截至2026年,想要在本地体验大型语言模型(LLM),通常需要下载并启动如LM Studio的软件,下载模型,进行配置和运行。虽然步骤不算复杂,但对普通用户来说门槛仍然较高。大家可能更希望像使用云服务一样,只需打开网页浏览器访问一个URL,就能轻松运行本地LLM。
实现这一目标的关键技术是WebGPU。本文将介绍如何利用Web浏览器和WebGPU轻松运行本地LLM,并推荐几个可以立即体验的相关网站。
什么是WebGPU?
首先澄清一点,WebGPU是WebGL技术的继任者。它不是使用云端GPU,而是直接调用本地电脑上的GPU来处理各种计算任务。本文介绍的LLM正是通过WebGPU运行的。因此,搭载集成显卡(iGPU)的电脑可能无法流畅运行LLM(虽然CPU也能运行,但速度极慢),这点需要特别注意。
使用WebGPU需要支持该技术的浏览器。目前Google Chrome和Microsoft Edge 113版本及以上,macOS上的Safari 18及以上版本均已支持,普通用户一般不会有兼容性问题。
不过,由于Windows和macOS的实现方式不同,macOS上WebGPU运行速度较快,而Windows即使使用高端显卡如GeForce RTX 4090,性能表现仍然不理想。原因在于:
- macOS Chrome/Safari:WebKit → Metal
- Windows Chrome/Edge:WGSL → Tint编译器 → HLSL → D3D12 → GPU驱动 → GPU
Windows的多层转换带来了较大开销,导致性能下降,这方面的改进还需期待。
此外,基于WebGPU的LLM模型目前不支持常见的GGUF或MLX格式,而是需要专用的ONNX格式。虽然存在转换工具,但由于transformers库版本较旧,最新模型无法正常转换。因此,本文介绍的Gemma-4和Qwen 3.5模型的具体转换方法尚不明,但相关网站已预先托管了转换好的模型,用户只需访问即可直接使用。
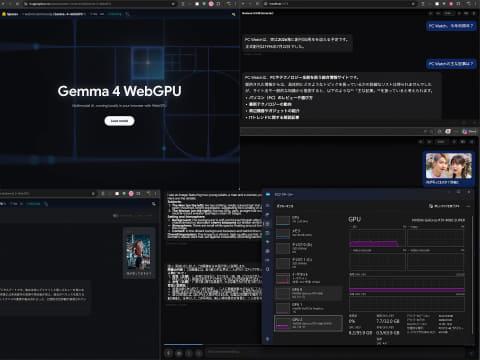
WebGPU运行的LLM聊天应用首次访问时,会从Hugging Face下载模型到浏览器的Cache Storage(可通过浏览器开发者工具查看)。聊天内容全部在浏览器内处理,不会主动发送到外部,保证隐私安全。使用的显存会在关闭或离开页面时立即释放。
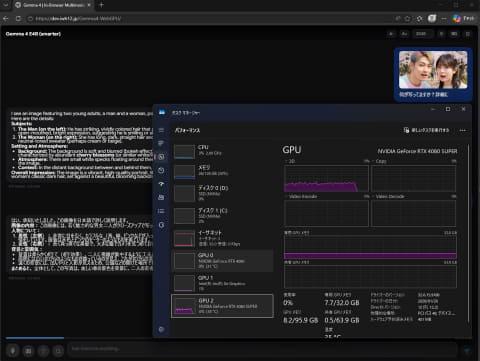
基于以上背景,下面介绍四个支持WebGPU的LLM聊天网站,按发布时间倒序排列,最新的模型支持更好。首次访问时会下载数GB数据,建议在Wi-Fi环境下使用,并注意存储空间。
WebGPU实例介绍
1. Gemma-4 E2B WebGPU聊天
Gemma-4-WebGPU支持Google最新发布的轻量级模型Gemma-4 E2B。它支持使用电脑摄像头和麦克风,能输入图像和音频。
功能丰富,包括:
- 语音输入:通过麦克风录音,Gemma-4的音频编码器自动转写
- 摄像头捕捉:一键抓取当前视频帧发送
- 视频源选择:支持摄像头或视频文件
- 思考模式:显示模型推理过程,可开关
- 视觉工具调用:模型可自主请求摄像头捕捉并回答“现在看到了什么?”
