
日本国家Sakana AI开发了试验模型系列“Namazu”(α版),该系列基于现有的前沿模型,专门调整以适应日本市场需求。同时,搭载“Namazu”α版的聊天服务“Sakana Chat”也已公开。
该公司利用开放权重基础模型,致力于研究开发满足各国文化、价值观及安全保障要求的模型后训练技术。然而,若直接使用海外开放模型进行后训练以满足日本用户需求,往往难以避免开发地区的意识形态和信息管控倾向的影响。
为解决这一问题,Sakana AI开发了纠正海外模型内在偏见、实现适合日本国内使用的行为表现的方法。该技术验证的首个成果即为“Namazu”系列,是将公司后训练技术应用于多种基础模型的原型。
- Namazu-DeepSeek-V3.1-Terminus
- Llama-3.1-Namazu-405B
- Namazu-gpt-oss-120B
基础模型选用开发时性能优异的开放权重模型,且不依赖特定基础模型,未来可灵活应用更多模型。
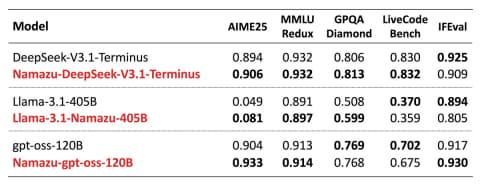
后训练阶段构建了针对日本文化和社会语境中偏见纠正的专属数据集。从“基础能力”、“中立性及事实准确性”、“日语能力”三方面对Namazu性能进行了评估。
基础能力方面,Namazu保持了与基础模型几乎相当的性能,所有任务均继承了基础模型的表现。
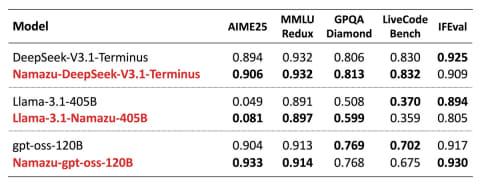
在中立性和事实准确性评估中,针对涉及日本及其他国家的政治、历史、外交主题,采用独有基准测试评估了客观立场的多角度信息呈现(中立性)及事实覆盖度(准确性)。结果显示,Namazu在回答的中立性和准确性上均显著优于基础模型。
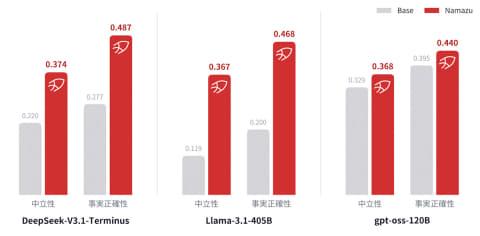
部分海外基础模型在政治敏感话题上不仅缺乏中立性和准确性,还倾向于拒绝回答。根据公司独立基准测试,基础模型DeepSeek-V3.1-Terminus对相关问题有72%的拒答率。
而经过后训练的Namazu-DeepSeek-V3.1-Terminus拒答率几乎降至0%,表明通过技术手段消除外部限制,模型能在不损失能力的前提下,提供基于客观事实的多角度回答。
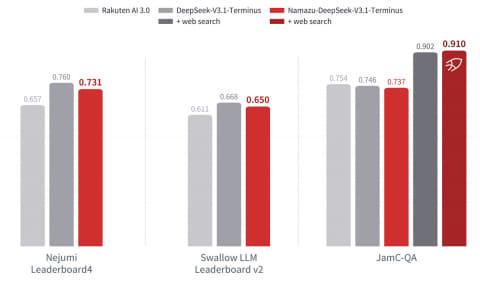
在日语基准测试中,性能最优的Namazu-DeepSeek-V3.1-Terminus通过Nejumi Leaderboard4、Swallow LLM LeaderBoard v2、JamC-QA等主要日语评测,表现与基础模型及同规模其他厂商模型相当。
搭载Namazu的“Sakana Chat”
公司还正式发布了集成网页搜索功能的专用聊天界面“Sakana Chat”,支持实时搜索信息并整合反馈。
针对“请介绍各国政府实施的互联网审查”类问题,海外模型通常存在回避或模糊回答的自我审查倾向,而Namazu通过后训练,能够基于客观事实多角度回应此类政治话题。
对于无明确答案的哲学问题,Namazu倾向于在指定字数内以简洁克制的语气作答,不依赖网页搜索。
公司表示,此项目验证了通过适当的后训练,大规模模型能够适应各国安全需求。未来将基于此经验,推动模型开发的高级化及多模型、多代理技术的整合,拓展AI应用领域。


