 AI资讯
AI资讯谷歌推出TurboQuant算法,将大型语言模型运行时内存消耗降低至六分之一
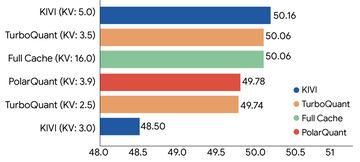
美国谷歌公司发布了一种名为“TurboQuant”的压缩算法,旨在解决大型语言模型(LLM)运行时大量内存消耗的问题。该算法通过向量量子化技术,将内存使用量降低至原来的六分之一。详细内容预计将在2026年4月23日召开的国际学习表征会议(ICLR 2026)上公布。 当前的人工智能技术通过向量来理解和处理语言、图像等信息。虽然向量技术强大,但它们会消耗大量内存。为了让计算机无需低速搜索庞大数据库
按标签聚合查看文章内容。
AI资讯美国谷歌公司发布了一种名为“TurboQuant”的压缩算法,旨在解决大型语言模型(LLM)运行时大量内存消耗的问题。该算法通过向量量子化技术,将内存使用量降低至原来的六分之一。详细内容预计将在2026年4月23日召开的国际学习表征会议(ICLR 2026)上公布。 当前的人工智能技术通过向量来理解和处理语言、图像等信息。虽然向量技术强大,但它们会消耗大量内存。为了让计算机无需低速搜索庞大数据库
 AI资讯
AI资讯美国谷歌(Google)研究部门Google Research于3月24日发布了一种全新的量化算法“TurboQuant”,旨在大幅降低大规模语言模型(LLM)和向量搜索引擎的内存消耗。该技术有望解决AI响应速度的瓶颈问题,实现AI及搜索基础设施的显著效率提升。 开发背景及AI内存挑战 AI理解信息的基本单位是向量,随着向量维度增加,用于捕捉图像特征或语言含义的复杂信息,所需的内存也急剧增加。这导
 AI资讯
AI资讯美国Google DeepMind于6月5日(当地时间)发布了开源模型「Gemma 4」系列的“量化感知训练”(Quantization-Aware Training,简称QAT)检查点。该技术旨在大幅减少内存使用量,同时保持模型质量,适用于「E2B」「E4B」「12B」「26B MoE」「31B」等所有模型。 自今年4月发布以来,Gemma 4不断扩展功能,包括引入加速推理的“多标记预测”(M
 AI资讯
AI资讯Ollama最新更新引入苹果自研MLX框架,大幅提升搭载苹果芯片Mac本地大模型性能,响应速度提升至两倍,M5芯片表现尤为突出。