美国谷歌公司发布了一种名为“TurboQuant”的压缩算法,旨在解决大型语言模型(LLM)运行时大量内存消耗的问题。该算法通过向量量子化技术,将内存使用量降低至原来的六分之一。详细内容预计将在2026年4月23日召开的国际学习表征会议(ICLR 2026)上公布。
当前的人工智能技术通过向量来理解和处理语言、图像等信息。虽然向量技术强大,但它们会消耗大量内存。为了让计算机无需低速搜索庞大数据库即可快速获取信息,系统采用了键值缓存(KV缓存),类似于常用信息的备忘录。然而,由于数据库本身庞大,KV缓存也随之膨胀,成为内存消耗的瓶颈。
为此,向量量子化技术被引入,但传统量子化方法需要对每个小数据块计算量子化常数并完全保存,导致内存开销增加。每个数值额外增加1到2比特,部分抵消了向量量子化节省内存的初衷。
谷歌此次推出的TurboQuant算法采用了“QJL”算法和“PolarQuant”技术来解决这一问题。
QJL算法利用数学上的约翰逊-林登施特劳斯变换,将复杂的高维数据缩减,同时保持数据点间的重要距离和关系。最终,向量数值被缩减为单一符号位(+1或-1)。为了保持精度,QJL使用特殊的估计器在高精度查询和低精度简化数据之间取得平衡,能够准确计算注意力分数,即判断数据中重要部分和可忽略部分的过程。
PolarQuant技术则通过将传统的笛卡尔坐标(X/Y/Z)转换为极坐标来表示向量。例如,传统表达为“向东3格,向北4格”,而PolarQuant则表示为“以37度角前进5格”。这种方式用半径表示数据强度,角度表示数据方向或含义。
与传统不断变化的方形网格不同,PolarQuant将数据映射到固定且可预测的圆形网格,无需执行数据归一化,从而消除了内存开销。
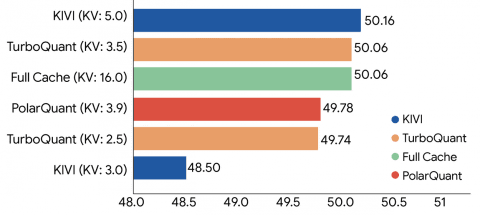
谷歌的测试显示,使用开源大型语言模型进行长上下文基准测试时,TurboQuant在点积失真和召回率方面均表现优异,同时将KV缓存的内存占用降至最低。此外,在设计用于检测大量文本中隐藏小信息的测试中,TurboQuant在不降低性能的情况下,将KV缓存大小至少减少至六分之一。
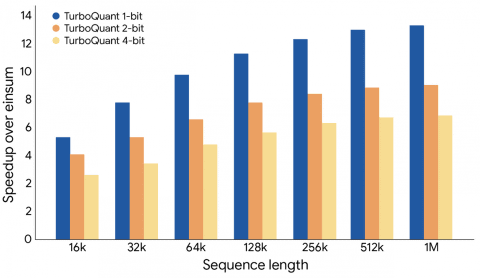
此外,TurboQuant无需训练或微调即可将KV缓存量子化至3比特,且4比特版本的TurboQuant相比未量子化的32比特键,性能提升最高达8倍。
谷歌指出,TurboQuant的主要应用之一是解决如日本国家谷歌的Gemini模型中KV缓存的瓶颈问题。随着现代搜索技术从简单关键词检索向理解意图和语义方向发展,TurboQuant在提升搜索效率和准确性方面发挥着重要作用。