大约一年半前,在《Ubuntu日和》第58回中,笔者曾以调侃的方式介绍了如何让Ubuntu识别Ryzen AI的NPU,但当时指出其实并无实用价值。那时只是抱着“总有一天能用上”的期待介绍,然而那一天一直未曾到来。
不过,最近情况终于发生了变化。支持Ryzen AI的框架FastFlowLM现已支持Linux系统,相关版本已发布。同时,AMD开发的本地LLM服务器Lemonade也正式支持Linux,且支持包括Ubuntu在内的三个版本。
笔者虽然拥有《第80回》中提到的MINISFORUM AI X1 Pro,但因其已有固定用途,不便用于测试。幸运的是,笔者获得了另一台搭载Ryzen AI 9 HX 370的评测机,这台机器因硬件设计问题无法更换内存和SSD,但对本次测试无影响。
笔者本人对NPU持谨慎态度,认为虽然理想状态下NPU非常优秀,但目前尚不够实用,可能还需数年发展,届时甚至可能放弃NPU方案。下面就来看看实际体验如何。
测试设备介绍
本次测试使用的设备是MINISFORUM AI X1 Pro,配备两条32GB(疑为Crucial品牌)内存,共64GB,SSD为Kingston 1TB型号。操作系统为Ubuntu 24.04.4 LTS,理论上Ubuntu 25.10也可使用。
此前介绍的MINISFORUM UM780XTX搭载的AMD Ryzen 7 7840HS也内置NPU,但FastFlowLM尚不支持该型号,需注意。
换句话说,想体验本次功能,可能需要购买价格不菲的新设备。
安装与配置
官方文档提供了详细的安装说明,操作并不复杂,笔者稍作调整后介绍如下。首先安装FastFlowLM:
sudo add-apt-repository ppa:amd-team/xrt
sudo apt install libxrt-npu2 amdxdna-dkms
sudo usermod -a -G render $USER
执行后需重启系统。虽然官方文档未提及,但必须将用户添加到render组。
接着安装Lemonade服务器:
sudo add-apt-repository ppa:lemonade-team/stable
sudo apt install lemonade-server
虽然有snap和AppImage版本,但笔者选择通过PPA安装Debian包。测试发现snap版本无法正常驱动NPU。
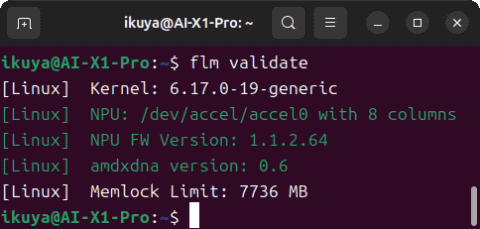
确认NPU是否正常工作,可使用命令 flm validate。
使用Lemonade
安装lemonade-server后,系统会自动安装Chromium浏览器,并添加“Lemonade Web App”应用,实际上是基于Chromium的专用客户端。
如果想用Firefox浏览器访问,可直接打开 http://localhost:8000 。
Lemonade支持聊天、图像生成和语音转文字等功能,但FastFlowLM目前仅支持聊天功能,其他功能暂不介绍。
在“AVAILABLE MODELS”中,FastFlowLM NPU列出了多个模型,包括gpt-oss-20b和疑似gpt-oss-safeguard的gpt-oss-sg-20b。
点击“Download model”按钮即可下载所选模型。
下载完成后,输入问题即可开始对话。
与iGPU性能对比
Llama.cpp GPU版本也支持gpt-oss-20b模型,因此可以对比GPU与NPU的性能。
测试结果显示,NPU的处理速度为19.3 TPS(每秒处理Token数),GPU为25.7 TPS。虽然NPU稍慢,但速度已足够实用。
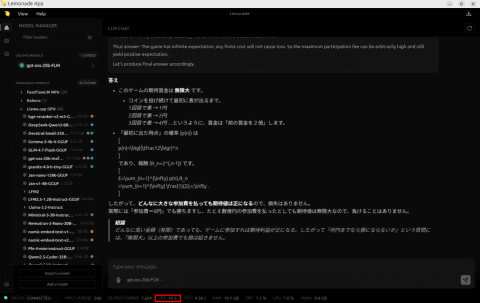
NPU推理表现令人惊喜
即使是较大的gpt-oss-20b模型,NPU也能提供接近实用的推理速度,令人印象深刻。随着NPU技术和内存速度的提升,未来运行更大模型将更加流畅。
此外,评价极高且支持图像解析的Qwen3.5-9B模型若能在NPU上运行,将极大拓展应用场景,值得期待。
根据社区反馈,虽然目前将任意模型转换为FastFlowLM支持格式是付费服务,但未来计划开放转换工具,方便用户自由使用更多模型。
商用使用需谨慎
FastFlowLM包含专有二进制文件,非完全开源,商业使用时需注意授权问题。不过,该公司年销售额超过16亿日元,普通用户大多无需担心。
另外,默认上下文容量较小,复杂查询支持有限,使用时需留意。