在现代PC中,虽然大多数都配备了NPU(神经网络处理单元),但其实际使用频率却非常低。NPU作为专门用于高效处理AI任务的处理器,符合微软Copilot+ PC标准的40TOPS性能时,Windows系统会自动调用其标准功能。尽管这些功能的实用性和使用频率存在争议,但理论上用户随时可以启用它们。
然而,未达到该性能标准的Intel Core Ultra系列(代号Arrow Lake)中的NPU“Intel AI Boost”几乎没有实际用途。笔记本电脑上可通过“Windows Studio Effects”功能利用NPU进行背景虚化处理,但此功能仅限特定机型,且桌面PC连接USB摄像头时无法使用。
第三方软件方面,图像编辑软件GIMP的Stable Diffusion插件、视频编辑软件CapCut的背景抠图功能,以及录音软件Audacity的OpenVINO插件均可调用NPU进行处理。但Stable Diffusion生成的图像质量较低,且大多数用户并不常用视频编辑或录音转写功能,因此很难激发用户主动准备素材来测试NPU性能。
利用常见大型语言模型(LLM)激活NPU
提到NPU,大家自然联想到AI,而更贴近生活的AI则是大型语言模型(LLM)。那么,是否有办法让LLM在NPU上运行呢?
实际上,针对AMD Ryzen AI处理器,已有第三方LLM前端软件“Lemonade Server”问世。它利用Ryzen AI软件作为后端,使LLM能在NPU上运行。但遗憾的是,Lemonade Server并不支持Intel AI Boost。
“如何让Intel AI Boost也能运行LLM?”
线索可以追溯到2025年1月,当时微软的编辑器Visual Studio Code推出了扩展“AI Toolkit”,支持NPU推理功能。但该支持仅限搭载Snapdragon X的Copilot+ PC,且仅支持DeepSeek R1机型。实际测试结果表现不佳,几乎难以使用。
之后,Intel和AMD的NPU支持并无官方进一步消息,许多人可能已将此事遗忘。
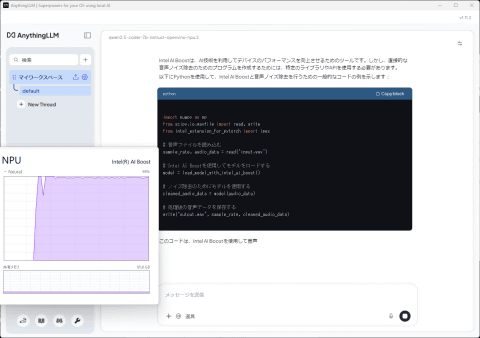
不过,最近在评测日本国家Lunar Lake架构的迷你PC“GMKtec K13”时,笔者重新安装Visual Studio Code,发现了为Intel准备的较旧Qwen2.5模型,并确认其能在NPU上正常运行。
虽然Qwen2.5相比最新的Qwen3.5有所逊色,且Visual Studio Code中最大上下文窗口限制为1536,但其日语交互能力远优于DeepSeek R1,实用性明显提升。
Arrow Lake的NPU能用吗?
笔者产生了两个疑问:
- Lunar Lake能运行,Arrow Lake是否也能?
- 启动编辑器运行LLM不够便捷,是否有专门的LLM前端可用?
