日本NTT公司成功开发出全球首创的推理技术,能够在不降低精度的情况下缩减大型语言模型(LLM)中的输入输出单位“Token”的词汇量,实现不同LLM之间Token词汇的统一。
大型语言模型通过“Token”这一单位处理文本,推理时会基于概率预测下一个Token。然而,不同LLM使用的Token词汇通常各不相同,这导致模型之间无法直接比较或共享推理过程中的预测结果,形成了所谓的“词汇壁垒”。因此,结合多个模型预测结果的集成学习(Ensemble)或将知识迁移到其他模型的便携式调优(Portable Tuning)等跨模型Token级协作变得非常困难。
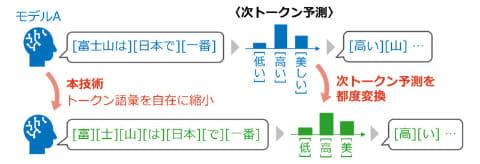
此次研究创新性地提出了一种技术,能够灵活缩减LLM使用的Token词汇而不损失推理精度。该技术将推理时的下一个Token预测限定在指定的部分Token集合中进行。
基于独创的转换算法,该方法在保持整体文本语义趋势的同时,实现了任意子词汇集上的推理。这使得不同词汇体系的LLM能够通过“最大公共词汇”进行推理协同,从而实现集成学习的知识融合和便携式调优的知识迁移。
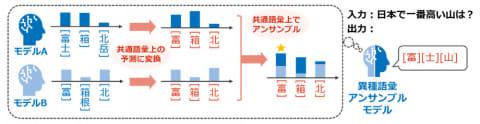
实验结果表明,即便是词汇不同的LLM,也能在保持性能的同时通过共享Token词汇实现协同推理,且推理精度有所提升。