99% 的人听过 MCP 的“工具、资源、提示”三件套,却没搞清它们真正的边界。很多实现一上来就乱用,结果要么安全策略形同虚设,要么模型能力被白白浪费。MCP 里这三种能力,本质都是服务器暴露给 AI 的功能,只是触发方式、风险级别和控制权完全不同。
- 工具:AI(主机/客户端)可以调用的可执行操作或函数,往往有副作用或外部 API 调用。
- 资源:AI(主机/客户端)可以查询的只读数据源,用来检索信息,没有副作用。
- 提示:服务器提供的预定义提示模板或工作流程,用来塑造模型行为和对话结构。
理解这三者的差异,不只是“概念题”,而是直接决定:你怎么设计权限、怎么做审计、怎么扩展一个 AI 系统。
工具:让模型“动手”的能力
工具是什么:模型的“远程手脚”
工具就是代表 AI 模型去执行某个动作的函数,尤其是那些模型自己算不出来、或者需要接触外部世界的操作。它更像是“远程控制按钮”,按下去就会真的发生点什么,而不是纸上谈兵。很多人误以为工具只是“高级查询”,但据一些团队的实践反馈,超过 70% 的工具调用其实都涉及文件 I/O 或网络请求,这已经是实打实的执行层了。
更关键的一点:工具通常由模型自主触发。也就是说,大模型通过主机,在对话中判断“现在需要查天气/写文件/调接口”,然后主动发起 tools/call 请求。开发者只负责定义工具和权限边界,不直接操控每一次调用。
假设你实现了一个简单的天气工具,在 MCP 服务器代码里用 @mcp.tool() 装饰一个 Python 函数 get_weather。当 AI 调用 tools/call,名称为 get_weather,参数是 { "location": "San Francisco" } 时,服务器就会执行 get_weather("San Francisco"),返回一个包含温度、天气状况等字段的字典。
客户端拿到这个 JSON 结果,再把结构化数据交给模型。模型可以继续推理、也可以把结果转成自然语言回复用户。说白了,工具负责“干活”,模型负责“解释和决策”。
工具调用的安全与控制
工具往往会触达文件系统、网络、甚至内部业务系统,所以安全策略绝不能走过场。很多 MCP 实现会要求用户对工具调用进行授权,这不是多此一举,而是防止模型在你没注意时做出高风险操作。
有用户反馈,在接入文件写入类工具后,第一次看到客户端弹出“AI 想使用 ‘write_file’ 工具,是否允许?”时,才真正意识到:模型已经不只是“聊天”,而是能改动真实环境了。
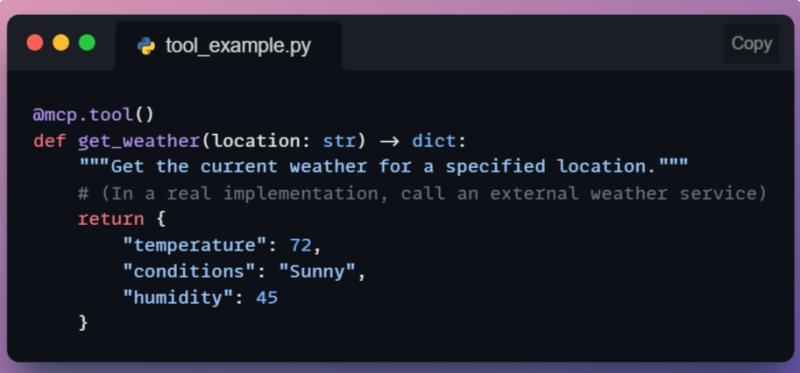
以 Claude 的客户端为例,当模型首次尝试调用 get_weather 之类的工具时,界面可能弹出提示:“AI 想使用 ‘get_weather’ 工具,是否允许?”。用户点确认后,工具才会真正执行。这种“人类在环”的设计,让强操作始终在可控范围内。
工具和传统编程里的函数很像,但在 MCP 里,它们运行在一个更动态的上下文中:
- 由模型决定何时调用,而不是由人类写死调用时机。
- 执行前后可以有治理策略,比如审计日志、频率限制、参数白名单。
- 不同主机或客户端可以对同一工具施加不同的权限规则。
我自己的观察是,如果把所有事情都做成“工具”,系统会变得很难管控。更合理的做法,是把“有副作用、需要审计”的能力做成工具,把“只读信息”放到资源里,这样权限模型会清晰很多。
资源:给模型看的“只读世界”
资源的角色:模型的外部记忆
资源提供的是只读数据,它们更像数据库、知识库或文件系统的窗口。模型可以通过主机或客户端发起查询,拿到一段文本、一个配置、或一条记录,但不能通过资源去修改任何东西。
和工具相比,资源通常不做复杂计算,也不产生副作用。它们的核心价值是“信息查找”,而不是“执行动作”。比如:
- 本地文件内容(如
/home/user/notes.txt的文本)。 - 公司知识库或文档片段。
- 数据库查询结果(严格只读)。
- 静态配置数据、规则表、FAQ 等。
有一个常被忽略的差别:资源访问往往由主机应用控制,而不是模型自己随意发起。用户说“用公司手册回答我的问题”时,主机可以先调用资源检索相关手册章节,再把结果作为上下文发给模型,而不是让模型自己去“乱翻文件”。