网上搜索“Intel NPU LLM”多是复杂的技术教程,令人头疼。
此时,笔者想起了英伟达创始人黄仁勋的话:“如果不知道如何制作或使用AI,就问AI,它会一步步教你。”
虽然未能完全得到详细步骤,但通过Google Gemini AI获得了以下提示(Visual Studio Code和NPU LLM问题分别在不同对话中询问):
- Visual Studio Code的AI Toolkit扩展本地运行LLM时,使用的是Foundry Local(前称Azure AI Foundry),它作为独立后端运行。
- 前端方面,AnythingLLM正在支持ONNX模型(可用于NPU)。
不过,AnythingLLM的ONNX支持主要针对Snapdragon X,且ONNX运行由Foundry Local负责,因此无需同时使用AnythingLLM的前后端。
尝试安装AnythingLLM后发现,设置中可选择Foundry Local作为LLM后端,意味着可以用AnythingLLM作为易用的前端界面。
Foundry Local与模型安装
接下来只需安装Foundry Local并下载模型,然后用AnythingLLM作为前端即可。打开Windows终端,输入:
> winget install Microsoft.FoundryLocal
“winget”类似Linux的“apt”,是Windows的包管理命令。
然后查看支持NPU的模型列表,带“-openvino-npu”后缀的即为可用模型。由此确认Foundry Local运行LLM并非仅限Copilot+ PC,而是基于OpenVINO技术,这意味着Arrow Lake的NPU也有望支持。
> foundry model list
本次示例使用较大规模的“qwen2.5-coder-7b”模型,其他模型请替换名称。注意需指定模型ID,否则默认下载CPU版本。
> foundry model download qwen2.5-coder-7b-instruct-openvino-npu:2
下载完成后,回到AnythingLLM,点击“Open settings”,在AI提供者“LLM”中选择“Microsoft Foundry Local”,并选中“qwen2.5-coder-7b-instruct-openvino-npu:2”作为聊天模型。
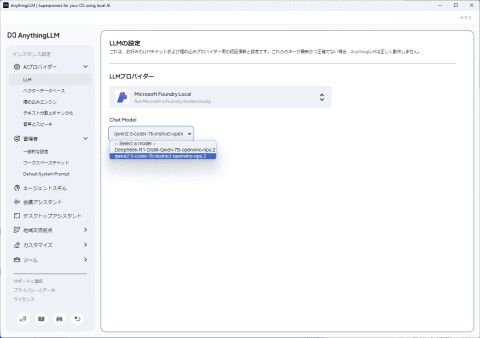
“Show advanced settings”中可设置Model Context Window大小,测试输入65536也能正常运行,但数值越大内存占用越高。
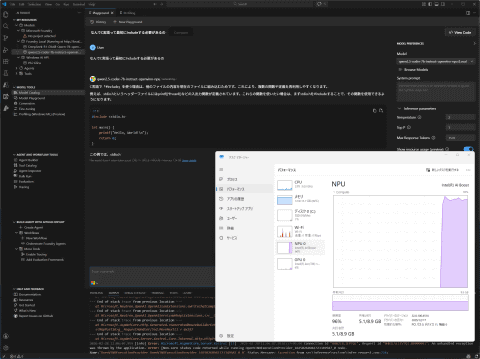
设置完成后即可开始聊天。测试确认Arrow Lake的Intel AI Boost可用,虽然模型加载需等待2-3分钟,但响应速度较快。
NPU与LLM的未来展望
Arrow Lake的NPU性能有限,输出速度约8 tokens/s,且qwen2.5模型较旧,且为NPU优化,输出内容较短,表达较为简略。
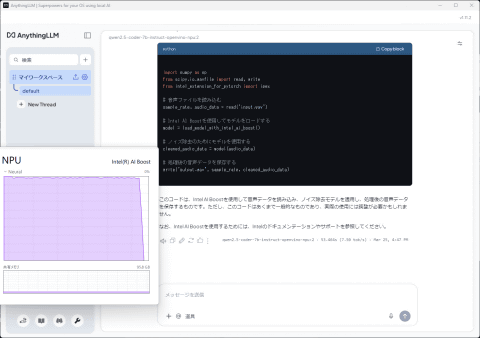
不过,NPU的低功耗优势明显。测试使用搭载Core Ultra 9 285HX的MINISFORUM“MS-02 Ultra”,CPU空闲功耗约13W,开启NPU后仅增加5-7W,风扇转速几乎无变化,系统保持安静。
虽然8 tokens/s的速度难以满足快速输出需求,但作为聊天伙伴或获取简单提示和知识的工具,低功耗的NPU运行LLM反而更实用。
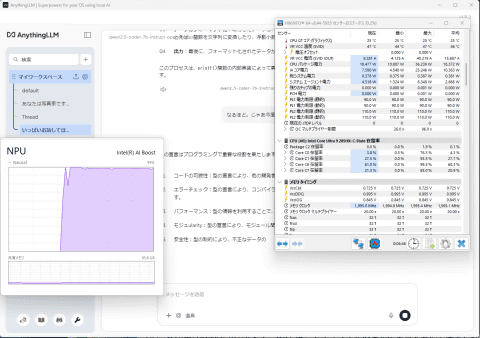
目前Foundry Local是唯一较为便捷的试用方案,且支持的模型数量有限,最新模型尚未覆盖。官方虽计划持续扩充,但希望更新速度能加快。
此外,类似“伺か”这类曾经流行的桌面虚拟角色,如果能通过小型语言模型微调,具备一定智能并能自然语言交互,或许可以在NPU上静静运行,成为低功耗的智能桌面助手。
笔者也将继续与NPU进行“对话”,期待未来更多可能。


