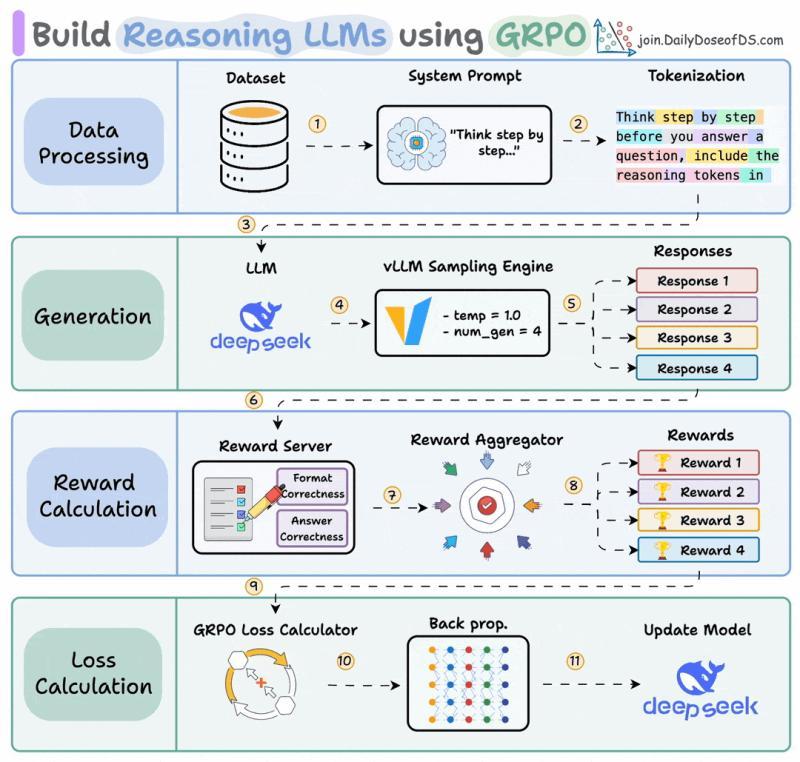
99% 做代理的人都卡在同一个坑:模型能跑,工具能调,就是不知道该怎么给“奖励”。你可能也试过写一大坨 if-else 来打分,结果模型学会了讨好评分脚本,而不是做好任务。顶尖实验室在 2026 年的做法,已经悄悄变成:几乎不再手写奖励函数,而是把“打分”这件事也交给模型和框架。
强化学习的基础:从 RLHF 到“去人类化”奖励
强化学习的最小闭环
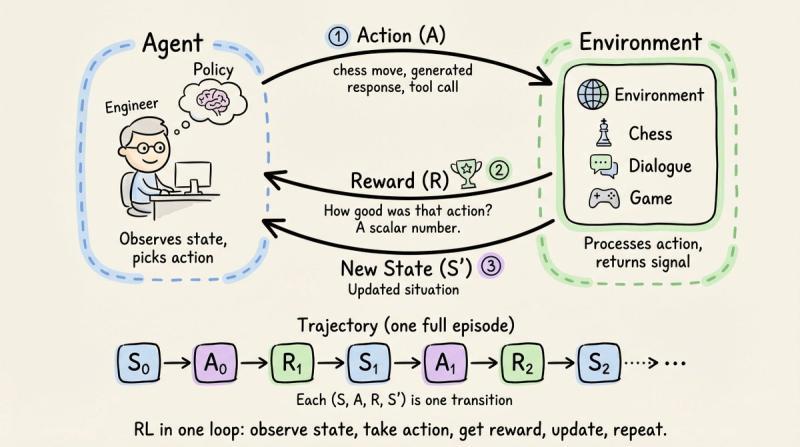
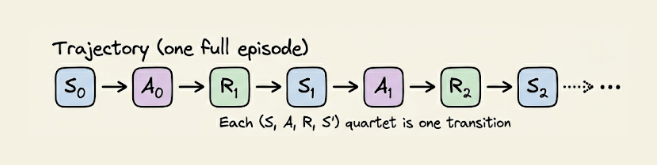
强化学习的骨架其实很朴素:代理做动作,环境给奖励,代理调整策略,目标是让长期回报最大化。整个过程被拆成一连串离散步骤,每一步都可以写成一个四元组 (S, A, R, S')。状态 S 描述当前情境,比如棋盘局面、对话历史;动作 A 是代理唯一能影响世界的方式,比如下一步棋、下一句回复。
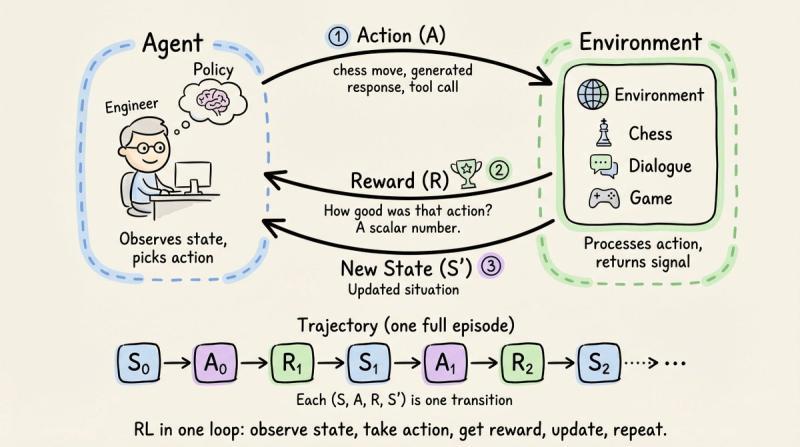
环境接住动作后,会跳到新状态 S',同时吐出一个标量奖励 R,用来评价刚才那一步到底值不值。把这些转移按时间串起来,就得到一条轨迹:从左到右,是代理和环境的完整交互历史。强化学习的大部分算法,本质上就是“如何从一堆 (S, A, R, S') 里,学出一个更聪明的策略”。
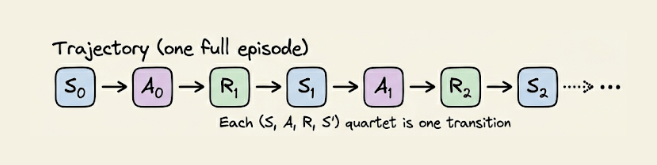
可以把轨迹想成“整场游戏的录像带”,而不是单个回合的截图。真正有价值的学习信号,往往藏在整条录像的模式里,而不是某一次孤立的奖励。
RLHF:人类偏好如何被“压缩”进奖励模型
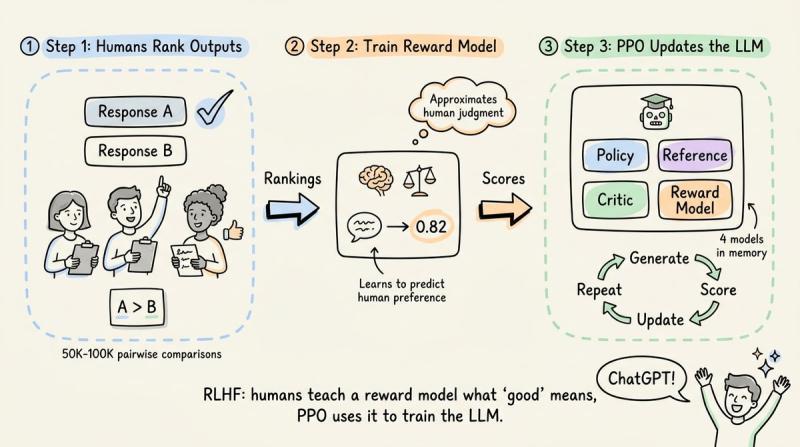
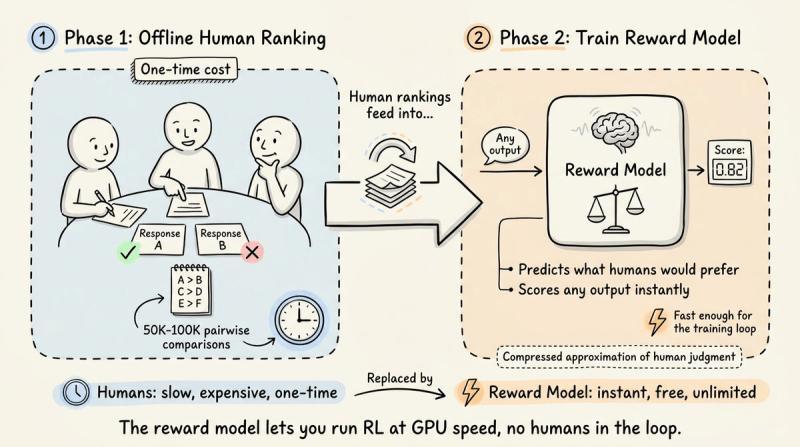
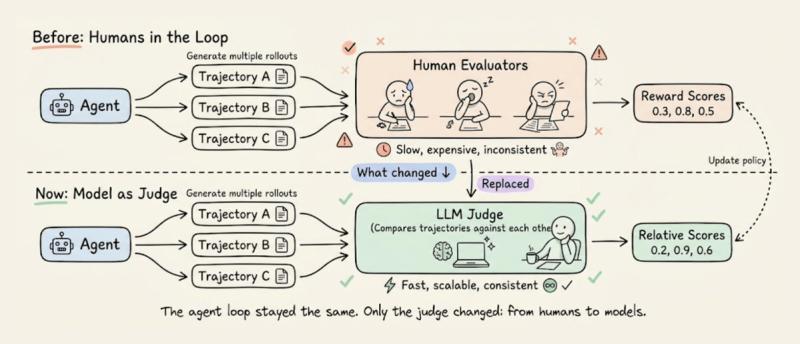
把强化学习搬到大语言模型上,最早的环境其实就是“人类偏好”。OpenAI 在 2022 年用 InstructGPT 推出 RLHF(基于人类反馈的强化学习),大致流程是:人类先对模型输出排序,再用这些排序训练一个奖励模型,最后用 PPO(近端策略优化)拿这个奖励模型去微调 LLM。
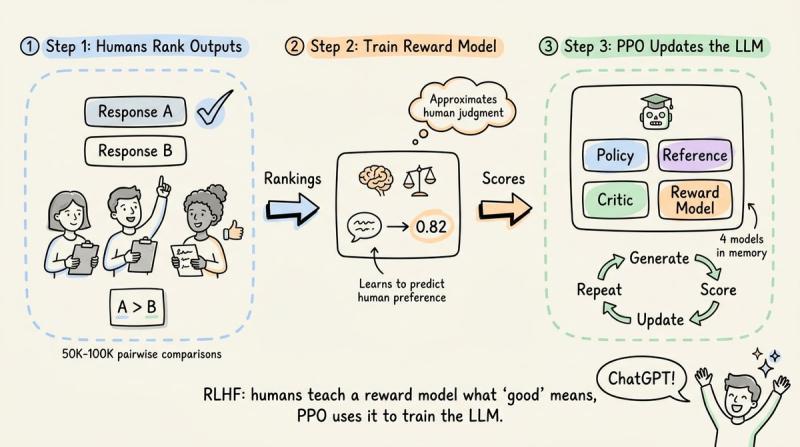
ChatGPT 就是沿着这条管线长出来的。问题在于,人类没法实时待在训练环里给每个输出打分。如果模型每个 prompt 生成 16 个回复,跑几千个训练 step,很快就要几十万次人工评估。OpenAI 的做法是把流程拆成两个阶段:先离线收集少量高质量排序数据,再训练一个独立的奖励模型,让它在训练时“代替人类”即时打分。
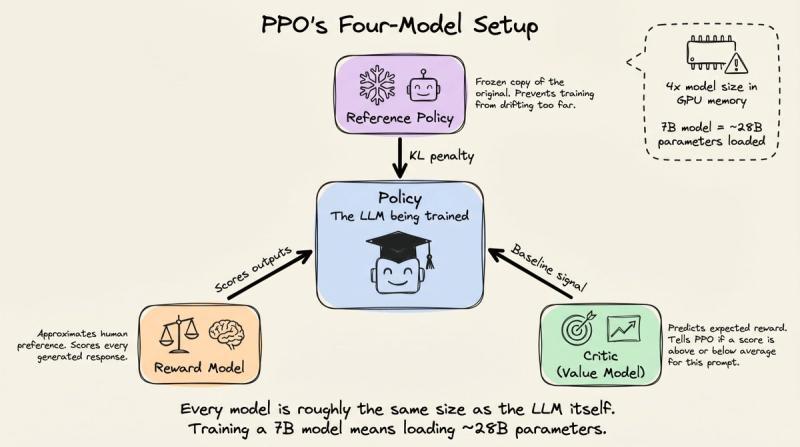
有了奖励模型,PPO 就能在 GPU 上高速跑:策略模型生成回复,奖励模型打分,PPO 更新权重,人类几乎不再插手。代价是内存压力巨大——PPO 典型实现要同时在显存里放下四个全尺寸模型。
