 AI资讯
AI资讯谷歌推出TurboQuant算法,将大型语言模型运行时内存消耗降低至六分之一
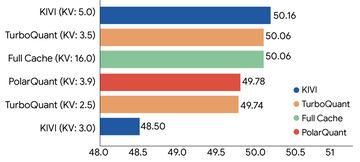
美国谷歌公司发布了一种名为“TurboQuant”的压缩算法,旨在解决大型语言模型(LLM)运行时大量内存消耗的问题。该算法通过向量量子化技术,将内存使用量降低至原来的六分之一。详细内容预计将在2026年4月23日召开的国际学习表征会议(ICLR 2026)上公布。 当前的人工智能技术通过向量来理解和处理语言、图像等信息。虽然向量技术强大,但它们会消耗大量内存。为了让计算机无需低速搜索庞大数据库
按标签聚合查看文章内容。
AI资讯美国谷歌公司发布了一种名为“TurboQuant”的压缩算法,旨在解决大型语言模型(LLM)运行时大量内存消耗的问题。该算法通过向量量子化技术,将内存使用量降低至原来的六分之一。详细内容预计将在2026年4月23日召开的国际学习表征会议(ICLR 2026)上公布。 当前的人工智能技术通过向量来理解和处理语言、图像等信息。虽然向量技术强大,但它们会消耗大量内存。为了让计算机无需低速搜索庞大数据库