2026年,开源大型语言模型(LLM)依旧层出不穷,各种高速化技术也不断涌现,AI领域持续热闹非凡。本文将介绍两项技术:利用MTP技术加速的Gemma 4,以及在日本苹果Mac M4 Max 128GB上运行的DeepSeek V4 Flash(现称DwarfStar 4)。
Gemma 4借助MTP实现推理加速
今年春季,LLM领域在高速化和模型轻量化方面取得了显著进展。其中,Google发布的Gemma 4通过多令牌预测(MTP,Multi-Token Prediction)技术,实现了推理速度提升3倍,且输出质量保持不变。
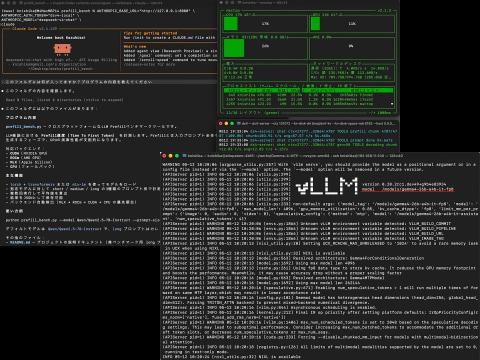
MTP的核心思想是:一个小型的草稿模型(Draft Model)提前预测多个后续令牌,再由大型主模型(Target Model)统一验证,从而加快推理速度。笔者早在一个多月前就已在DGX Spark兼容机上使用vLLM结合Qwen 3.6 27B模型和MTP技术,实际应用中表现良好。
此前未使用MTP时,令牌输出速度(tok/s)较慢,难以满足高效编码需求,但引入MTP后速度提升2至3倍,且并行处理能力增强,极大改善了使用体验。Gemma 4的MTP加速效果也得到了验证,但需要注意的是,目标模型必须是经过指令微调的版本(带有-it后缀),否则草稿模型的预测分布会偏差,反而降低性能。
目前,Gemma 4 MTP技术在主流工具中的支持情况如下:
| 工具 | 状态说明 |
|---|---|
| vLLM | PR #41745待合并,预览版Docker可用 |
| llama.cpp | Qwen3系列MTP处于测试阶段,Gemma 4助手模型转换未完成 |
| LM Studio | 基于llama.cpp,暂未支持 |
| Ollama | 支持Gemma 4 MTP,但仍在测试中 |
| MLX | 实现存在,但单请求无效甚至负效应 |
因此,目前只有Linux环境下使用vLLM预览版和Docker能较好运行Gemma 4 MTP,Windows用户暂时难以体验。笔者选择在DGX Spark兼容机上测试,配置如下:
- 目标模型:RedHatAI/gemma-4-26B-A4B-it-FP8-Dynamic(FP8,-it版)
- 草稿模型:google/gemma-4-26B-A4B-it-assistant(约870MB,BF16)
hf download RedHatAI/gemma-4-26B-A4B-it-FP8-Dynamic --local-dir ~/models/gemma4-26b-a4b-it-fp8
hf download google/gemma-4-26B-A4B-it-assistant --local-dir ~/models/gemma4-26b-a4b-it-assistant
wget https://raw.githubusercontent.com/vllm-project/vllm/d8b3826648da6b407f8c55457a2103be9aeb5d83/vllm/model_executor/models/gemma4_mtp.py -O /tmp/gemma4_mtp.py
启动Docker容器示例:
docker run -d --name gemma4-baseline \
--gpus all --ipc host --shm-size 64gb \
-p 8000:8000 \
-v ~/models:/models \
vllm/vllm-openai:gemma4-0505-arm64-cu130 \
--model /models/gemma4-26b-a4b-it-fp8 \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096 \
--limit-mm-per-prompt '{"image":0,"audio":0,"video":0}'
# 启用MTP
docker run -d --name gemma4-mtp \
--gpus all --ipc host --shm-size 64gb \
-p 8000:8000 \
-v ~/models:/models \
-v /tmp/gemma4_mtp.py:/usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/gemma4_mtp.py:ro \
vllm/vllm-openai:gemma4-0505-arm64-cu130 \
--model /models/gemma4-26b-a4b-it-fp8 \
--speculative-config '{"method":"mtp","model":"/models/gemma4-26b-a4b-it-assistant","num_speculative_tokens":4}' \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096 \
--limit-mm-per-prompt '{"image":0,"audio":0,"video":0}'
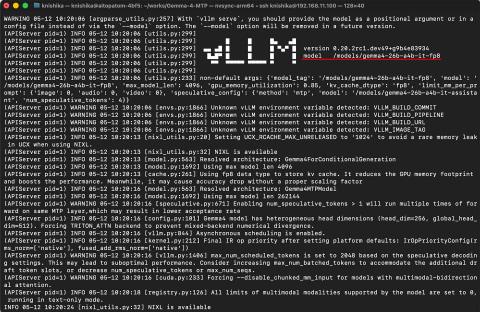