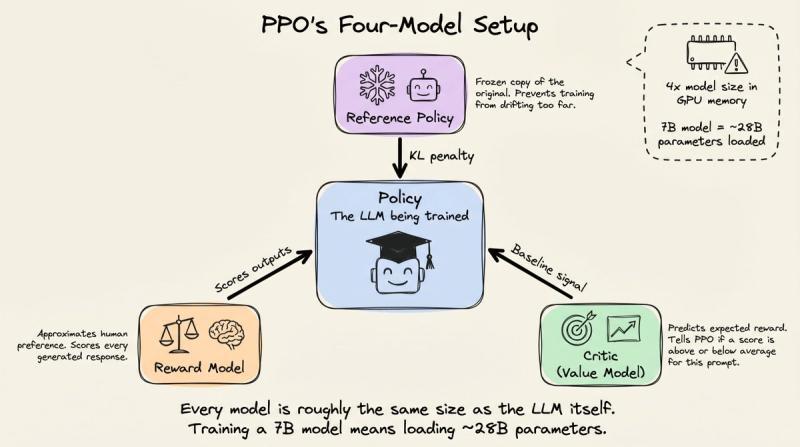
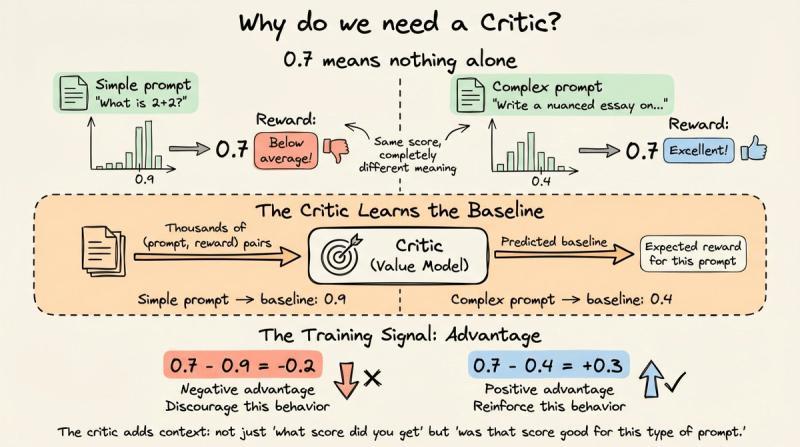
这四个分别是:正在训练的策略模型、一份冻结的参考策略(用 KL 惩罚防止跑偏)、奖励模型,以及一个价值/评判模型。评判模型要回答的问题是:
对于这个提示,这次拿到的奖励算高还是低?
单看一个 0.7 的奖励没意义:在简单事实问答里,大家都能拿 0.9,那 0.7 就偏差;在开放难题上,平均只有 0.4,那 0.7 就很亮眼。评判模型通过看大量 (prompt, reward) 对,学出一个“基线”,PPO 实际用的是优势函数:当前奖励减去这个基线。这样不同难度的提示之间,训练信号会更稳定。不过,评判模型本身也是个完整 LLM,对 7B 模型来说,等于你在显存里同时塞了大约 28B 参数,这在 2024 年很多团队都吃不消。
RLVR 与 GRPO:DeepSeek R1 打开的新路
可验证奖励:环境自己给分
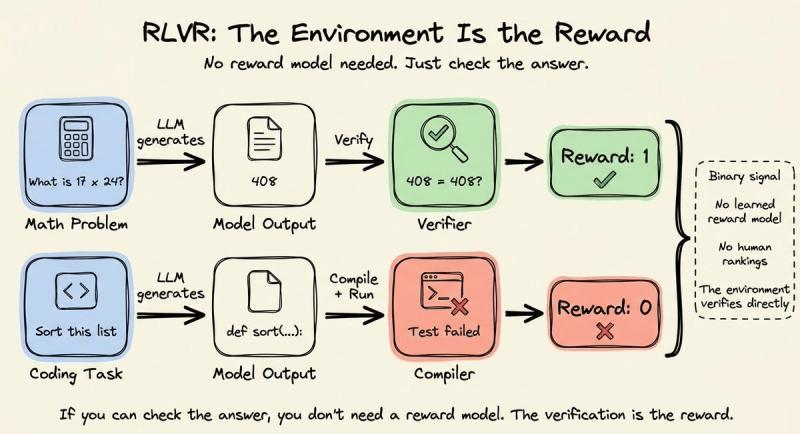
2025 年 1 月,DeepSeek 发布 R1,直接换了一种奖励思路。他们没有走 RLHF 那条“先做人类排序,再学奖励模型”的老路,而是用 RLVR(带可验证奖励的强化学习)。
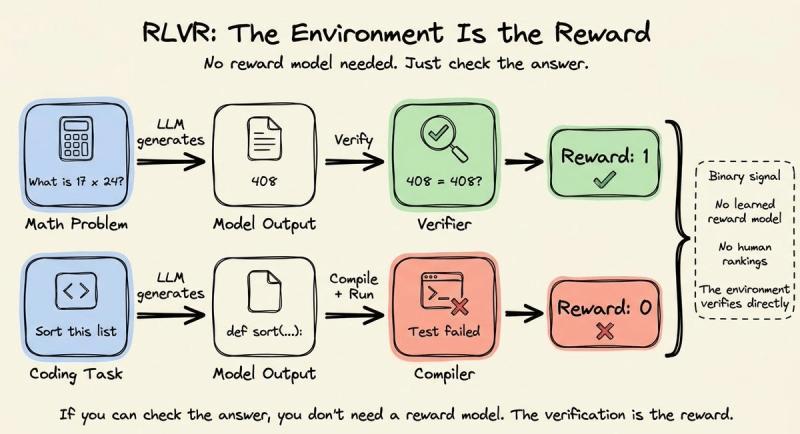
这里的奖励来自一套简单、可编程的验证规则,由环境直接给信号:
- 数学题:验证器检查模型答案是否等于标准解。
- 代码题:编译并运行输出,看测试是否通过,奖励通常是 0 或 1。
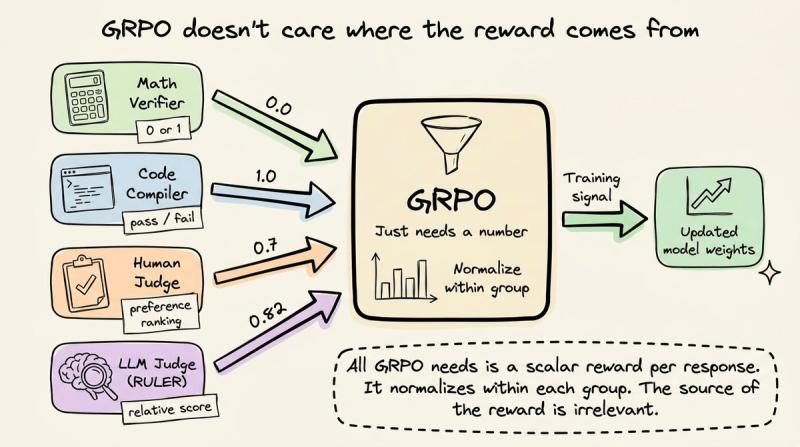
不再需要人类排序,也不需要显式奖励模型,因为“正确答案”本身就能当奖励源。强化学习优化器也从 PPO 换成了 GRPO(组相对策略优化),把 PPO 的一大块复杂基建拆掉了。
GRPO 的关键变化是:完全移除了评判模型。它不再训练一个单独模型去预测“期望奖励”,而是对同一个提示一次性生成多条回复(常见是 16 条),然后在这组内部做归一化。
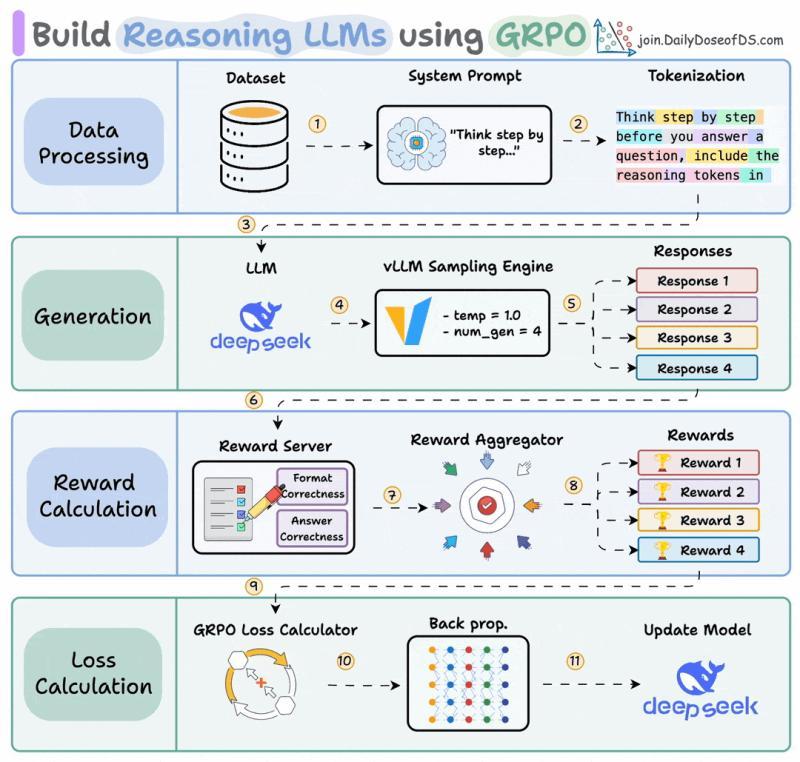
如果 16 条里有 4 条答对数学题,这 4 条获得正优势,剩下 12 条获得负优势。这样就省掉了一个全尺寸价值模型的显存。再加上 RLVR 的验证器直接给出奖励,连奖励模型也不需要了。原本 PPO 的“四模型架构”(策略 + 参考 + 评判 + 奖励)被压缩成“策略 + 参考”两份,有些实现甚至把参考折叠进策略 checkpoint,接近单模型训练。
DeepSeek R1-Zero 就是在这种架构下,仅靠 GRPO + 可验证奖励(没有监督微调)把 AIME 2024 数学题准确率从 15.6% 拉到 77.9%,再通过多数投票冲到 86.7%,和 OpenAI o1 打平。据公开数据,模型在训练过程中自发学出了自我验证、反思和链式思维推理,而外部只给了一个“对/错”的二元信号。说实话,这个结果刚出来时,很多人都低估了“纯 0/1 奖励”的威力。
