你以为“全程上最强模型”才是性能上限?很多团队已经发现,这样做既烧钱又浪费算力。真正聪明的做法,是让小模型干活,大模型只在关键节点出手,当成顾问而不是苦力。顾问策略,就是把这种“请教高手”的模式系统化,让代理在需要时才点名大模型。
顾问策略到底在解决什么问题?
大模型不该每个令牌都在线
大多数应用里,90% 的 token 都花在机械执行、查资料、改格式上,只有少数时刻涉及真正困难的推理。把这些简单步骤也交给最贵的模型处理,其实是在用顶级律师帮你排版 Word 文档。顾问策略的核心,就是把“高智商时刻”从“流水线时刻”里剥离出来。
据一些云成本统计,企业在 LLM 上的开销里,有超过 60% 花在重复性、低难度调用上,这部分完全可以由更小的模型承担。换个视角看:你不是在“降级模型”,而是在给大模型“升职”,让它只做真正值得它出手的决策。
可以把顾问策略想成:给你的代理装了一个“知道自己啥时候不行”的开关,一旦意识到超出能力,就自动去请教更强的模型。
顾问 vs 执行者:角色怎么分工?
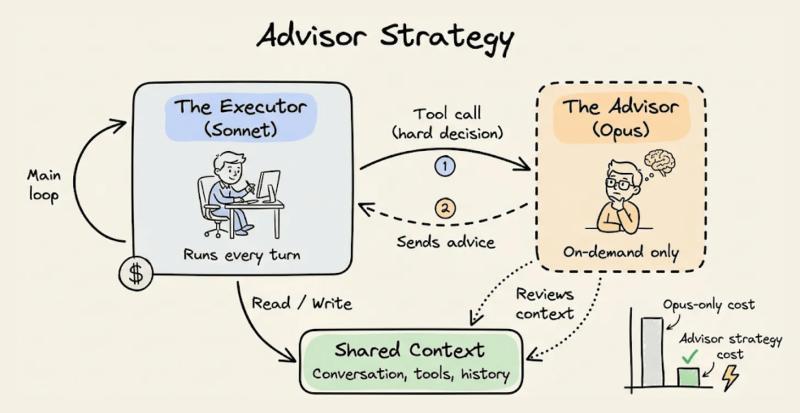
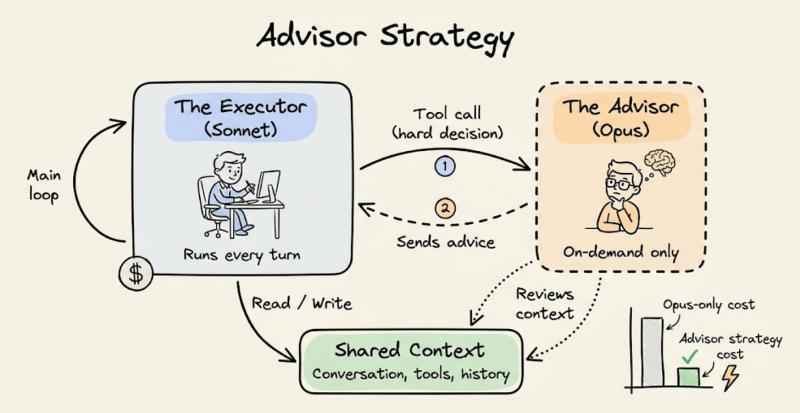
顾问模型负责的是“想清楚”,执行者模型负责的是“做完它”。执行者(比如 Sonnet 或 Haiku)负责调用工具、循环迭代、处理长对话,把流程跑顺。遇到复杂推理、模糊需求、关键决策时,它才向顾问(比如 Opus)发起一次咨询。
一位开发者的实践是:让 Sonnet 负责完整的多轮代码修复流程,只在测试失败三次以上时才请 Opus 给出诊断和修复计划。结果是,整体成功率接近全程用 Opus,但成本压到了原来的三分之一左右。这种“有事请教、没事别打扰”的模式,才是顾问真正的价值所在。
伯克利“顾问模型”论文:小模型教大模型干活
用 7B 模型给黑盒大模型写“提示外挂”
伯克利加州大学在 2026 年 2 月发表的“顾问模型”论文,走的是另一条路:不改大模型,只训练一个小模型来给它“写建议”。他们选用 Qwen2.5 7B,当成顾问,用 GRPO(类似强化学习)训练它生成自然语言建议,然后把这些建议塞进黑盒模型的提示里。
