
美国谷歌云(Google Cloud)在2026年4月22日至24日于美国拉斯维加斯举办的年度盛会“Google Cloud Next '26”上,正式发布了面向AI计算的第8代张量处理单元(TPU)——TPU 8t和TPU 8i两款产品。
谷歌云自2015年推出首款定制TPU以来,TPU一直搭载专门针对矩阵乘加运算的TensorCore,广泛应用于AI模型的训练和推理计算。
在发布会及分会场中,谷歌云详细介绍了TPU 8t和TPU 8i的架构设计,本文将深入解析这两款第8代TPU的核心特性。
AI训练芯片侧重吞吐量,推理则更需低延迟

过去,AI计算设备(如GPU和TPU)主要追求高吞吐量,即单位时间内处理更多数据,尤其是AI训练阶段需要处理海量数据,因此高吞吐量能显著缩短训练时间。
许多企业在AI模型开发中,训练时间成为瓶颈,因此高吞吐量的计算环境成为首选,这也是NVIDIA GPU广受欢迎的原因之一。
传统上,GPU和TPU通常以8个左右的小规模集群运行,但现今通过NVLink等技术,GPU集群规模已扩展至72个甚至数万、数十万个,实现大规模并行计算。
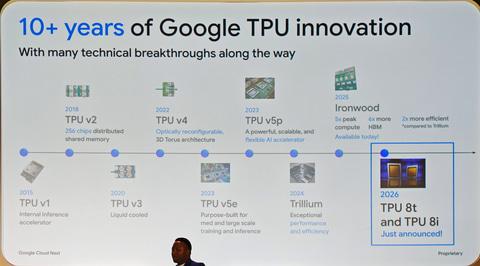
谷歌的TPU同样支持大规模扩展。2025年发布的第7代Ironwood TPU通过名为“3D Tours”的芯片间互联技术,支持最高9,216个芯片的规模扩展,之后可通过以太网实现更大规模的集群扩展。
然而,随着AI代理等应用普及,推理计算需求激增,传统由CPU承担的推理任务开始转向GPU和TPU进行大规模计算。推理不仅需要高吞吐量,更关键的是低延迟(Latency),以保证响应速度。
以大型语言模型(LLM)为例,用户与ChatGPT、Claude、Gemini等AI聊天机器人交互时,若响应延迟过高,用户体验将大打折扣。推理计算的延迟越低,响应越快,应用体验越佳。
同一架构下,训练与推理芯片实现差异化优化
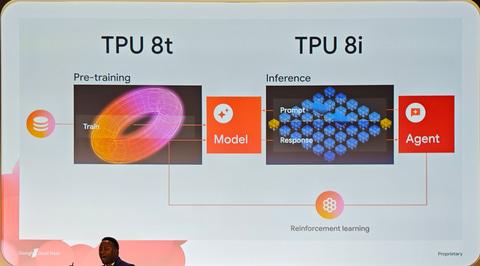
谷歌云在上一代Ironwood TPU中,通过调整集群规模满足训练和推理需求:大规模集群用于训练,小规模集群用于推理。但由于芯片设计相同,推理的低延迟需求未能充分满足。
第8代TPU首次将训练和推理芯片设计区分开,推出专注训练的TPU 8t和专注推理的TPU 8i。名称中“t”代表Training(训练),“i”代表Inference(推理)。
值得注意的是,TPU 8t仍可用于推理,TPU 8i也可用于训练,但各自针对的应用场景更为优化。
谷歌云产品管理负责人Leo Ren表示,Ironwood时代通过大小两种集群满足需求,但推理对低延迟和缓存的需求日益明确,因此TPU 8i增加了更多缓存,采用更大容量的HBM内存,并大幅调整网络拓扑结构,实现更低延迟。

类似趋势也出现在NVIDIA。其在3月GTC大会上公布的Groq LPU芯片,采用不同架构,专注低延迟推理,而Vera Rubin芯片则优化吞吐量,适合训练和大规模推理。两家公司策略的最大差异在于软件兼容性:谷歌云保持相同架构,软件开发模型一致,方便训练与推理共用;NVIDIA则需开发者适应全新软件模型。
面向大型语言模型的TPU 8t功能升级