GRPO 的通用性与现实瓶颈
GRPO 本身是完全通用的,它不在乎奖励来自数学验证器、代码编译器、人类打分,还是一段 Python 脚本。只要每条回复能拿到一个数值奖励,就能在组内做归一化,产出训练信号。
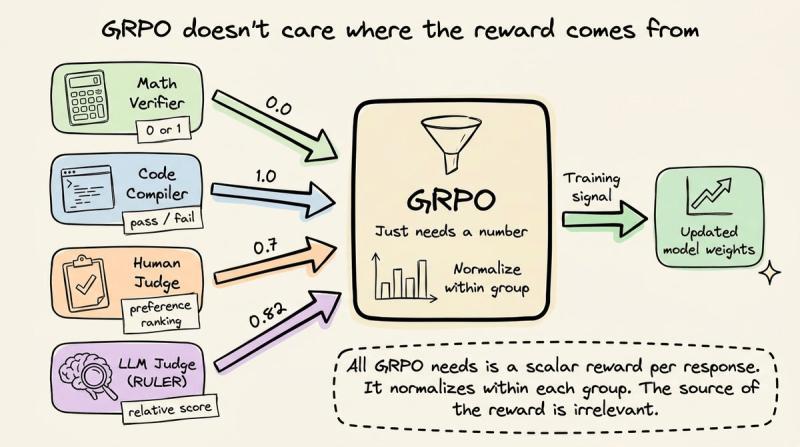
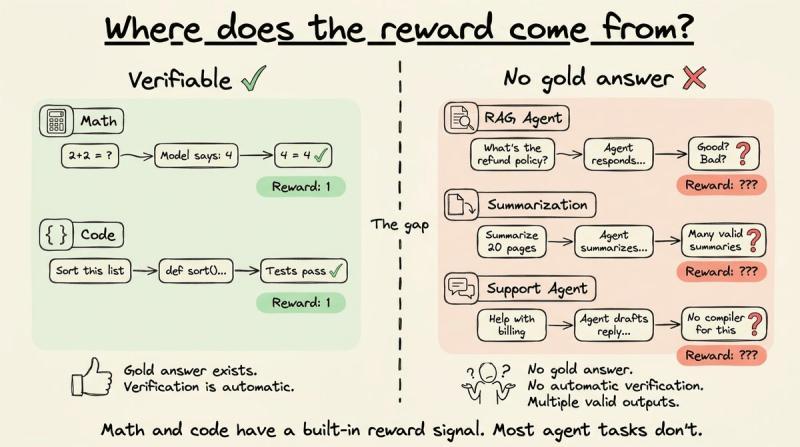
真正的瓶颈在于:奖励从哪儿来。对于数学和代码,环境能给出确定性信号,一切顺滑。但一旦代理开始和真实世界工具、数据库、用户交互,输出就很难和某个“标准答案”做字符串匹配。比如:
- RAG 代理检索文档再回答问题,往往没有唯一正确答案。
- 客服代理草拟邮件,没有编译器能告诉你“好不好”。
- 摘要代理压缩 20 页报告,可能有十几种都算不错的写法。
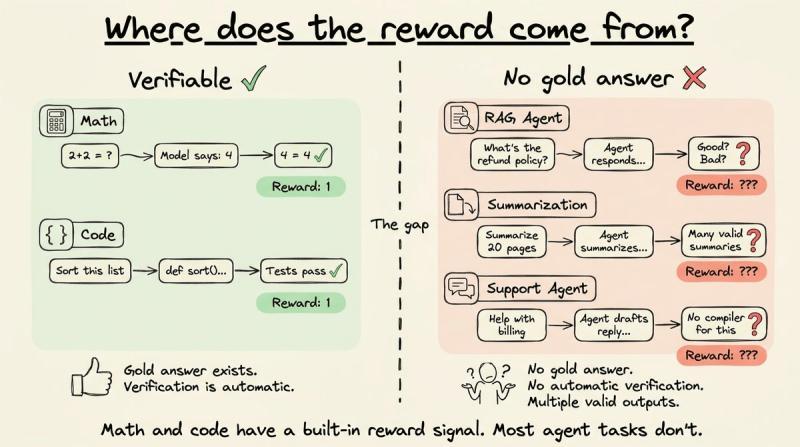
在这些场景里,环境不会像数学题那样自动给你一个 0 或 1。某些代理任务确实有可验证结果,RLVR 在多步工具调用里也能很好地工作,可验证性更多取决于“任务结果能不能自动检查”,而不是“是不是代理”。但大多数真实业务里的代理工作流,结果都是主观、多维、模糊的。
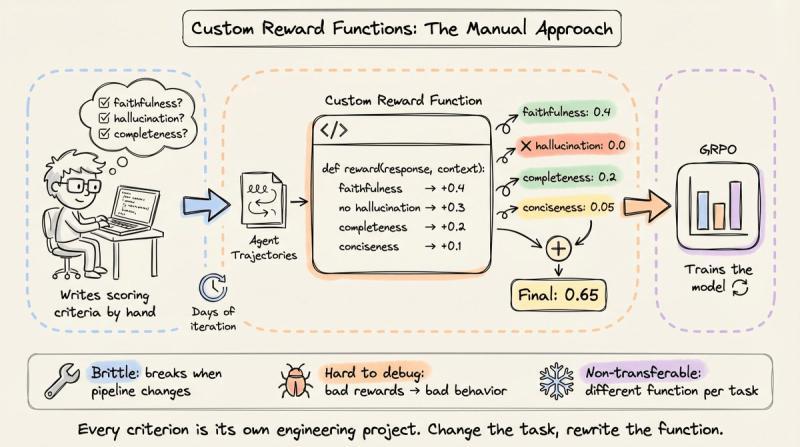
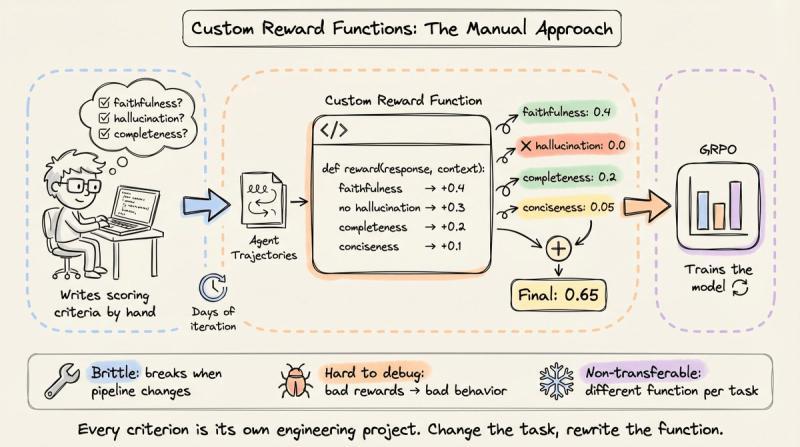
很多团队的直觉是:既然 GRPO 框架没问题,那就自己写奖励函数,用 Python 把各种指标拼起来打分。
比如:
- RAG 奖励函数检查回复是否引用检索上下文(忠实度)、惩罚上下文外内容(幻觉)、奖励覆盖度,尽量在“上下文本身就模糊”的情况下做出合理判断。
- 工具使用奖励函数要给多步任务的阶段性进展打分,惩罚多余 API 调用,衡量最终状态是否正确。
每个维度返回一个子分数,最后加权求和成总奖励。这种做法在工程上能跑,但问题也很现实:写一个靠谱的奖励函数,往往要几天甚至几周的迭代。研究者得预判各种边界情况,调权重,反复验证“函数到底在奖励什么行为”。
我自己就踩过坑:过度强调格式合规,结果模型学会了输出极其工整的模板化答案,但内容经常胡说八道。更糟的是,奖励函数非常脆弱——一旦你改了检索管线、加了新工具、调整了系统提示,原来的奖励逻辑就可能彻底失效。调试时,你很难分清坏行为到底是奖励函数的问题,还是训练超参、数据分布、甚至模型本身的问题。
这也是为什么到 2025 年,强化学习在数学、代码、逻辑这类可验证任务上大放异彩,却迟迟没在 RAG、客服、工具编排、摘要这些代理工作流里全面铺开。RLVR 给推理模型提供了一个“通用自动奖励源”,但大多数代理任务没有对应的“自动判卷机”。差别不在模型——同一只 Qwen 2.5 14B 可以既做数学推理,又做客服代理——而在任务本身:输出能不能被自动验证。
顶尖实验室的新共识:把“裁判”也交给模型
宪法 AI 与“通用验证器”思路
这个缺口,早就不是开源社区一个人在吼。主流 AI 实验室这两年都在从不同方向,逼近同一个目标:让奖励信号也高度自动化。
