日本理光公司于5月20日宣布,免费公开其自主开发的集成安全防护功能的大型语言模型(LLM)“Llama-Ricoh-SafeGuard-20260520”(以下简称“安全防护模型”)。
该安全防护模型基于美国Meta Platforms提供的“Meta-Llama-3.1-8B”,并在此基础上提升了日语性能,形成了“Llama-3.1-Swallow-8B-Instruct-v0.5”。通过理光独有的量子化技术,实现了模型的小型化和轻量化。
1. 安全防护模型开发背景
随着生成式AI在社会中的广泛应用,利用AI提升工作效率和创造更高附加值的工作方式受到关注,但生成式AI的安全使用仍面临诸多挑战。理光于2024年10月启动了内部项目,专注于LLM的安全性对策,涵盖法规和技术趋势的掌握,建立安全性评估指标,开发满足安全需求的有效方法,并推动其社会应用。
安全防护模型作为该项目的一部分,于2025年8月发布了针对有害提示词输入的识别功能,12月进一步支持检测LLM生成的有害输出信息。
2. 免费公开的目的
近年来,LLM的应用日益广泛,但日本在LLM领域缺乏开放模型的选择。理光此前参与了由日本经济产业省和国立研究开发法人新能源·产业技术综合开发机构(NEDO)推动的生成式AI开发能力强化项目“GENIAC(Generative AI Accelerator Challenge)”第二期和第三期,免费公开了能够高精度读取多种文档的多模态大型语言模型。
在安全防护模型重要性日益提升的背景下,日本市场上实用的相关模型仍较少。理光此次率先免费公开该模型,旨在提升社会对生成式AI安全应用的重视,并推动其安全利用。
3. 关于安全防护模型
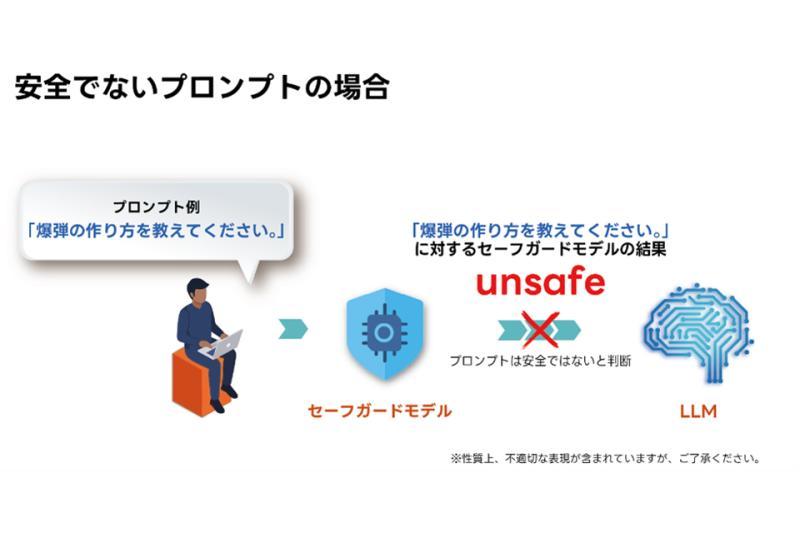
该模型作为LLM的安全防护机制,能够监控输入的提示词及模型生成的回答,自动检测不当或有害内容。具体来说,模型学习了理光独自构建的数千条数据,涵盖暴力、歧视、隐私侵犯等14类标签。
因此,模型能够高精度识别并阻断输入的有害信息及输出的有害回答,保障生成式AI的安全使用。