基准测试显示,单请求生成速度从42.48 tok/s提升至52.7~73.8 tok/s,提升约1.24至1.74倍。并行测试中,随着并行数增加,性能提升更明显,4并行时速度超过2倍,符合MTP理论预期。
考虑到家庭用户的GPU环境,GeForce RTX 5090(32GB)可能支持INT4量化版本的Gemma 4,模型权重约15GB,加上草稿模型和缓存,内存需求约28~30GB,勉强可用,但最大上下文长度限制为4096令牌,无法满足更长上下文需求。RTX 4090(24GB)则无法满足此需求。
此外,Blackwell架构支持NVFP4量化,模型大小约16.5GB,精度和速度可能优于INT4,但同样受限于上下文长度,实际应用仍有限。期待llama.cpp及其衍生工具如LM Studio尽快支持MTP,届时普通用户将更易体验此技术。
DwarfStar 4(原ds4.c)与DeepSeek V4 Flash
4月24日,日本DeepSeek发布了V4 Pro和V4 Flash版本:
- DeepSeek V4 Pro:1.6万亿参数,总激活参数490亿,支持1百万令牌上下文
- DeepSeek V4 Flash:2840亿参数,总激活参数130亿,支持1百万令牌上下文,MIT开源许可
显然,这些模型对VRAM需求极高,128GB显存的设备难以运行。令人惊讶的是,近期社区发现名为DwarfStar 4的Metal推理引擎可在配备128GB内存的日本苹果Mac(M3 Ultra、M4 Max、M5 Max等)上运行DeepSeek V4 Flash。
DwarfStar 4由开源数据库Redis作者antirez开发,基于C语言的本地推理引擎,专为DeepSeek V4 Flash设计,特点包括:
- Metal专用,独立于llama.cpp
- 支持磁盘KV缓存
- 2bit量化,适配128GB内存Mac
- MoE专家部分采用2bit量化,其他部分保持较高精度
- 支持OpenAI API兼容的服务器端点,方便集成Claude Code、OpenCode等
模型参数2840亿,理论量化大小如下:
| 量化方式 | 理论大小 |
|---|---|
| FP16 | 568GB |
| 8bit | 284GB |
| 4bit | 142GB |
| 2bit | 71GB |
实际Q2 GGUF文件约86.7GB,因部分模块未完全量化。DwarfStar 4采用独特的Multi-head Latent Attention(MLA)机制,将KV缓存压缩至普通模型的2~5%,1百万令牌上下文仅需约26GB,极大降低了内存压力。
KV缓存被存储在SSD上,带来以下优势:
- 会话持久化,重启后缓存依然有效
- 支持多会话缓存,切换无需重新预填充
- 容量大,SSD空间充足
- 与MLA机制高度兼容,SSD读写速度快
缺点包括:
- 新会话首次加载时间较长(约4分钟)
- 缓存键严格,稍有差异即缓存失效
- 外接SSD性能影响显著
- 内存中仅缓存单会话,限制多客户端并发
DwarfStar 4实测体验
在MacBook上安装极为简便:
git clone https://github.com/antirez/ds4.git
cd ds4
make
./download_model.sh q2-imatrix
q2-imatrix量化方法通过预先评估权重重要性,提升了量化后模型质量,推荐使用。
简单基准测试显示,短上下文时预填充速度约55 t/s,生成速度约31 t/s;长上下文时预填充速度达260 t/s,生成速度约23 t/s,足以满足日常聊天需求。
启动服务器示例:
./ds4-server --ctx 131072 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 8192 --host 0.0.0.0
支持OpenAI API兼容端点及Claude Code的/v1/messages接口。配置环境变量后即可在Claude Code中使用:
ANTHROPIC_BASE_URL="http://127.0.0.1:8000" \
ANTHROPIC_AUTH_TOKEN="dsv4-local" \
ANTHROPIC_MODEL="deepseek-chat" \
claude
并行性能测试显示,随着并行数增加,响应速度明显下降,4并行时效率不足10%,限制了多客户端高效并发使用。MacBook Pro运行时GPU和内存负载较高,机身温度升高,建议将其作为专用机器使用。
目前Open WebUI默认仅显示deepseek-v4-flash模型ID,需手动添加deepseek-chat以选择不同模式。笔者使用中感觉整体体验良好,唯一遗憾是暂不支持视觉输入。
DeepSeek系列独创的MLA机制极大压缩了KV缓存大小,提升了大上下文处理能力。虽然其他模型尚未采用此技术,因需重新训练且成本高昂,但日本乐天集团于2026年3月发布了6710亿参数的MoE模型Rakuten AI 3.0,基于DeepSeek V3技术,未来或可借助DwarfStar 4实现高效推理。
此外,DwarfStar 4已支持DGX Spark平台,测试显示推理速度约为Mac M4 Max 128GB的一半,但预填充速度较快,整体表现良好。
总结来看,2026年春季LLM领域涌现了两项令人兴奋的技术突破,均需128GB内存级别的高端设备支持,尚难普及至普通家庭用户。但随着技术进步,轻量级、高效、易用的LLM环境指日可待。希望本文能为读者带来前沿技术的初步感受。