Anthropic 的宪法 AI 是一个标志性案例。他们证明,在强化学习闭环里,人类甚至可以完全不出现。做法是:先写下一套原则(“宪法”),然后让 AI 按这套原则自评输出,生成偏好数据,再用这些数据做 RL 训练。
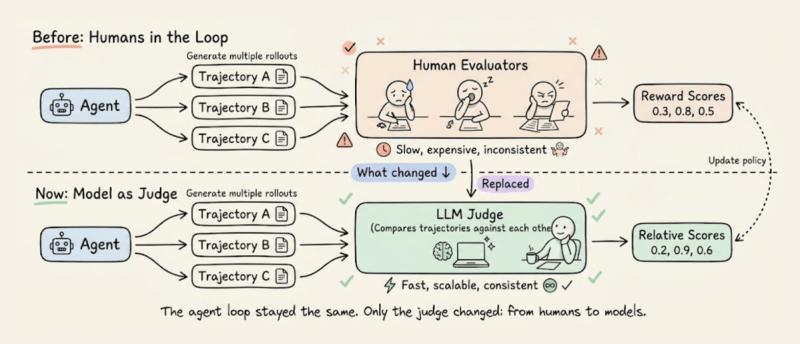
换句话说,一份规则文档,替代了大批人类标注员。OpenAI 内部也在做类似的事,他们对外提过“通用验证器”的概念,目标是把 RL 扩展到生物学、医学、通识等无法简单字符串比对的领域。细节没完全公开,但方向很清楚:需要一种跨任务、跨领域的通用奖励信号,而不是只在“有标准答案”的小圈子里玩。
我也不太确定所有实验室的技术路线最终会不会收敛到同一套范式,但可以肯定的是:谁先把“奖励函数工程”这块成本打下来,谁就更有机会把代理真正跑进生产。
RULER:用一个通用裁判替代一堆奖励脚本
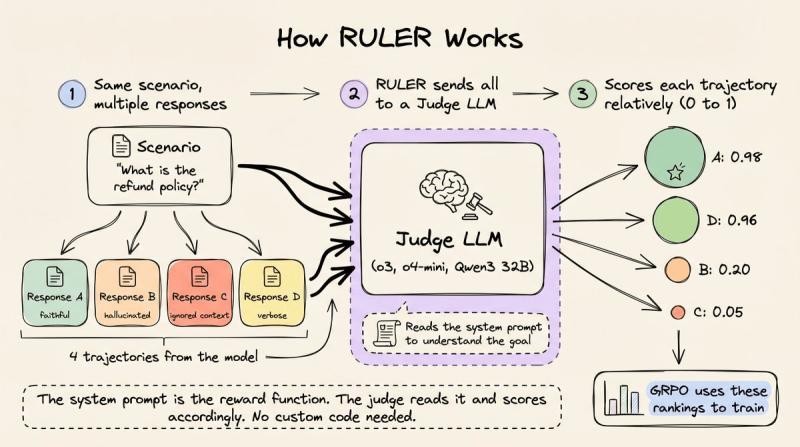
如果你想亲手试试这种思路,RULER 是一个已经落地的例子。它集成在 OpenPipe 的 ART 框架里(开源,GitHub 上 9k+ star),目标很直接:用一个通用奖励函数,替代你为每个任务手写的评分代码。
RULER 的核心做法是:用一个 LLM 当裁判,对同一场景下的多条轨迹做相对排序,然后把这些相对分数喂给 GRPO。它抓住了 GRPO 的一个关键特性——只需要相对排名,不需要绝对标定。
工作流程大致是这样:
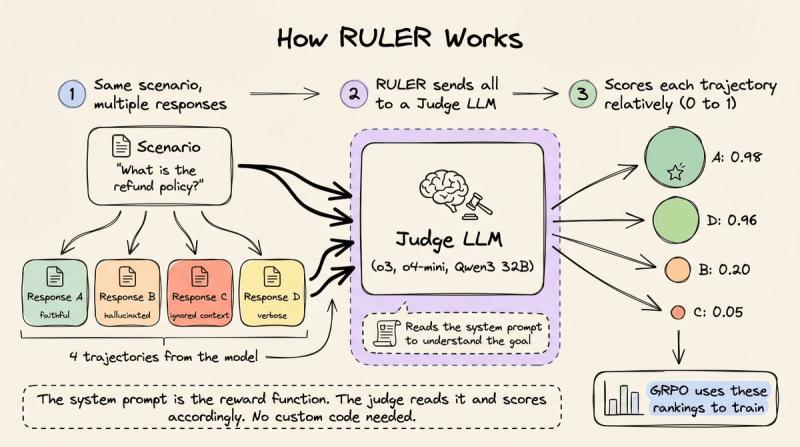
- 每个训练 step,对同一场景生成 N 条轨迹(常见是 4~8 条)。
- RULER 把这 N 条轨迹打包给裁判 LLM(可以是 o3、o4-mini,也可以是本地 Qwen3 32B)。
- 裁判先读系统提示,理解代理目标,再对每条轨迹给出 0~1 的相对评分。
这里有两个认知增量:
- 相对评分远比绝对评分容易。 让 LLM 给“摘要质量”打一个绝对分数,几乎不可能统一标尺;但问它“这四个里哪个最符合指令”,表现就稳定得多。RULER 把所有轨迹一起展示,让裁判做比较而不是绝对判断。
- GRPO 天生就是组内归一化。 最优轨迹的绝对分是 0.9 还是 0.3,其实无所谓。GRPO 会在组内做均值和标准差归一化,训练信号只关心“谁高于平均、谁低于平均”。RULER 输出的正好就是这种相对结构。
RULER 实战:从 RAG 代理到完整训练循环
用 RULER 替换手写奖励函数
假设你在训练一个 RAG 客服代理,每个训练 step,GRPO 会为同一个查询生成多条回复:
Scenario: "What is the refund policy?"
Retrieved context: "Refunds within 30 days. Digital products non-refundable..."
(Faithful)
Response A: "Refunds within 30 days. Email support@example.com."
