 AI资讯
AI资讯日本NTT数据与NTT西日本将NTT营销行动ProCX合资成立新公司
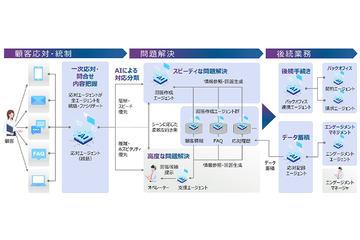
日本NTT数据与NTT西日本宣布将于10月合资成立NTT营销行动ProCX,推动以AI代理为核心的下一代业务流程外包(BPO)服务。
按标签聚合查看文章内容。
AI资讯日本NTT数据与NTT西日本宣布将于10月合资成立NTT营销行动ProCX,推动以AI代理为核心的下一代业务流程外包(BPO)服务。
 AI资讯
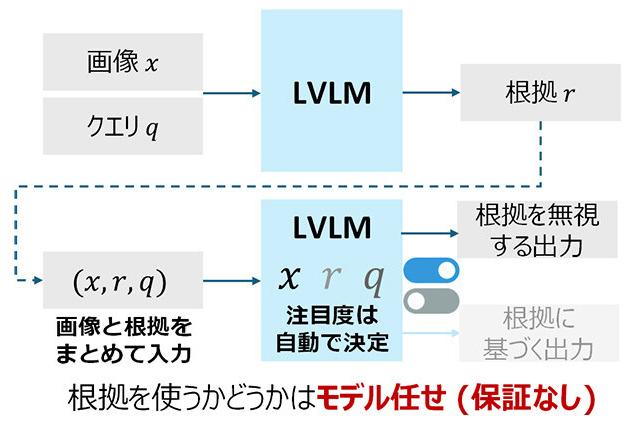
AI资讯日本NTT开发了通过理论框架增强多模态AI模型推理可信度的“根拠强化解码”技术,解决了视觉语言模型推理中根拠与结果不一致的问题。
 AI资讯
AI资讯NTT西日本宣布将在日本大阪和福冈建设支持次世代AI的先进数据中心,推动AI原生基础设施“AIOWN”的发展。
 AI资讯
AI资讯日本NTT首次将光网络全长可视化功能集成于通信用DSP芯片,实现边通信边监测,提升光网络运维效率。
 AI资讯
AI资讯NTT Sonority发布以音声技术为核心的DX解决方案品牌SonoVo,结合音声AI、现场通信设备及本地通信方案,提升现场工作效率。
 AI资讯
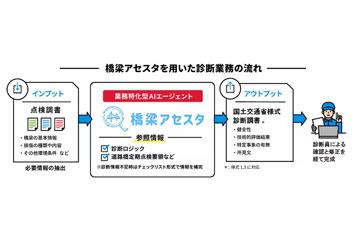
AI资讯日本NTTドコモ解决方案株式会社(原名:NTTコムウェア株式会社)、日本NTTドコモ株式会社及日本溝田设计事务所三家公司于23日宣布,联合开发了基于生成式AI技术和RAG(检索增强生成)技术的桥梁诊断辅助服务“桥梁アセスタ”,该项目由日本国立大学法人长崎大学监督指导。自当天起,日本NTTドコモ业务株式会社(原名:NTTコミュニケーションズ株式会社)开始面向从事桥梁定期检查的建设咨询公司及民间桥梁管
 AI资讯
AI资讯日本NTT公司成功开发出全球首创的推理技术,能够在不降低精度的情况下缩减大型语言模型(LLM)中的输入输出单位“Token”的词汇量,实现不同LLM之间Token词汇的统一。 大型语言模型通过“Token”这一单位处理文本,推理时会基于概率预测下一个Token。然而,不同LLM使用的Token词汇通常各不相同,这导致模型之间无法直接比较或共享推理过程中的预测结果,形成了所谓的“词汇壁垒”。因此,
 AI资讯
AI资讯日本NTT推出了升级版大规模语言模型“tsuzumi 2 Vision”,实现了对带图表文档的高精度读取和理解。
 AI资讯
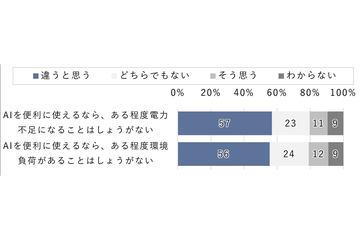
AI资讯日本国家NTT Docomo移动社会研究所于2026年2月发布了一项关于生成式AI使用状况的调查结果。 此次调查针对日本全国15岁至69岁的群体,重点了解在生成式AI使用日益普及的背景下,人们对电力供应问题的看法。 调查显示,对于“如果AI使用便利,某种程度上的电力不足是可以接受的”这一观点,57%的受访者表示不同意;而对于“如果AI使用便利,某种程度上的环境负担是可以接受的”,56%的受访者也
 AI资讯
AI资讯日本国家NTT Docomo移动社会研究所发布了关于生成式AI使用状况的调查结果。该调查与2025年2月的类似调查相比,揭示了一年内的显著变化。 数据显示,生成式AI的使用率预计将从2025年的27%几乎翻倍至51%。按年龄段统计的私人用途和工作学习用途的生成式AI使用率显示,私人用途的总体使用率为46%(2025年为23%),工作和学习用途为38%(2025年为20%),两者均实现了翻倍增长,
 AI资讯
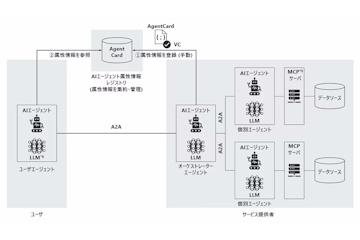
AI资讯日本NTT通信商务株式会社(前身为NTTコミュニケーションズ)于12日宣布,面向未来AI代理自主进行交易和协作的社会,开始对AI代理自身信任性确认机制进行技术验证。此次验证开发了一个名为“AI代理属性信息注册表(暂称)”的原型系统,用于统一管理和验证AI代理的属性信息,并检验其有效性。 NTT通信商务指出,随着专门执行特定任务的AI代理应用日益广泛,近年来多AI代理协同完成复杂任务的多代理系统也逐