资源访问的方式与边界
一个简单的资源例子,是读取文件的函数。你可以用 @mcp.resource("file://{path}") 这样的装饰器,声明一类资源 URI 模板。之后,AI(或主机)向服务器发起 resources.get 请求,传入类似 file://home/user/notes.txt 的 URI,服务器就会执行 read_file("/home/user/notes.txt"),返回文件内容文本。
资源通常通过某种标识符来定位:
- URI(如
file://...、kb://...)。 - 资源名称或 ID(如
company-handbook-section-3)。
而不是像工具那样,通过“函数名 + 参数”来调用。访问节奏也不一样:资源多半是由应用逻辑决定何时取用,避免模型在没有必要时读取大量数据。
从安全角度看,资源是只读的,风险确实比工具低,但也不是零风险。隐私和权限仍然要考虑:
- AI 不应该读取用户未授权的文件或内部文档。
- 主机可以维护一份允许访问的资源 URI 白名单。
- 服务器端也可以对敏感路径做硬限制。
有团队在接入内部知识库资源后,发现模型回答质量大幅提升,但也意识到:如果权限配置不严,模型可能会“顺手”看到一些不该看的内部文档。
资源的意义,在于为模型提供“按需的参考资料”。你可以把它理解成一个更智能、更结构化的检索系统:模型不需要把所有知识都塞进上下文,而是由主机在合适的时机,拉取合适的资源片段给它看。
提示:把经验和流程“产品化”
提示能力:把好用的提示变成接口
在 MCP 语境里,“提示”不是随手打一段 prompt,而是一种能力:服务器可以暴露一组预定义的提示模板或对话流程,用来引导模型的行为。它更像是“可复用的工作流蓝图”,而不是一次性的对话开头。
为什么要把提示单独抽象成能力?原因很现实:很多场景里,提示本身就是核心资产。比如:
- 一个提示把系统角色设为“你是代码审查员”,并约定输入输出格式。
- 一个提示定义了“逐步诊断用户问题”的访谈流程。
- 一个提示专门用于“法律条款解读”,带有大量示例和注意事项。
如果把这些都硬编码在主机应用里,每次更新都要发版,协作也很麻烦。通过 MCP,把提示放到服务器端,就能做到:
- 多个客户端共享同一套专业提示。
- 在不改客户端代码的情况下,随时更新提示内容。
- 不同服务器提供不同领域的“专家提示库”。
提示如何被使用:不是模型自发决定
提示能力通常由用户或开发者触发,而不是模型自己说“我想换个提示”。用户可以在 UI 里选择一个模板,比如“总结此文档”“做代码审查”“帮我写产品需求”,主机再根据选择去服务器拉取对应的提示。
提示一般在模型开始生成之前设置场景:
- 交互刚开始时,主机获取一个“模式提示”(如“你是项目管理助手”)。
- 用户切换模式时,主机重新拉取对应提示,重建对话上下文。
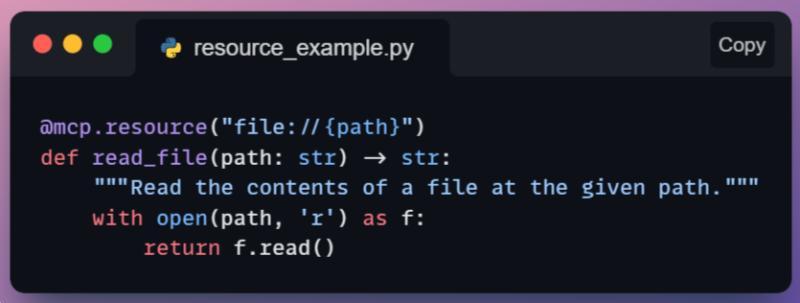
假设你有一个代码审查的提示模板,MCP 服务器提供一个提示函数,返回一组 OpenAI 格式的消息对象:包含 system 角色说明、示例对话等。当主机调用这个提示能力时,会拿到这些消息,然后把用户的实际代码插入到 user 消息里,再一起发给模型。
模型在回答前,就已经被“放进了一个代码审查场景”。服务器相当于帮你把对话结构搭好了,而不是每次都手写一长串 prompt。
有用户分享过一个体验:把团队内部约定的“代码审查 checklist”做成 MCP 提示后,新人只要选中“代码审查模式”,模型就会按 checklist 一条条检查,效果比临时聊天稳定太多。
目前提示能力的常见用法包括:
- 头脑风暴指南(比如强制模型给出多种思路)。
- 逐步问题解决模板(要求模型显式写出推理过程)。
- 行业/领域特定的系统角色(如“税务顾问”“安全审计员”)。
把这些放在服务器端,有一个隐性好处:团队可以像维护代码一样维护提示,做版本管理、评审和 A/B 测试,而不是靠个人记忆和复制粘贴。
三种能力的关键差异与实用判断法
一眼分辨:工具、资源、提示怎么选?
