 AI资讯
AI资讯SK海力士开始量产带宽提升一倍的192GB SOCAMM2 AI服务器内存
韩国SK海力士于4月20日宣布,正式开始量产面向下一代AI服务器的内存模块——192GB SOCAMM2。 该192GB SOCAMM2内存模块基于1cnm工艺(第六代10纳米级技术)的LPDDR5X DRAM,采用了原本用于移动设备的低功耗内存技术,经过优化后适用于服务器环境。与传统的RDIMM内存相比,SOCAMM2的带宽提升超过两倍,电力效率提升超过75%。 此外,该内存模块专为日本国家N
按标签聚合查看文章内容。
AI资讯韩国SK海力士于4月20日宣布,正式开始量产面向下一代AI服务器的内存模块——192GB SOCAMM2。 该192GB SOCAMM2内存模块基于1cnm工艺(第六代10纳米级技术)的LPDDR5X DRAM,采用了原本用于移动设备的低功耗内存技术,经过优化后适用于服务器环境。与传统的RDIMM内存相比,SOCAMM2的带宽提升超过两倍,电力效率提升超过75%。 此外,该内存模块专为日本国家N
 AI资讯
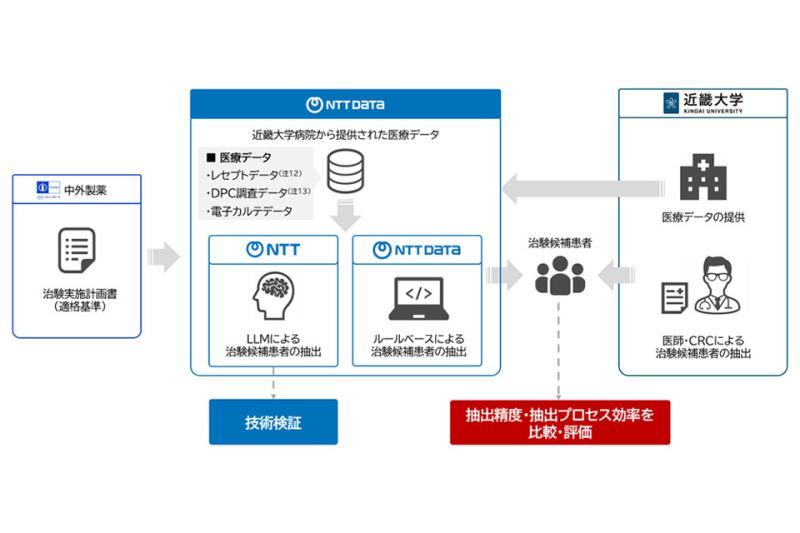
AI资讯日本近畿大学病院、中外制药、NTT及NTT数据公司联合开展利用真实世界数据和大规模语言模型提升临床试验候选患者筛选效率的研究。
 AI资讯
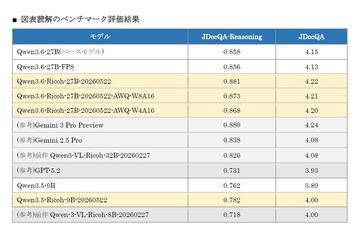
AI资讯日本NTT推出了升级版大规模语言模型“tsuzumi 2 Vision”,实现了对带图表文档的高精度读取和理解。
 AI资讯
AI资讯理光基于阿里巴巴云开发的大规模语言模型Qwen3.6-27B,推出了专注提升日语推理能力的多模态大规模语言模型,计划应用于企业级解决方案。
 AI资讯
AI资讯日本国家Sakana AI开发了试验模型系列“Namazu”(α版),该系列基于现有的前沿模型,专门调整以适应日本市场需求。同时,搭载“Namazu”α版的聊天服务“Sakana Chat”也已公开。 该公司利用开放权重基础模型,致力于研究开发满足各国文化、价值观及安全保障要求的模型后训练技术。然而,若直接使用海外开放模型进行后训练以满足日本用户需求,往往难以避免开发地区的意识形态和信息管控倾向
 AI资讯
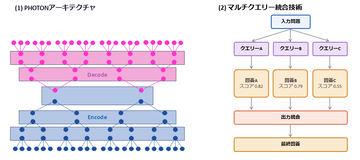
AI资讯日本国家富士通公司于6月24日宣布,开发出一种名为“Parallel Hierarchical Operation for TOp-down Networks”(简称PHOTON)的架构,能够在大规模语言模型(LLM)中实现显著的成本削减。 目前主流的Transformer模型在处理较长输入或同时应对大量查询时,因需频繁访问记忆以保持历史信息,导致处理速度下降。而PHOTON通过不再将文本拆分为
 AI资讯
AI资讯AI inside株式会社于13日宣布启动“Sovereign Grid”计划,该计划将在日本国内数据中心运营商的设施中部署专用的AI推理硬件和AI集成基础平台,并将其连接成AI推理网络。 “Sovereign Grid”通过在数据中心设施中安装硬件设备“AI inside Cube”,并在其上构建AI集成基础平台“Leapnet”。Leapnet负责将各个节点通过网络连接,构成“Sovereig
 AI资讯
AI资讯生成式AI的核心技术“LLM” LLM是“Large Language Model(大规模语言模型)”的缩写,是驱动ChatGPT、Gemini、Claude等生成式AI服务的核心技术。 这些服务并非仅由LLM构成,还结合了界面、语音输入、搜索、外部工具及安全措施等多种机制。而LLM则作为理解和生成文本的“引擎”,相当于生成式AI的“头脑”。 LLM的特点在于利用海量文本数据和强大计算资源进行训
 AI资讯
AI资讯ProTech AI-OCR服务通过引入大规模语言模型,实现了高精度的图像文字遮蔽技术,提升了非定型文件的处理能力。
 AI资讯
AI资讯日本GMO互联网株式会社、日本NTT东日本株式会社、日本NTT西日本株式会社及日本株式会社QTnet于3月30日宣布,已完成利用IOWN APN(全光网络)技术,在东京至福冈之间构建远程分布式AI基础设施的技术验证。 随着生成式AI和大型语言模型(LLM)的普及,AI开发基础设施的需求迅速增长。传统上,GPU与大容量存储设备必须物理邻近部署,但由于数据中心空间限制或企业希望在自有场所管理数据,亟
 AI资讯
AI资讯日本国家漏洞门户网站JVN于5月11日发布了编号为JVNVU#90880682的漏洞报告,指出开源本地运行大规模语言模型(LLM)工具“Ollama”存在边界外读取和写入漏洞(CVE-2026-5757)。 报告显示,“Ollama”的模型量化引擎在验证GGUF文件时存在缺陷,导致可读取或写入超出指定范围的堆内存。通过“Ollama”的注册表API,写入模型层的堆内存数据可能被泄露。 最严重的情
 AI资讯
AI资讯日本株式会社マクニカ于3月30日宣布,与美国Unstructured Technologies(以下简称Unstructured)签订了日本国内首个代理销售合同,正式开始提供能够自动将非结构化数据整理为大规模语言模型(LLM)易于处理格式的平台“Unstructured”。 随着LLM的普及,利用生成式AI进行知识检索和提升业务效率的需求日益增长,越来越多企业开始构建基于内部文档的RAG(检索增强