TPU 8t和TPU 8i的主要区别体现在芯片结构和功能上。根据谷歌云公开资料,TPU 8t采用单个TensorCore芯片加芯片间互联(ICI),而TPU 8i则采用两个TensorCore芯片加ICI和SC-CAE(推理加速引擎)。
TPU 8t的FP4浮点峰值性能达到12.6PFLOPS,是上一代Ironwood的2.73倍,显示出内部计算单元大幅增强。
此外,TPU 8t新增了名为Sparse Core的特殊加速器,支持大型语言模型(LLM)解码引擎(LDE),具备以下功能:
- 加速固定重负载计算
- 卸载MoE(专家模型)通信处理
- 允许LLM解码引擎重叠执行预填充(Prefill)和解码(Decode)阶段
这使得LLM在生成过程中,能够更高效地处理KV缓存和生成Token,显著提升推理速度。
Leo Ren指出,客户通常在同一TPU上同时进行训练和推理,新增的LDE功能对提升整体性能至关重要。
支持最大9,600芯片规模扩展,存储传输性能提升
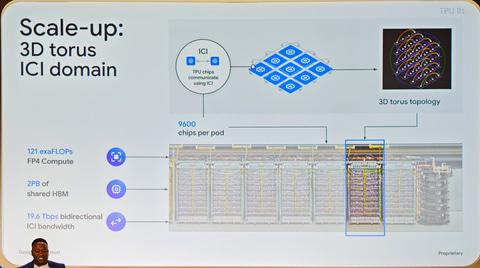
TPU 8t在集群扩展方面也有显著提升。其“3D Tours”技术支持芯片间三维互联,无需交换机芯片即可实现大规模扩展,带宽提升至2.45TB/s,较上一代翻倍。
单个集群最大支持9,600个芯片,较Ironwood的9,216个有所增加。
此外,TPU 8t支持RoCE v2 RDMA和新引入的TPUDirect Storage技术,实现存储到内存的数据高速传输。
在集群网络方面,采用了名为Virgo Network的新技术,支持400Gb/s以太网,较Ironwood的200Gb/s翻倍。利用Virgo Network,集群规模可扩展至13.4万个芯片,性能媲美大型GPU集群。
TPU 8i针对低延迟推理优化,配备大容量缓存和高速内存

TPU 8i专为推理设计,主要特点包括:
- SRAM缓存容量为384MB,是TPU 8t的3倍
- 采用HBM3e内存,容量288GB,带宽提升至8,601GB/s
- 集成了更适合推理的SC-CAE加速引擎于ICI芯片中
- 采用Boardfly拓扑结构进行芯片间通信,降低延迟
通过增加缓存和提升内存带宽,TPU 8i实现了更低的内存访问延迟。
SC-CAE不仅作为Sparse Core工作,还能卸载特定内存调用,延迟比Ironwood降低5倍。
Leo Ren表示,SC-CAE与Boardfly拓扑协同工作,减少网络通信开销,进一步降低延迟。
Boardfly拓扑支持单板4个TPU互联,单机架8个板卡互联,多个机架互联,最大支持1,152个芯片的集群。
PyTorch原生支持,简化CUDA迁移
谷歌云计划为TPU提供PyTorch的原生支持。由于谷歌云主要通过自有中间件(如Vertex AI,现更名为Gemini Enterprise Agent Platform)或虚拟机提供TPU服务,用户可通过这些平台或自行部署软件使用TPU。
此前,谷歌云推荐使用JAX框架,但PyTorch原生支持将极大简化从CUDA GPU迁移到TPU的过程。开发者只需修改极少代码(约3行),即可实现迁移,极大降低了开发门槛。
这对使用PyTorch进行AI开发的程序员来说是重大利好,也有助于推动更多用户从CUDA GPU转向TPU。
供应链信息未公开,期待未来透明化
谷歌云未透露TPU芯片的设计制造厂商及工艺节点,称因合同限制无法公开。尽管理解其难处,但作为半导体基础信息,未来公开相关细节将有助于业界了解芯片性能和技术进步。
此次谷歌云发布的第8代TPU,针对AI训练和推理需求分别优化,显著提升了性能和扩展能力,配合软件生态的完善,预示着谷歌云在AI计算领域的持续领先。


