 AI资讯
AI资讯你是否听过这些AI术语却只是点头?让我们来弄懂它们
人工智能正在改变世界,同时也创造了一套全新的语言来描述它的运作方式。只需花五分钟阅读AI相关内容,你就会遇到LLM、RAG、RLHF等众多术语,即使是技术领域的专家也可能感到困惑。本文词汇表旨在帮助你理解这些术语,并会随着领域的发展不断更新,堪称一份“活文档”,就像它所描述的AI系统一样。 AGI 人工通用智能(AGI)是一个模糊的概念,通常指的是在多数任务上能力超过普通人的AI。OpenAI的C
按标签聚合查看文章内容。
AI资讯人工智能正在改变世界,同时也创造了一套全新的语言来描述它的运作方式。只需花五分钟阅读AI相关内容,你就会遇到LLM、RAG、RLHF等众多术语,即使是技术领域的专家也可能感到困惑。本文词汇表旨在帮助你理解这些术语,并会随着领域的发展不断更新,堪称一份“活文档”,就像它所描述的AI系统一样。 AGI 人工通用智能(AGI)是一个模糊的概念,通常指的是在多数任务上能力超过普通人的AI。OpenAI的C
 AI资讯
AI资讯白宫科学顾问迈克尔·克拉齐奥斯(Michael Kratsios)指出,开发Kimi K3这一目前最大的开放权重大型语言模型(LLM)的中国公司Moonshot,是通过复制Anthropic的Fable模型,并使用未经批准出口到中国的芯片来构建其模型的。 克拉齐奥斯表示:“大规模、隐秘的工业蒸馏行为,旨在窃取美国专有技术并破坏美国研究,这是不可接受的。”这一言论正值关于是否禁止中国开放权重模型的讨
 AI资讯
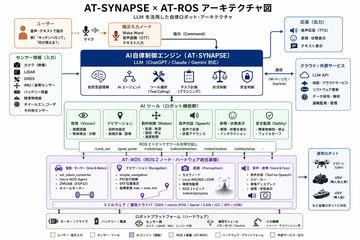
AI资讯AT-SYNAPSE是一款基于大型语言模型(LLM)的机器人自主控制系统,支持多种LLM接入,实现自然语言指令理解与自主决策。
 AI资讯
AI资讯Yann LeCun认为,大多数人类推理基于物理世界而非语言,因此构建AI世界模型是实现真正人类级智能的关键。他在接受WIRED采访时表示:“认为通过扩展大型语言模型(LLMs)的能力就能达到人类级智能完全是无稽之谈。” 这轮融资使该初创公司估值达到35亿美元,领投方包括Cathay Innovation、Greycroft、Hiro Capital、HV Capital和Bezos Expedi
 AI资讯
AI资讯ArXiv 是一个广泛使用的开放预印本研究存储库,近期加强了对科学论文中不当使用大型语言模型(LLM)的监管。 虽然ArXiv上的论文是在同行评审前发布的,但它已成为计算机科学和数学等领域研究传播的主要渠道之一,同时该平台也成为科学研究趋势数据的重要来源。 为了应对越来越多低质量的AI生成论文,ArXiv已经采取措施,例如要求首次投稿者必须获得资深作者的推荐。经过20多年由康奈尔大学托管后,ArX
 AI资讯
AI资讯Legora是一款面向律师的人工智能平台,最新完成5.5亿美元的D轮融资后,估值达到55.5亿美元,资金将主要用于推动其在美国市场的扩展。尽管面临Harvey、微软Copilot以及通用大型语言模型(LLM)的激烈竞争,Legora依然保持强劲增长。公开上市的法律软件公司股价在Anthropic推出Claude法律插件后出现下跌,显示市场竞争日益激烈。 Legora基于大型语言模型,主要依托Cla
 AI资讯
AI资讯在AI热潮的背后,隐藏着一个现实难题:企业为AI工具支付天价费用,但这些工具的价值仍无法媲美一名称职的人类员工。随着AI公司及其投资者不断投入数十亿美元进行AI研发,这种矛盾的后果正逐渐显现于美国各地的办公室和商铺中。 例如,金融科技公司Slash最近鼓励员工尽可能多地使用AI编程工具,这种行为被称为“代币最大化”,旨在提升生产力并降低成本。然而,语言模型(LLM)代币价格过高且实用性有限,难以实
 AI资讯
AI资讯药物发现是现代工业中成本最高的领域之一。找到一个可行的分子可能需要十年时间,花费数十亿美元,而且大多数候选分子最终都未能成功。新一代的人工智能初创公司承诺解决这一难题——大多数工具已经让技术足够成熟的研究人员使用起来更为轻松。 但SandboxAQ认为,瓶颈不在于模型本身,而在于界面设计。 该公司与Anthropic合作,将其科学人工智能模型直接集成到Claude中——通过一个对话式界面提供强大的
 AI资讯
AI资讯最新报告显示,主流大型语言模型在涉及政治敏感话题时,表现出对不同国家言论自由环境的差异化响应,尤其在言论受限国家更易自我审查。
 AI资讯
AI资讯多年来,人工智能公司一直向投资者宣传,扩大规模是成功的关键——AI模型越大,能力越强。 但实际上,这一前提正引发巨大的商业问题。正如《大西洋月刊》指出,大型语言模型(LLM)正面临严重的收益递减问题:推理成本,即使用训练好的AI模型处理新数据的费用,正呈指数级上升,使得这项技术的盈利能力远不如半年前。 简单来说,这与投资者通常期望看到的趋势相反,投资者更希望每个用户的成本持续下降,而非上升。 这对
 AI资讯
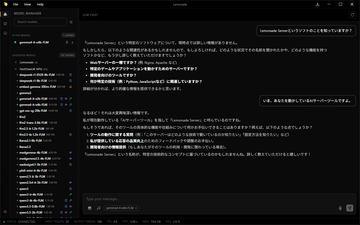
AI资讯AMD的AI技术曾被认为落后于NVIDIA和Intel,但近年来其表现显著回升,其中代表作之一便是「Lemonade Server」。 这是一款基于AMD Ryzen AI,整合多种AI运行时的本地AI执行环境。虽然名为服务器,支持远程调用AI功能,但也附带桌面客户端,方便用户在本地直接运行AI模型。 本文将介绍该客户端的基本使用方法。测试设备为搭载AMD Ryzen AI 9 HX 370的日
 AI资讯
AI资讯在华尔街沉睡之际,一款由中国研发的大型语言模型悄然跃升,超越了16个竞争对手,登顶AI排行榜。 这款名为Kimi-K3的模型由北京Moonshot AI公司开发。周四,AI基准测试平台Arena.ai宣布,Kimi-K3在“前端代码竞技场”中,从第17名一跃成为第一名,远远领先于备受关注的Claude Fable 5和GPT-5.6 Sol。 在“文本竞技场”——衡量模型在文本生成和创意写作等任务