 AI资讯
AI资讯本地运行大型语言模型的性能检测工具介绍
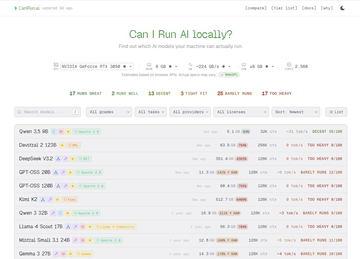
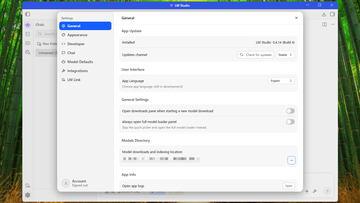
自从ChatGPT问世以来,以大型语言模型(LLM)为核心的人工智能技术迅速普及。其中,能够在个人电脑或智能手机上本地运行LLM的“本地LLM”也逐渐受到关注。 然而,对于初学者来说,最大的难题之一是完全无法判断自己当前设备能够运行多大规模的模型,性能表现如何。 在本地运行LLM时,几乎成为事实标准的“LM Studio”软件可以自动检测电脑的硬件规格,判断现有的GPU和内存容量是否足以加载模型
按标签聚合查看文章内容。
AI资讯自从ChatGPT问世以来,以大型语言模型(LLM)为核心的人工智能技术迅速普及。其中,能够在个人电脑或智能手机上本地运行LLM的“本地LLM”也逐渐受到关注。 然而,对于初学者来说,最大的难题之一是完全无法判断自己当前设备能够运行多大规模的模型,性能表现如何。 在本地运行LLM时,几乎成为事实标准的“LM Studio”软件可以自动检测电脑的硬件规格,判断现有的GPU和内存容量是否足以加载模型
 AI资讯
AI资讯日本国家本地LLM执行工具“LM Studio”于4月9日发布了新版本0.4.10。本次更新主要提升了Gemma 4工具调用(tool call)的可靠性,增强了整体运行的稳定性。 此外,LM Studio在访问本地文件及外部工具/数据时所使用的MCP(模型上下文协议,Model Context Protocol)中,新增了对OAuth认证的支持。通过引入基于Web浏览器的登录认证机制,显著提升
 AI资讯
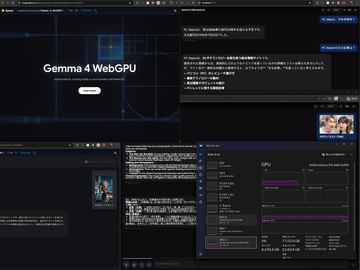
AI资讯截至2026年,想要在本地体验大型语言模型(LLM),通常需要下载并启动如LM Studio的软件,下载模型,进行配置和运行。虽然步骤不算复杂,但对普通用户来说门槛仍然较高。大家可能更希望像使用云服务一样,只需打开网页浏览器访问一个URL,就能轻松运行本地LLM。 实现这一目标的关键技术是WebGPU。本文将介绍如何利用Web浏览器和WebGPU轻松运行本地LLM,并推荐几个可以立即体验的相关网
 AI资讯
AI资讯本地大型语言模型软件「LM Studio」于5月13日发布了新版本0.4.13。 在此次更新中,Mac平台上的引擎「mlx-engine」升级至版本1.8.1,针对支持视觉功能的模型如Qwen 3.5、Qwen 3.6以及Gemma 4,新增了并行预测功能,从而显著提升了性能表现。 此外,修复了聊天输入框粘贴时换行被压缩的错误,并加强了安全性。官方建议所有用户尽快更新至最新版本以获得更好的使用体
 AI资讯
AI资讯2026年5月13日至15日,日本东京国际展示中心举办的教育领域展会“EDIX东京2026”正式开幕。华硕日本公司展台展出了采用NVIDIA最新架构“Blackwell”的超小型AI超级计算机“ASUS Ascent GX10”,现场演示了本地大型语言模型(LLM)的运行情况。 “ASUS Ascent GX10”基于NVIDIA DGX Spark开发,搭载了下一代芯片NVIDIA GB10
 AI资讯
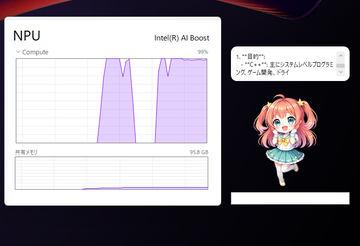
AI资讯近年来,采用高性能移动CPU的紧凑型迷你PC凭借媲美桌面PC的性能迅速占领市场。日本GMKtec率先搭载了英特尔最新CPU——代号为Panther Lake的「Core Ultra系列3」的高性能AI迷你PC「EVO-T2S」。 EVO-T2S搭载了采用最新Intel 18A工艺制造的Core Ultra X7 358H处理器。内置的NPU最高可达50TOPS的处理能力,结合强大的GPU,系统整
 AI资讯
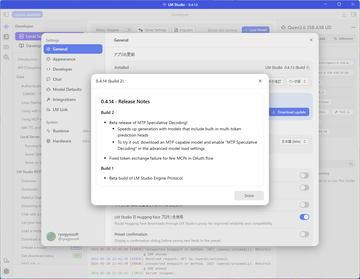
AI资讯日本国家Element Labs于5月22日发布了包含MTP Speculative Decoding稳定版的本地LLM软件最新版本「LM Studio 0.4.14(Build 4)」。目前该版本支持Qwen 3.6系列模型。 MTP(Multi-Token Prediction)Speculative Decoding是一种通过轻量级模型预测未来多个token,并由目标模型验证预测结果,从而
 AI资讯
AI资讯美国Element Labs于5月20日发布了本地大型语言模型(LLM)软件“LM Studio”的最新测试版——LM Studio 0.4.14 (Build 2)。此次更新引入了MTP(多标记预测,Multi-Token Prediction)技术,实现了投机性解码,显著提升了支持该功能模型的运行速度。 新版本支持包括Qwen 3.6和Gemma 4等最新模型,特别是在并行处理时,速度提升可
 AI资讯
AI资讯笔者小时候的梦想是创办一家软件公司。1996年Windows 95发布前后,电视上不断播放关于微软创始人比尔·盖茨的新闻和专题,软件公司看起来很有趣,老板又很富有,这让当时的我充满憧憬。 然而,想要创办软件公司,首先得学习软件开发,尝试自己写程序。于是我买了很多编程书籍,试图学习,但完全无法想象自己能写出软件。问题并非没有想法,而是书中讲的函数、指针、栈等概念与我梦想中的软件毫无关联感。 回头看
 AI资讯
AI资讯许多读者可能在家中使用性能强劲的桌面电脑,通过LM Studio体验本地大型语言模型(LLM)。但大家或许也有这样的想法:“如果能在外出时用轻便的笔记本电脑访问LLM,那该多方便啊。”而这正是本文介绍的LM Link所实现的功能。 什么是LM Link? LM Studio是一个可以在本地PC上运行LLM的工具,它基于llama.cpp,提供了用户友好的图形界面和聊天功能,并集成了多种实用特性。