99%的人以为“顶级智能=闭源+高价”,Kimi K2.6 正在把这个共识悄悄掀翻。一个开源权重模型,居然能在关键代理型工作上和 Claude Opus 4.6 打成平手,甚至部分项目还略胜一筹,而且推理成本只有对手的几分之一。对做 AI 应用、跑长任务代理的团队来说,这不只是多了一个模型选项,而是整个成本结构和技术路线都可能要重算一遍。
Kimi K2.6 到底强在哪
性能首次正面硬刚顶级闭源模型
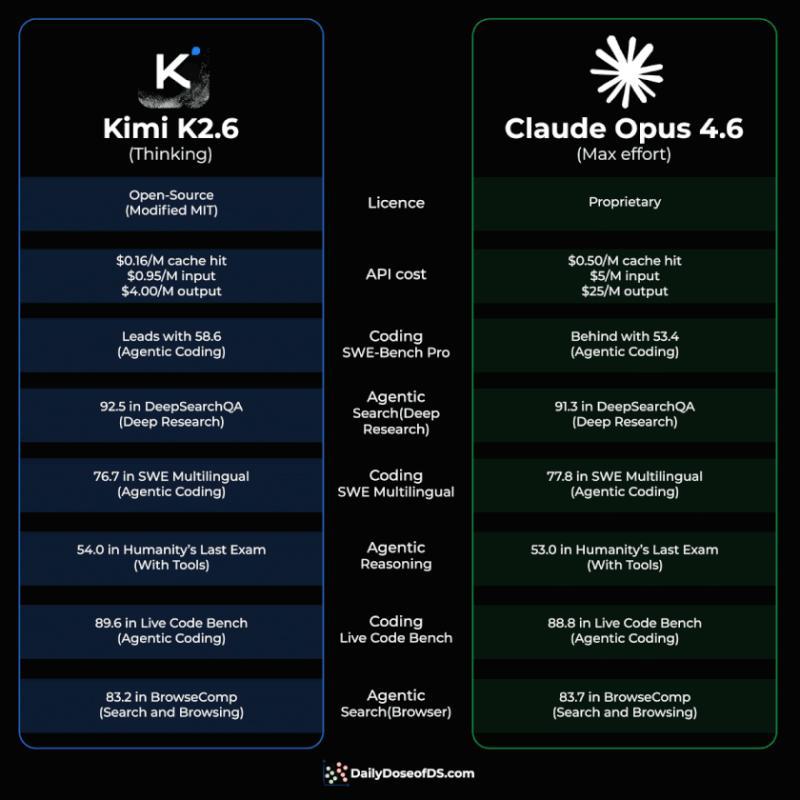
很多人默认“开源=便宜但弱”,K2.6 的表现有点打脸。Moonshot 公布的对比里,K2.6 在 6 项正面对比中赢下了 4 项,而且都是和代理能力高度相关的基准。比如在 SWE-bench Pro(偏工程级自动写代码)上,K2.6 得分 58.6,对比 Opus 4.6 的 53.4,差距已经不是误差级别。深度检索任务 DeepSearchQA 中,K2.6 也以 92.5 比 91.3 领先,这类任务直接关系到“能不能自己查资料、自己做研究”。
据公开数据,K2.6 只在 SWE-bench Multilingual 和 BrowseComp 上略落后于 Opus 4.6,两项差距都不到 1 分,已经进入“体验上很难分出高下”的区间。
在 LiveCodeBench 这类更贴近真实编程场景的测试中,K2.6 以 89.6 对 88.8 再次小幅领先。说实话,如果不看标签,很多人可能已经分不出哪一个是闭源“旗舰”,哪一个是开源“平替”。这背后传递的信号是:在代理相关的关键能力上,开源模型不再是“明显次一档”。
价格差到离谱的成本优势
性能接近也就算了,价格还砍到只剩一小截,这才是让开发者眼睛一亮的地方。官方定价里:
- Kimi K2.6:输入 $0.95 / 百万 tokens,输出 $4 / 百万 tokens
- Claude Opus 4.6:输入 $5 / 百万 tokens,输出 $25 / 百万 tokens
如果你在做高频调用的应用,比如代码助手、自动化运营、批量文案生成,这个价差会非常扎心。更关键的是,一旦启用缓存,差距会被进一步放大:
- K2.6 缓存命中后,输入成本降到 $0.16 / 百万 tokens
- Opus 4.6 缓存命中后,输入成本约 $0.50 / 百万 tokens
粗略算一算,不管有没有缓存,K2.6 都是 5–6 倍左右的成本优势。有用户反馈,自己内部做了一个简单估算:把现有代理工作流从闭源模型迁到 K2.6,月度推理账单理论上能直接砍掉一半以上,这还没算上后续自己部署权重带来的进一步节省。
基准分数之外:真正难的是“跑完一件大事”
长时程自主执行:12 小时不掉链子
基准测试好看是一回事,能不能扛住一整天的复杂任务,是另一回事。K2.6 在长时程代理上的几个实战案例,信息量更大。官方展示的一个任务,是让模型在完全自主的情况下,去移植并优化一个小型 LLM 的推理代码,用 Zig 语言重写——Zig 这种冷门语言,大部分模型几乎没怎么见过。K2.6 连续运行了 12 小时以上,期间发起了 4000+ 次工具调用,一步步完成移植、调试、优化的全流程。
这个任务最后的结果,是在同一套硬件上,K2.6 写出的 Zig 推理实现,比 LM Studio 的表现快了大约 20%。对工程团队来说,这已经不是“能不能写代码”的问题,而是“能不能写出有性能收益的工程级代码”。