很多人设计 MCP 能力时最常见的困惑是:到底该做成工具、资源,还是提示?可以用一个简单的三步判断法:
- 会不会改变外部世界?
- 会:优先考虑做成工具(写文件、发请求、改配置)。
- 不会:继续看下一步。
- 主要是“查信息”还是“定行为”?
- 查信息:更适合做成资源(文档、数据库、配置)。
- 定行为:更适合做成提示(角色、流程、风格)。
- 谁来决定何时调用?
- 由模型自主判断:偏向工具。
- 由主机/用户显式选择:偏向资源或提示。
这个判断方法在不少项目里被反复验证有效,能大幅减少“全都做成工具”带来的混乱。你可以把它当成一个小 checklist,用来审视每一个新能力的设计。
风险与收益:别只看功能表
从近期不少 AI 产品的迭代来看,大家都在往“模型能直接操作系统”的方向走,比如自动整理文件、批量改文档、直接调业务 API。这些能力几乎都落在 MCP 的“工具”范畴里,带来巨大效率的同时,也放大了风险。
- 工具:高能力 + 高风险,需要授权、审计和节流。
- 资源:中能力 + 中风险,重点是隐私和访问控制。
- 提示:行为塑形 + 低直接风险,但可能带来“过度依赖模板”的问题。
说实话,我也不太确定“提示标准化”会不会让模型变得过于同质化,但至少从工程角度看,把提示当成一等能力,确实让系统更可维护、更可演进。
如果你正打算在项目里引入 MCP,不妨先画一张表,把现有功能按“工具/资源/提示”重新分类一遍。很多隐藏的安全问题和扩展机会,往往就是在这一步被看出来的。
常见问题
Q:设计 MCP 工具时,哪些操作一定要加用户确认?
A:凡是会改变外部世界、且影响不可轻易撤销的操作,都应该加用户确认,比如写文件、删除数据、调用付费 API 或触达生产环境。原因在于模型的决策并非完美理性,可能在错误上下文中触发高风险工具,一旦执行就很难完全回滚。建议做两层防护:一是在客户端弹出明确的确认对话框,说明工具名称、参数和潜在影响;二是在服务器端对高危工具增加白名单或频率限制,避免被循环调用或被恶意 prompt 利用。
Q:资源和工具都能“查信息”,什么时候该用资源而不是工具?
A:如果操作是纯只读、没有副作用,而且主要是从固定数据源里取信息,优先做成资源。原因是资源在权限管理和缓存策略上更简单,也更容易被主机控制访问节奏,不会让模型随意扫全库。实践中可以这样判断:读取文档、查配置、查历史记录,多数适合资源;而需要组合多步计算、聚合多个接口、或可能在未来扩展为可写操作的,更适合先做成工具。建议在设计阶段就给每个能力标注“是否有副作用”“是否需要审计”,再决定归类。
Q:提示能力和在客户端硬编码 prompt 有什么本质区别?
A:最大的区别在于“谁来维护”和“如何演进”。硬编码在客户端的 prompt 更新成本高,每次修改都要发版,而且不同客户端容易出现版本不一致。提示能力则把 prompt 放到 MCP 服务器,由服务器统一提供和更新,客户端只负责按名称或 ID 调用。这样一来,团队可以像维护后端服务一样维护提示:做版本控制、灰度发布、A/B 测试。建议把那些对结果影响大、需要长期打磨的提示(比如代码审查、法律解读)都迁移到提示能力里,而把一次性、临时性的说明留在客户端。
Q:如何防止模型通过资源访问到敏感或隐私数据?
A:关键是把“能看到什么”从一开始就设计清楚,而不是事后补救。原因在于资源虽然是只读,但一旦内容被模型看到,就可能通过回答泄露给用户或外部系统。可操作做法包括:在主机侧维护资源 URI 白名单,只允许访问特定目录或特定类型的资源;在服务器侧对敏感路径做硬限制,并根据用户身份做权限过滤;对返回内容做脱敏处理,比如去掉个人信息或内部标识。还可以定期审计资源访问日志,排查异常访问模式,避免“慢性泄露”。
Q:一个复杂业务流程,应该拆成多个工具还是配合提示一起用?
A:复杂流程更适合“提示 + 多个小工具”的组合,而不是一个巨大的万能工具。原因是大工具难以复用、难以测试,也不利于权限细分。更好的做法是:用提示定义流程和角色,比如“你是订单处理助手,按以下步骤操作”;再把每一步的具体动作(查订单、更新状态、发送通知)做成独立工具,由模型按提示指引依次调用。这样既能保持流程的灵活性,又能对每个工具单独做权限和审计。建议在设计时先画出流程图,再按“一个节点一个工具”的粒度拆分。
如果你正准备搭一个基于 MCP 的系统,不妨把这套区分方法和问答收藏下来。等到真正要落地工具、资源和提示时,它会比问十个同事都更清晰。