黑盒模型完全冻结,不做任何微调,所有提升都来自顾问学会了“怎么跟它说话”。有点像你不改一个人的智商,只是学会了用他听得懂的方式提问和引导。论文里提到,顾问会逐渐学会一些很细节的技巧,比如在税务题里先帮大模型拆步骤、标出关键条款,再让它计算。
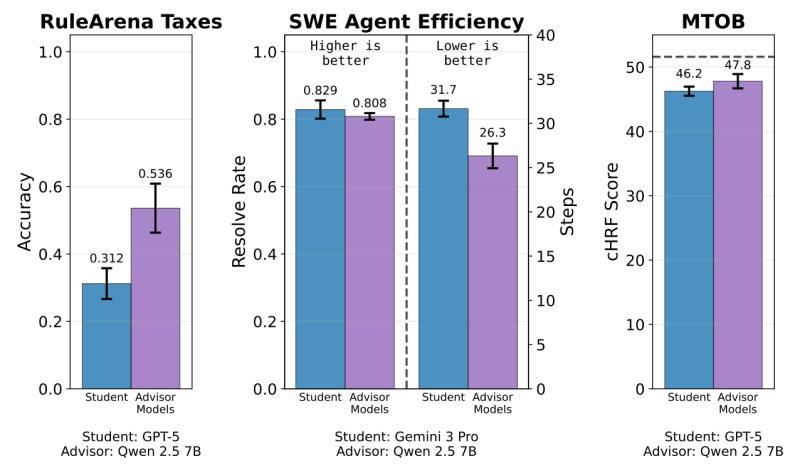
GPT-5 税务测试:31.2% → 53.6%
论文中一个很抓眼球的结果,是在税务申报基准测试上:
- 单独 GPT-5:得分 31.2%
- GPT-5 + 训练好的顾问:得分 53.6%
提升接近一倍,而 GPT-5 本身完全没动,只是多了一个“会说话的搭档”。
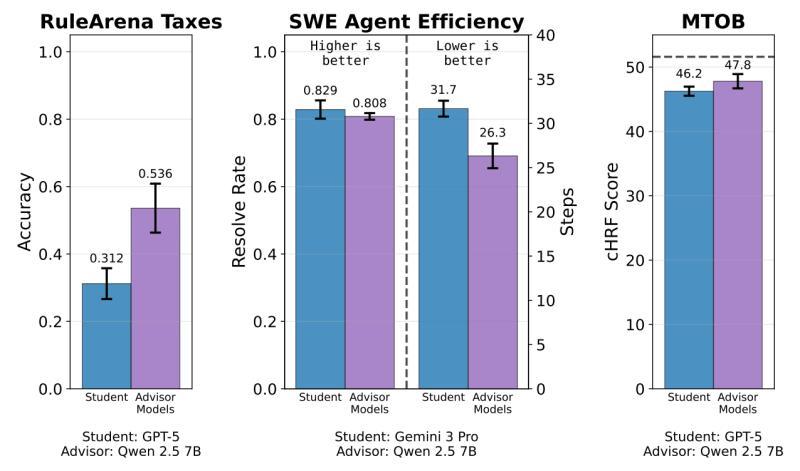
在软件工程代理任务里,顾问还把 Gemini 3 Pro 完成任务的平均步骤数,从 31.7 步压缩到 26.3 步,解决率却保持不变。换句话说,顾问不是让模型“更聪明”,而是让它“少走弯路”。
当然,这种方法也有风险:顾问如果学到的是“错误提示习惯”,反而会系统性地误导大模型。论文里也提到,训练不当时,性能会明显下滑,这点挺值得警惕。
一个容易被忽视的新视角
很多人默认“更大的模型 = 更好的表现”,但这个工作其实在说:
- 同一个大模型,只要换一种被提示的方式,表现可以差一大截。
- 顾问模型的价值,不是“更强”,而是“更懂这个大模型的脾气”。
我也不太确定这个比喻是不是完全贴切,但可以想象成:你给一个顶级专家配了个懂他说话风格的助理,会议效率会突然好很多。
Anthropic 的顾问工具:一行代码接入 Opus 军师
Sonnet/Haiku 干活,Opus 出谋划策
Anthropic 在 Claude API 里提供的“顾问工具”,是把这种理念做成了产品化能力。Sonnet 或 Haiku 作为执行者,负责:
- 处理用户请求和多轮对话
- 调用外部工具、API、浏览器
- 执行计划、循环迭代
当执行者意识到“这题有点超纲”时,就会调用 Opus 顾问,请它给出一个计划、关键判断或修正建议,然后继续自己执行。等于给 Sonnet/Haiku 装了一个“自动请教 Opus 的按钮”。