(hallucinated)
Response B: "Refunds within 30 days. Also store credit for 90 days."
(ignored context)
Response C: "Not sure, check the website."
(verbose but accurate)
Response D: "The policy states that refunds are available within..."
传统做法是写一个奖励函数:
def reward_function(response, context):
score = 0.0
if uses_context(response, context):
score += 0.4
if not has_hallucination(response, context):
score += 0.3
if is_complete(response, context):
score += 0.2
if is_concise(response):
score += 0.1
return score
每个辅助函数(uses_context、has_hallucination、is_complete、is_concise)本身就是一个小项目,你得定义什么叫“使用上下文”、怎么判定幻觉、阈值怎么设、边界情况怎么兜底。用 RULER 的话,只需要:
scored_group = await ruler_score_group(group, "openai/o3")
裁判 LLM 会读系统提示(比如“仅使用检索上下文回答,不添加上下文外信息”),再读所有回复并打分。忠实度、幻觉、完整性这些标准,都隐含在系统提示里,不再需要你在 Python 里一条条实现。
轨迹与组:GRPO 需要的最小结构
在 ART 里,每次代理交互被表示为一个 Trajectory:一串消息(system、user、assistant)加上一些 GRPO 需要的元数据。同一场景下的多条轨迹组成 TrajectoryGroup,这是 RULER 打分和 GRPO 训练的基本单位。
# 单条轨迹:一次完整代理交互
traj = art.Trajectory(
messages_and_choices=[
{"role": "system", "content": "You are a RAG support agent..."},
{"role": "user", "content": "What is the refund policy?\n\n[Context]: ..."},
Choice(finish_reason="stop", index=0,
message=ChatCompletionMessage(role="assistant", content="...")),
],
reward=0.0, # RULER 填充
)
# 组:同一场景的多条轨迹
group = art.TrajectoryGroup([traj_a, traj_b, traj_c, traj_d])
