的做法,是把它们当作“模型池”,按任务选择最合适的模型,并在网关层统一做审计和风控。这样既能利用 DeepSeek 的成本优势,又不会放弃其他模型在特定领域的强项。