在 SWE-bench 多语言测试中:
- 单独 Sonnet 的得分是一个基线
- Sonnet + Opus 顾问:分数提升 2.7 分
- 同时,每个任务的成本还下降了 11.9%
在 BrowseComp 测试中:
- 单独 Haiku:得分 19.7%
- Haiku + Opus 顾问:得分 41.2%
分数直接翻倍,这种差距在真实业务里,往往就是“能不能上线”的区别。
一行 API 改动:顾问按 Opus 费率计费
从工程实现上,这件事的门槛被压得很低。你只需要在 tools 里多加一个顾问工具:
response = client.messages.create( model="claude-sonnet-4-6", # 执行者 tools=[ { "type": "advisor_20260301", "name": "advisor", "model": "claude-opus-4-6", "max_uses": 3, },
... 你的其他工具
], messages=[...] )
顾问调用产生的 token 按 Opus 费率计费,但每次顾问调用通常只会生成 400–700 个 token,而且你可以通过 max_uses 控制最多请教几次。对很多长流程任务来说,这点额外开销远低于全程跑 Opus 的成本。
有用户反馈,在一个复杂数据分析代理里,把执行模型从 Opus 换成 Sonnet,再加上 Opus 顾问,整体成本下降了约 60%,响应时间也缩短了三分之一左右,体验上几乎感觉不到“降级”。
风险与坑:顾问不是万能药
顾问策略听上去很香,但也有几个现实问题:
- 触发逻辑设计不好,可能导致频繁调用顾问,成本失控
- 顾问给出的计划如果含糊,执行者可能“理解错意”,产生奇怪行为
- 在高风险场景(金融、医疗)里,顾问和执行者之间的责任边界需要额外审计
有一位朋友在做自动化报税代理时,就遇到过“顾问建议过度激进”的情况,导致报表方案虽然合法但风险偏高,最后还是人工审了一遍才敢提交。这类场景里,顾问更适合作为“备选方案生成器”,而不是直接决策者。
如何在自己的代理里用好顾问策略?