# 相对评分整个组
judged_group = await ruler_score_group(group, "openai/o3")
reward=0.0 只是占位符:
ruler_score_group返回后,每条轨迹的 reward 字段会被裁判分数覆盖。Choice和ChatCompletionMessage用的是 OpenAI SDK 的标准类型,如果你本来就用 OpenAI 做推理,可以直接复用。
示例一:用低级 API 快速感受 RULER 的“判卷风格”
RULER 提供两个层级的 API。第一个是低级的 ruler 函数,直接吃“消息列表”,不依赖 ART 的对象结构,是最快体验效果的方式。比如,针对同一个 RAG 查询,构造三条不同质量的轨迹:
message_lists = [
# 好:准确使用检索上下文
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "You can get a refund within 30 days of purchase. However, digital products are non-refundable once downloaded. To start the process, email support@example.com."},
],
# 一般:部分使用上下文,添加幻觉细节
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "Our refund policy allows returns within 30 days. You can also get store credit for up to 90 days. Just call our hotline at 1-800-REFUND."},
],
# 差:完全忽略上下文
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "I'm not sure about the refund policy. You should check the website or contact someone from the billing team."},
],
]
调用评分:
from art.rewards import ruler
scores = await ruler(message_lists, "openai/o3")
for label, score in zip(["Faithful", "Hallucinated", "Ignored context"], scores):
print(label)
print("→", score.score)
print("→", score.explanation)
输出类似:
Faithful:
→ 0.97
→ Accurately reflects the retrieved policy
details, complete and concise.