我自己看这个案例时,最在意的不是那 20% 的加速,而是它在十几个小时里没有“精神崩溃”:没有在中途忘记上下文、没有在工具调用链里绕晕自己,也没有在遇到冷门语法时直接放弃。这种稳定的长时程执行,过去往往只在最顶级的闭源模型里才看得到。
13 小时重构老系统:吞下 8 年技术债
另一个案例更贴近真实业务:K2.6 被丢给了一个已经运行 8 年的金融撮合引擎,让它在 13 小时内做重构和性能优化。老系统意味着什么,做过的人都懂:文档缺失、历史补丁一堆、风格混乱,还有各种“谁也不敢动”的核心逻辑。K2.6 在这个场景下,最后交出的结果是——峰值吞吐量提升了 133%。
这类任务的难点,不只是写代码,而是要在一团历史遗留里理出结构,理解业务约束,再在不炸掉生产逻辑的前提下做重构。我也不太确定这个 133% 的数字在所有场景都能复现,但至少说明一点:K2.6 已经能在“真实、脏乱差”的工程环境里,完成一件从头到尾的复杂工作,而不是只会在干净的 benchmark 上刷分。
开源权重 + 代理能力:真正的增量在哪
不只是“能用”,而是“敢大规模用”
很多团队早就想用开源模型,但卡在两个现实问题:一是能力差一截,用在关键代理任务上心里没底;二是算力和工程投入不小,迁移成本高。K2.6 的出现,等于把这两道门槛一起压低了。你拿到的是:
- 可实际部署的开源权重
- Modified MIT 许可证,商用友好
- 5–6 倍的推理成本优势
- 在代理任务上接近甚至对标 Opus 4.6 的表现
有开发者分享过一个细节:他们原本用闭源模型做代码代理,每天要刻意限制调用次数,生怕账单爆表。换成 K2.6 之后,直接把调用上限放宽了几倍,让代理可以更频繁地自查、自测、自修 bug,结果整体交付质量反而更稳。这种“敢放开用”的心态变化,其实是开源模型真正的杠杆点。
一个判断模型是否适合做代理的简单标准
很多人选模型时只看通用基准分,其实对“能不能做代理”来说,有一个更实用的三步判断法:
- 看长时程任务案例:有没有 10 小时以上、几千次工具调用的公开任务记录,而不是只跑几分钟 demo
- 看工具链配合:是否在 SWE-bench Pro、HLE with tools 这类“带工具”的基准上表现靠前
- 看成本结构:在你预期的调用规模下,是否能承受“多试几次、多走几条分支”的探索成本
把这三条套在 K2.6 身上,会发现它刚好踩中了代理场景最在意的几个点。信息差在于:很多人还停留在“开源模型=玩具”的旧印象里,没有意识到长时程执行和成本结构已经发生了质变。当然,这只是我自己的观察,也可能有偏差,但从最近一波开源模型的迭代速度看,这个趋势很难逆转。
风险也不能忽略:开源权重虽然可控,但在安全对齐、隐私合规、极端场景鲁棒性上,未必已经完全追平顶级闭源模型。把 K2.6 用在高风险金融决策、医疗诊断等场景时,依然需要加上人工审核和额外的安全防护。
值得被收藏的那部分:怎么用好 K2.6
适合哪些团队和项目
如果你正在做以下几类项目,K2.6 会是一个很有性价比的选择:
- 工程向代理:自动修 bug、重构老项目、跨语言移植
- 深度研究助手:需要长时间检索、比对、整理大量资料
- 高频交互应用:代码助手、运营自动化、批量内容生成
- 内网部署场景:对数据隐私和合规要求高,希望掌握权重
有一位朋友在小团队里试用 K2.6 做“代码管家”:让它每天自动扫一遍仓库,找出潜在问题、生成重构建议,再由人类开发者挑选执行。几周下来,他们发现人类开发者更愿意把时间花在架构设计和关键逻辑上,而不是机械地清理技术债。虽然这个模式还在摸索,但已经能看出一点未来味道。
真正的 takeaway:别等“完美版本”才上车