什么时候该上顾问?三个判断标准
可以用这三个信号来判断是否值得引入顾问策略:
- 任务长链路、步骤多:比如代码修复、复杂数据分析、长流程自动化,容易在中途走偏,需要关键节点校正。
- 错误代价高:法律、财税、合规、医疗相关内容,哪怕多花一点钱,也要在关键决策上用最强模型。
- 需求模糊、上下文复杂:用户说不清需求、信息来源多且质量参差时,让顾问先帮你“想清楚要做什么”。
如果你的应用只是简单问答、模板生成,顾问策略的收益就没那么明显,甚至可能只是多了一层复杂度。
一个可复用的设计模板
在实践中,可以按这个思路设计你的代理:
- 执行者模型:选一个性价比高的(如 Sonnet、Haiku),负责全流程执行。
- 顾问模型:选一个最强的(如 Opus),限制调用次数和最大 token。
- 触发条件:
- 工程上:当执行者多次尝试失败、工具返回异常、或用户明确要求“高精度”时触发顾问。
- 语义上:让执行者在不确定时主动请求顾问,比如“当你对答案信心不足时,请调用顾问工具复核”。
- 输出结构:要求顾问输出“计划 + 关键判断 + 风险提示”,而不是直接给最终答案,方便执行者落地。
这套模板在不同业务里都能复用,只需要替换工具和领域知识,就能快速搭出一个“会请教高手”的代理。
顾问策略的真正 takeaway
顾问模型和顾问工具,其实都在指向同一个结论:你不需要每个 token 都用最强的模型。更聪明的做法,是在合适的时刻、针对合适的输入,才让最强模型出手。
这个判断方法在不少团队里已经被反复验证有效:先用中等模型跑通流程,再在关键节点插入顾问,大多数场景都能做到“性能接近最强、成本远低于最强”。如果你正准备上一个复杂代理系统,这套思路往往比问十个朋友“用哪个模型好”更有用。
伯克利的论文可以在这里看到:
有空不妨读一读原文,再回头看自己现在的架构,也许会突然发现:你真正缺的不是更大的模型,而是一个会说话的顾问。
常见问题
Q:在什么规模的项目里,引入顾问策略最划算?
A:一般来说,链路较长、单次对话 token 消耗在几千以上的项目,引入顾问策略更划算。因为这类任务中,大部分步骤是机械执行,只需中等模型即可,只有少数关键节点需要高强度推理。做法上,可以先用全程大模型跑一段时间,记录平均 token 和成本,再切换为“中等模型 + 顾问”,对比成功率和费用。如果成功率接近但成本下降明显,就说明顾问策略适合你的场景。
Q:怎么防止顾问被过度调用,导致成本反而升高?
A:关键是设计好触发条件和调用上限。技术上,可以通过 max_uses 限制每次会话最多调用顾问几次,同时在系统提示中明确要求执行者“只有在多次尝试失败或对结果信心不足时,才调用顾问”。还可以在日志里记录每次顾问调用的原因和效果,定期审查哪些调用是“无效咨询”,再通过提示工程或规则优化触发逻辑。必要时,为高成本用户提供“高精度模式”开关,让他们自己决定是否频繁使用顾问。
Q:顾问给出的计划如果和执行者的判断冲突,该听谁的?
A:在高风险领域,优先以顾问的判断为准,但需要额外加一层规则或人工复核。在一般业务场景,可以让执行者在系统提示中被要求“当顾问意见与自身判断冲突时,优先遵循顾问,并在输出中标注冲突点和理由”。工程上,还可以把这类冲突记录下来,作为后续优化提示或微调的数据来源。如果你担心顾问偶尔“想太多”,可以增加一条约束:顾问必须给出清晰的推理链和风险提示,执行者只在推理链完整时才采纳。
Q:顾问策略会不会让系统变得更难调试和监控?
A:复杂度确实会上升,但可以通过结构化日志和可视化工具把问题压住。实践中,建议为每次顾问调用单独打日志,包括触发原因、顾问输出、执行者如何采纳等信息,再在监控面板上区分“普通调用”和“顾问调用”的成功率与成本。调试时,可以先只在沙箱环境开启顾问,观察一段时间的行为模式,再逐步放量到生产。这样做的好处是,你能清楚看到顾问到底在哪些场景帮了忙,在哪些场景只是“多此一举”。
Q:如果我只用一个大模型,把温度调低一点,是不是也能接近顾问策略的效果?
A:只用一个大模型、调低温度,确实能提升稳定性,但解决不了“成本”和“角色分工”的问题。顾问策略的增量在于:让大模型只在关键节点出手,而不是在所有步骤上都消耗昂贵 token;同时,通过顾问-执行者分工,让系统结构更清晰,便于插入审计、监控和人类复核。操作上,你可以先试一段时间“单大模型 + 低温度”,再切换到“中等模型 + 顾问”,对比成本、延迟和成功率,数据会给你一个更直观的答案。