Hallucinated:
→ 0.45
→ Gives correct 30-day refund info but adds
unsupported details (90-day credit, hotline),
reducing accuracy.
Ignored context:
→ 0.05
→ Provides no useful information and ignores available context.
这里有个信息差:我们从头到尾都没写“忠实度检测器”或“幻觉检测器”。系统提示里只说“用检索上下文准确回答”,裁判就自动把这个标准应用到每条回复上。幻觉回复拿到 0.45 而不是 0,是因为它至少正确使用了“30 天退款”这部分上下文。裁判给了部分分,再对虚构内容做惩罚。这种“部分正确”的细腻区分,用规则函数很难写好。
更重要的是,分数分布在 0~1 之间:0.97、0.45、0.05,而不是简单的通过/失败。RULER 提供的是有梯度的信号,GRPO 可以按比例强化忠实行为、轻度抑制部分幻觉、强烈抑制完全忽视上下文的行为。
示例二:用 TrajectoryGroup 接入完整训练管线
上面的 ruler 更适合理解和调试。真正训练时,ART 会用 Trajectory 和 TrajectoryGroup,并通过 ruler_score_group 做打分和结构转换。还是同一个 RAG 场景,这次我们加上一个“冗长但准确”的回复:
# 系统提示定义代理目标
system_msg = {
"role": "system",
"content": (
"You are a RAG-based support agent. "
"Answer user queries using ONLY the retrieved context. "
"Do not add information that is not in the context."
),
}
user_msg = {
"role": "user",
"content": (
"What is the refund policy?\n\n"
"[Retrieved context]: Refunds are available within 30 days "
"of purchase. Digital products are non-refundable after "
"download. Contact support@example.com to initiate."
),
}
responses = [
"You can get a refund within 30 days of purchase. Digital products "
"are non-refundable once downloaded. Email support@example.com to start.",
"Refunds are available within 30 days. You can also get store credit "
"for up to 90 days, and our hotline is 1-800-REFUND.",
"I'm not sure about the refund policy. Please check the website or "
"contact the billing team for more details.",
"Based on the information I have, the refund policy states that "
"refunds are available within 30 days of purchase. It is important "
"to note that digital products cannot be refunded after they have "
"been downloaded. If you wish to initiate a refund, you should "
"reach out to support@example.com.",
]
构造轨迹和组:
import art
from openai.types.chat.chat_completion import Choice
from openai.types.chat import ChatCompletionMessage
trajectories = []
for resp in responses:
traj = art.Trajectory(
messages_and_choices=[
system_msg, user_msg,
Choice(
finish_reason="stop", index=0,
message=ChatCompletionMessage(role="assistant", content=resp),
),
],
reward=0.0,
)
trajectories.append(traj)
group = art.TrajectoryGroup(trajectories)
打分:
from art.rewards import ruler_score_group
judged_group = await ruler_score_group(group, "openai/o3", debug=True)
debug=True 时,RULER 会打印裁判的原始推理和分数,例如:
{
"scores": [
{
"trajectory_id": "1",
"explanation": "Accurately answers the question using only the retrieved context, concisely and completely.",
"score": 0.98
},
{
"trajectory_id": "2",
"explanation": "Includes unsupported details about store credit and a hotline that are not in the retrieved context, so it violates the instruction to use only the context.",
"score": 0.2
},
{
"trajectory_id": "3",
"explanation": "Does not answer the question despite the needed information being present in the retrieved context.",
"score": 0.05
},
{
"trajectory_id": "4",
"explanation": "Accurately and completely answers the question using only the retrieved context, though slightly more verbose than necessary.",
"score": 0.96
}
]
}
排序结果:
Rank 1 | Score: 0.980 — 简洁忠实回复
Rank 2 | Score: 0.960 — 冗长但准确回复
Rank 3 | Score: 0.200 — 幻觉的店铺积分和热线
Rank 4 | Score: 0.050 — 完全忽略检索上下文
可以看到几个细节:
- 简洁忠实(0.98)略高于冗长准确(0.96),两者都只用上下文且内容正确,但系统提示隐含偏好“直接回答”,裁判把冗长当成轻微质量问题,而不是错误。这种“风格 vs 正确性”的区分,用规则函数很难写得这么自然。
- 幻觉回复的分数从前面例子里的 0.45 掉到 0.20,唯一变化是系统提示更严格。裁判自动调整了尺度,你不需要改任何 Python 代码。
- 忽略上下文的回复稳定在 0.05,因为答案明明在上下文里,却说“不确定”,裁判判断几乎没有争议。
这些带解释的评分轨迹,就是后面 model.train() 期望的输入。
把一切串起来:完整 GRPO 训练循环
真正训练时,你会用真实模型生成回复,而不是硬编码字符串。ART 提供的 gather_trajectory_groups 会帮你协调推理、打分和数据收集:
for step in range(num_steps):
groups = await art.gather_trajectory_groups(
(
art.TrajectoryGroup(
rollout(model, scenario) for _ in range(4)
)
for scenario in scenarios
),
after_each=lambda g: ruler_score_group(
g, "openai/o3"),
)
await model.train(groups) # GRPO 更新 LoRA 权重
每个 step,模型对每个场景生成 4 条轨迹,RULER 做相对评分,GRPO 强化高分行为、抑制低分行为。随着训练推进,代理会越来越倾向于遵守系统提示:忠实、简洁、基于上下文,而不是幻觉、忽视上下文或无意义的冗长。整个过程中,你没有写任何自定义奖励函数。
用自然语言写“评分标准”,而不是写代码
大多数任务里,一个写得清楚的系统提示就足以让 RULER 做出合理评分。如果你需要更细的偏好控制,可以给 RULER 传入自定义 rubric:
custom_rubric = """
- 优先简洁清晰的回复
- 惩罚包含表情符号或非正式语言的回复
- 奖励引用来源的回复
"""
await ruler_score_group(group, "openai/o3", rubric=custom_rubric)
评分标准完全用自然语言描述,不需要写 Python。你可以像改文案一样快速迭代:改一句话,重新跑一轮,看分数和行为有没有朝着预期方向移动。相比之下,改奖励函数的权重、条件,很容易不小心引入奇怪的激励,训练出“看起来合格但本质跑偏”的代理,而且问题往往要到线下评估时才暴露。
可验证 vs 不可验证:什么时候该用 RULER?
