
美国谷歌公司于3月26日(当地时间)正式发布了最新的实时语音生成模型“Gemini 3.1 Flash Live”。该模型被认为是谷歌迄今为止质量最高的实时语音AI模型。
“Gemini 3.1 Flash Live”是继承自“Gemini 2.5 Flash Native Audio”的新一代语音生成模型。相比前代产品,它在响应延迟和语音理解准确度方面都有显著提升。
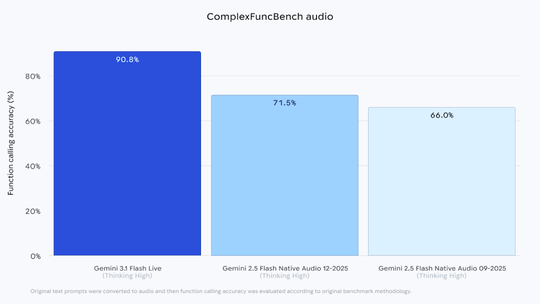
例如,在评估多步骤函数调用等复杂任务的基准测试“ComplexFuncBench Audio”中,该模型取得了90.8%的高分。在评估实际语音环境中处理打断和口吃等复杂指令的Scale AI“Audio MultiChallenge”测试中,启用“Thinking”模式时得分达到36.1%,在同类竞品中名列前茅。
除了性能和质量的提升外,该模型还在音频细节的识别上表现优异。它能更准确地捕捉输入语音的音调和节奏等声学细节,甚至能够检测用户的情绪状态,如困惑或焦躁,并动态调整回复的语调和时长。这一特性有望提升呼叫中心等客户服务场景中的用户满意度,避免传统AI模型带来的冷漠感。
此外,“Gemini 3.1 Flash Live”还增强了噪声消除能力,能够更精准地分离用户的语音,过滤环境噪音。
该模型通过“Gemini Live API”向开发者提供预览版本,普通用户也能通过如“Gemini Live”等应用体验其强大功能,只需对着手机说话,AI即可实时回应。
同时,配合“Gemini 3.1 Flash Live”,谷歌还将在包括日本在内的200多个国家和地区推广“搜索 Live”(Search Live)服务。该服务基于“Gemini Live”,可通过谷歌搜索的“AI模式”访问,适用于需要实时帮助或文本搜索难以满足的场景。
值得一提的是,所有由“Gemini 3.1 Flash Live”生成的语音内容都会自动嵌入谷歌的AI生成内容识别技术“SynthID”电子水印,即使被用于深度伪造,也能被后续检测和验证为AI生成或加工内容。