- Markdown渲染:支持标题、列表、表格、代码块、引用等格式
- 语法高亮:代码块按语言着色
- 数学公式渲染(KaTeX支持)
- Mermaid图表渲染:将模型输出的Mermaid语法绘制为流程图,支持缩放和下载
- 代码块复制按钮:一键复制代码
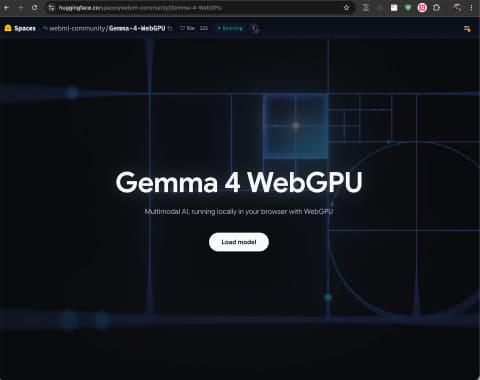
特别有趣的是“现在看到了什么?”功能,模型能自动启动摄像头拍摄并分析。不过普通图片无法通过拖拽上传。
缺点是启动时必须有摄像头或视频文件作为背景显示,若桌面电脑无摄像头且无视频文件,无法继续使用。
2. Qwen 3.5 WebGPU聊天
Qwen3.5-WebGPU由中国阿里巴巴开发,支持0.8B、2B、4B三个版本,均支持视觉输入,能进行图像识别。
最初另一个Qwen 3.5 WebGPU聊天性能不佳,这个版本备受期待。虽然现在有Gemma-4,竞争激烈。
3. Qwen 3.5 Ex0bit/tensorbend
Ex0bit/tensorbend也是Qwen 3.5模型,但采用独特方式,绕过ONNX运行时,直接用自定义GPU计算代码加载模型。支持多种量化方式(PARO、INT4、AWQ),速度不错,但推理精度有所下降。
4. GPT-OSS-20b WebGPU聊天
GPT-OSS-WebGPU基于OpenAI开发的gpt-oss-20b模型,是最早的WebGPU聊天应用。加载20b模型需要大量显存(建议32GB以上内存),且不支持视觉输入,无法识别图像。
额外功能与改进
使用这些WebGPU聊天时,常见问题是日文输入法(IME)确认键[Enter]会直接发送消息,这可能是日本特有的问题。
所有源码均可通过git clone获取,笔者对部分代码进行了功能增强,介绍两个改进版本:
Vision支持的gpt-oss-20b WebGPU聊天
原版gpt-oss-20b不支持视觉识别,笔者集成了Florence-2的ONNX图像识别模型,实现图片内容识别并写入聊天会话,支持后续对图片内容的交流。源码已开源,感兴趣者可尝试。
不过有了Qwen 3.5和Gemma-4,这个版本的实用性有所下降。
支持Web搜索的Gemma-4 E2B/E4B WebGPU聊天
另一个版本支持Gemma-4的E2B和E4B模型,且无需视频文件即可启动,增加了系统提示、字体大小调整、图片拖拽上传、缓存清理、最大Token设置、聊天背景遮罩以及网页搜索功能。
网页搜索通过本地代理服务器调用LM Studio的MCP模块,搜索结果经过清理,去除广告和无关链接,避免浪费Token。
源码计划公开,但因Claude Code使用限制频繁,开发进展缓慢。笔者发现Claude在代码生成时容易陷入循环,浪费Token,提醒大家AI辅助编程仍需谨慎。
完成后将发布在GitHub,欢迎关注。
总结
WebGPU技术让用户仅需打开网页即可调用本地GPU运行LLM,极大降低了使用门槛。macOS上运行流畅,Windows因实现差异性能较差,但未来有望改进。随着Gemma-4和Qwen 3.5等模型的支持,WebGPU本地LLM体验日益丰富,值得期待。
※本文投稿后,笔者已在GitHub公开了Gemma 4 E2B/E4B WebGPU聊天源码。