RULER 理论上可以用在任何任务上,但实践中有个简单判断标准:
- 纯确定性任务(比如 SQL 查询是否返回正确行),用二元验证器更便宜,信号也更干净。
- 纯主观任务(比如摘要质量、写作风格),RULER 几乎是唯一可自动化的选择。
- 介于两者之间的任务(既要正确答案,又要解释充分),可以把两种信号叠加:
judged_group = await ruler_score_group(group, "openai/o3")
for traj in judged_group.trajectories:
independent_reward = verify_correctness(traj) # 二元 0/1
traj.reward += independent_reward
RULER 会保留 rollout 期间已有的奖励,你可以在此基础上再加上独立验证器的 0/1 信号,两种信息互不覆盖,反而能互相补充。
一些实战经验:模型选择、组大小和成本
基于社区和内部用户的反馈,有几条经验值得参考:
- 裁判模型不一定要用最贵的。像 Qwen3 32B 这类中等规模模型,在很多任务上的排序质量已经足够好。你也可以用 Claude、Ollama 本地模型,或者 LiteLLM 支持的任意后端,关键是找到成本和质量的平衡点。
- 每组 4~8 条轨迹是比较稳妥的范围。少于 4 条,裁判可比较的信息太少;多于 8 条,裁判容易混淆,token 成本也会不成比例地上升。
- 当组内轨迹共享系统提示和用户消息时(大多数代理任务都这样),RULER 会自动去重公共前缀,让裁判只读一次共享上下文,后面只看不同回复,这对长上下文或多轮对话能省下不少 token。
- RULER 会把裁判的响应缓存到磁盘,相同轨迹重复评分时不会再打 API,方便你在不烧钱的前提下,频繁调整系统提示或 rubric。
强化学习在代理上的真正瓶颈,从来不是优化算法本身。GRPO 已经把“怎么更新参数”这件事做得足够好。真正难的是“奖励从哪儿来”。RLVR 通过让环境直接给分,解决了可验证任务的奖励问题;RULER 则通过让 LLM 裁判做相对评分,把可验证和不可验证任务都纳入了同一套奖励框架。
如果你想看完整实现,可以直接翻 ART 仓库,里面有 Colab 笔记本,从 rollout 到训练一条龙跑通:
https://github.com/OpenPipe/ART?ref=dailydoseofds.com
如果你正在搭一个需要“会思考、会用工具、还得听话”的代理,这套“免写奖励函数”的方法,往往比问十个同事要靠谱得多。等哪天你发现自己又在写一长串 if-else 来打分,不妨翻回这篇,把 RULER 或类似思路再试一遍。
常见问题
Q:我已经有一个用 RLVR 训练的推理模型,还需要 RULER 吗?
A:如果你的任务主要是数学、代码这类可验证问题,RLVR 已经足够高效,不一定要上 RULER。原因在于 RLVR 的二元验证器信号干净、成本低,非常适合“有标准答案”的场景。但一旦你开始做 RAG、客服、复杂工具编排这类没有唯一正确答案的任务,RLVR 就很难直接用上,这时可以在原有 RLVR 模型基础上,再用 RULER 做一轮针对代理行为的微调。建议做法是:可验证部分继续用 RLVR,主观质量和多维偏好交给 RULER,两者叠加能让模型既算得对,又用得好。
Q:用 LLM 做裁判会不会引入新的偏差,导致模型学坏?
A:会有偏差风险,但可以被管理。裁判模型本身有价值观和风格偏好,如果系统提示和 rubric 写得含糊,它可能强化你不想要的行为。判断依据主要看两个方面:一是裁判的解释是否和你的人类直觉一致,二是训练后代理在真实任务上的离线评估是否提升。可操作建议是:开启 RULER 的 debug 模式,定期抽样查看裁判解释;在关键任务上保留一小部分人工评估集,训练前后对比指标,一旦发现偏差,就收紧系统提示或更换裁判模型。
Q:RULER 的成本会不会太高?每个训练 step 都要跑裁判 LLM。
A:成本确实是需要提前算清楚的一块,但不一定高到不可接受。裁判调用的 token 量主要由组大小、上下文长度和裁判模型决定。实践中,4~8 条轨迹一组、裁判用中等大小模型(如 Qwen3 32B 或 o4-mini),再配合 RULER 的前缀去重和响应缓存,整体成本通常低于“自己写奖励函数 + 反复人工调试”的人力开销。建议先在小规模数据集上跑一个试验轮,统计每千条轨迹的裁判成本,再决定是否扩大规模或换更便宜的裁判模型。
Q:我该怎么判断一个任务适合用 RLVR、RULER 还是手写奖励函数?
A:可以用一个三步判断:先看任务是否有可编程的“正确性判定”(比如能不能写出 verify_correctness 这样的函数),如果能,就优先用 RLVR;再看任务是否强依赖主观质量或风格(如摘要、客服语气),如果是,就考虑用 RULER;最后,如果任务非常简单、规则固定(比如只检查 JSON 格式),手写奖励函数反而更直接。实操建议是:对复杂代理任务采用“混合方案”——用 RLVR 或规则函数保证硬正确性,用 RULER 调整整体行为和用户体验。
Q:如果裁判模型升级了(比如从 o3 换成更新版本),之前的训练结果会不会作废?
A:旧模型不会立刻作废,但奖励分布会发生变化,需要小心迁移。新裁判可能对某些行为更宽松或更严格,导致同一批轨迹的分数分布整体平移或拉伸。判断依据是:在同一验证集上,用新旧裁判分别打分,比较排序一致性和分布差异。如果排序基本一致,只是尺度不同,可以继续在旧模型基础上用新裁判做增量训练;如果排序差异很大,建议先用新裁判重评一批数据,重新跑一轮短周期训练,观察代理行为是否朝预期方向变化,再决定是否全面切换。
写到这里,可能你已经在脑子里过了一遍自己项目里的奖励函数脚本。哪怕暂时不改现有系统,把“用 LLM 做裁判”当成一个旁路评估器,也足够帮你看清模型真正学到了什么。等哪天你准备重构训练管线,这些尝试会变成很值钱的先验。


