 AI教程
AI教程在 Windows 上跑 DeepSeek:WSL2 与原生环境的优劣与坑点全解析
在 Windows 本地运行 DeepSeek 完全可行,但不同方案体验差异巨大。本文用通俗视角梳理 WSL2 与原生 Windows 的取舍、CPU / GPU 路线、Ollama 与 llama.cpp 的简易玩法、NVIDIA 与 AMD 在 Windows 上的真实支持现状,以及常见故障排查与本地隐私安全要点。
按标签聚合查看文章内容。
AI教程在 Windows 本地运行 DeepSeek 完全可行,但不同方案体验差异巨大。本文用通俗视角梳理 WSL2 与原生 Windows 的取舍、CPU / GPU 路线、Ollama 与 llama.cpp 的简易玩法、NVIDIA 与 AMD 在 Windows 上的真实支持现状,以及常见故障排查与本地隐私安全要点。
 AI资讯
AI资讯本文汇总了Gemma 4模型发布、Hermes Agent的快速普及、AI推理性能评测及企业级应用等最新进展。
 AI教程
AI教程一份面向 2026 年的 DeepSeek 实战指南:如何在托管 API、本地 Ollama 以及自建推理集群之间做选择,并避免老教程中的常见坑。
 AI资讯
AI资讯2026年,开源大型语言模型(LLM)依旧层出不穷,各种高速化技术也不断涌现,AI领域持续热闹非凡。本文将介绍两项技术:利用MTP技术加速的Gemma 4,以及在日本苹果Mac M4 Max 128GB上运行的DeepSeek V4 Flash(现称DwarfStar 4)。 Gemma 4借助MTP实现推理加速 今年春季,LLM领域在高速化和模型轻量化方面取得了显著进展。其中,Google发布
 AI教程
AI教程跑本地 DeepSeek 选 GGUF,要原始权重与训练选 Safetensors。两者不是谁替代谁,而是各管 LLM 工作流里的不同环节。
 AI资讯
AI资讯AMD推出开源框架OpenClaw及两款硬件参考设计,支持开发者在本地PC上运行大型语言模型和多智能体工作流,提升隐私保护并减少对云端依赖。
 AI教程
AI教程想在自己机器或服务器上跑 DeepSeek,而不是依赖云端 API?本文用实战视角讲清:什么时候该用 vLLM,如何选 DeepSeek 模型,如何安装与启动服务,如何处理推理输出、工具调用、性能与安全,以及常见坑位排查。适合有一定开发基础、希望自建 OpenAI 风格接口的技术同学。
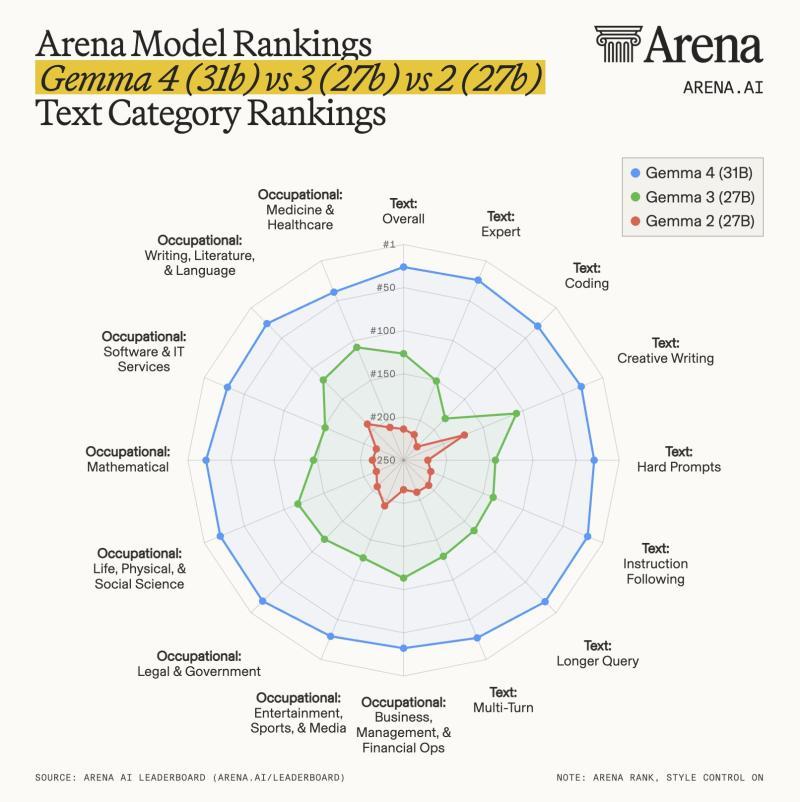 AI资讯
AI资讯谷歌DeepMind发布了Gemma 4系列模型,带来显著性能提升和多模态支持,成为当前顶尖的开源模型之一。
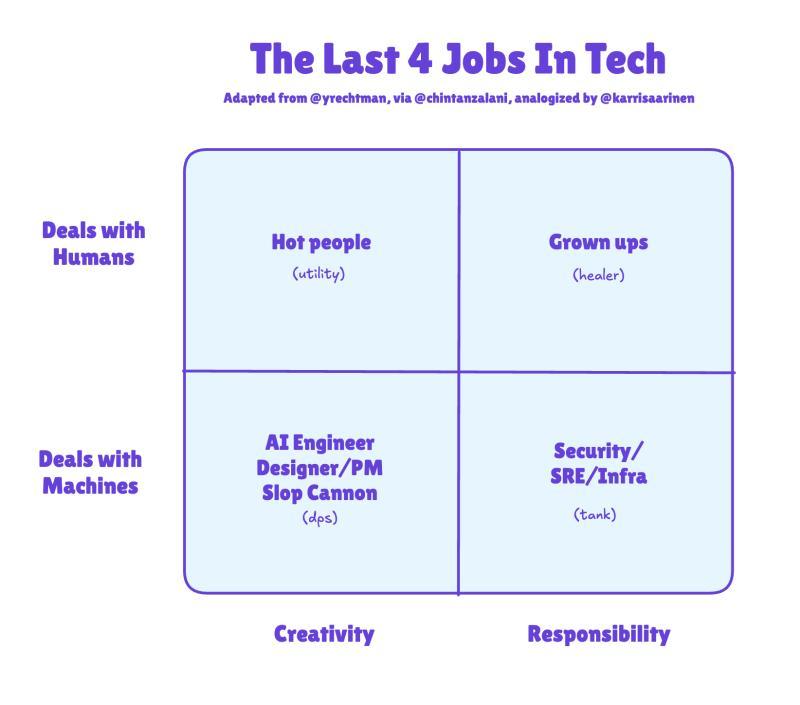 AI资讯
AI资讯在人工智能变革下,科技行业的组织架构和职位角色正在发生深刻变化。本文探讨了后AI时代白领科技岗位的新模型,并回顾了近期AI领域的重要技术进展。