很多人会想,再等等下一代模型,等“更稳、更强”的版本出来再迁移。问题是,代理类应用的优势,往往来自于“先跑起来、边跑边调”。K2.6 现在给到的组合——开源权重、商用友好协议、接近顶级闭源的代理能力、5–6 倍的成本优势——已经足够支撑一轮严肃的产品实验。这个判断方法在不少团队里被反复验证有效,值得先收进工具箱里,哪怕你暂时还没决定要不要全面迁移。如果你正纠结选哪一个模型来承载下一代代理应用,这篇内容可能比问一圈身边人更有参考价值。
常见问题
Q:Kimi K2.6 和 Claude Opus 4.6 在实际体验上差别大吗?
A:在代理相关的关键任务上,差别已经没想象中那么大。基准数据显示,K2.6 在 SWE-bench Pro、HLE with tools、DeepSearchQA、LiveCodeBench 等 4 项测试中领先,而 Opus 4.6 只在另外 2 项上略胜不到 1 分。实际体验里,你更容易感知到的是风格差异,而不是“明显谁更笨”。如果你对极端边缘场景、复杂多语种支持有极高要求,可以先做一轮小规模 A/B 测试,再决定是否大规模切换。
Q:K2.6 的 5–6 倍成本优势,真实项目里能省多少钱?
A:如果你的应用是高频调用型,比如代码助手或自动化运营,账单差距会非常明显。以官方价格为例,K2.6 输入 $0.95 / 百万 tokens、输出 $4 / 百万 tokens,而 Opus 4.6 分别是 $5 和 $25,缓存命中后 K2.6 还能把输入成本压到 $0.16。按有用户的粗算,一个月消耗几十亿 tokens 的项目,从闭源旗舰切到 K2.6,推理成本理论上能降到原来的 1/3–1/5。建议你先用一周真实流量做对比统计,再决定是否全面迁移。
Q:K2.6 适合完全替代现有闭源模型吗?
A:不建议一上来就“全量替换”,更稳妥的做法是分场景切换。K2.6 在工程代理、长时程任务、深度检索上表现突出,很适合作为这些场景的主力模型;但在高风险决策、强安全合规要求的业务里,闭源模型在对齐和风控上可能依然更成熟。比较理想的策略是:先把非核心、低风险的代理任务迁到 K2.6,观察一段时间的稳定性和故障模式,再逐步扩大覆盖范围。
Q:长时程任务(比如 10 小时以上)用 K2.6 有什么坑需要注意?
A:长时程任务的主要风险不在“算不算得对”,而在“会不会中途迷路或卡死”。虽然 K2.6 已经有 12–13 小时连续执行的成功案例,但在你自己的环境里,依然要做好几个防护:一是给每个任务设定清晰的阶段目标和中间验收点;二是对工具调用次数、时间做上限控制,避免死循环;三是关键步骤加上简单的自动化校验或人工抽查。这样即便模型在某个分支上走偏,也能尽早拉回来,而不是 10 小时后才发现白跑一圈。
Q:开源权重 + Modified MIT 协议,对企业意味着什么?
A:这组合的意义在于“可控”和“可审计”。企业可以选择在自有算力上部署 K2.6,敏感数据不必出内网,同时还能对模型行为做更细粒度的监控和限制。Modified MIT 协议在商用上相对宽松,减少了法律和合规层面的不确定性。当然,企业在落地时仍需配合自身行业监管要求,补上日志留存、访问控制、模型输出审计等一整套治理措施。简单说,它给了你更多主导权,但也意味着你要承担更多治理责任。
如果你读到这里,说明你对“让模型自己干活”这件事是认真的。K2.6 不是终点,却很可能是开源阵营里一个值得记住的转折点。留一点空间给它,在下一个项目里试着放手让它多做一步,说不定会比你预期的更靠谱。


