自从ChatGPT问世以来,以大型语言模型(LLM)为核心的人工智能技术迅速普及。其中,能够在个人电脑或智能手机上本地运行LLM的“本地LLM”也逐渐受到关注。
然而,对于初学者来说,最大的难题之一是完全无法判断自己当前设备能够运行多大规模的模型,性能表现如何。
在本地运行LLM时,几乎成为事实标准的“LM Studio”软件可以自动检测电脑的硬件规格,判断现有的GPU和内存容量是否足以加载模型,但它并不会提供运行速度的参考指标。
如果下载了8GB大小的模型却无法流畅使用,不断尝试其他模型无疑会浪费大量时间。此外,从Hugging Face庞大的模型库中寻找最合适的模型,犹如大海捞针。
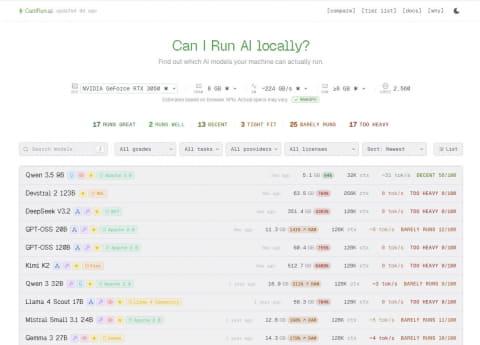
这时,一个名为“Can I Run AI locally?”的网站就显得非常实用。该网站利用WebGPU等技术,自动检测GPU及其核心数、内存容量和带宽等硬件信息,列出适合的模型,并给出运行速度的估算(以tok/s为单位)。
由于AI模型的内存消耗会因量化级别不同而变化,该网站还支持点击具体模型查看不同量化级别下的质量、内存使用和速度预估,方便用户在下载前做参考。
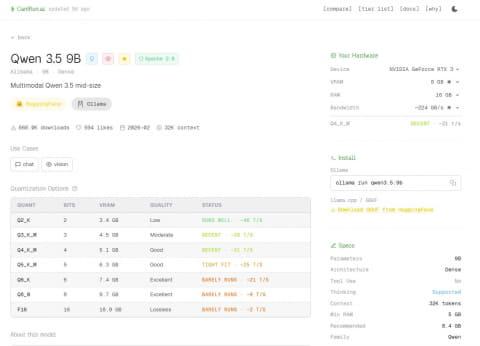
需要注意的是,该硬件检测并非完全准确。例如,笔者使用的是配备6GB显存的日本国家NVIDIA GeForce RTX 3050显卡,但自动检测结果却显示为8GB版本,且列表中没有Intel Arc B系列显卡的信息。此外,该网站似乎不支持仅用CPU运行模型,因此检测结果仅供参考。
总之,对于想在本地设备上运行大型语言模型的用户来说,“Can I Run AI locally?”提供了一个便捷的硬件检测和模型匹配工具,有助于节省试错时间,提升使用体验。