日本LifePrompt公司于今年2月,使用最新生成式AI模型“ChatGPT 5.2 Thinking”、“Gemini 3 Pro Preview”及“Claude 4.5 Opus”对日本东京大学和京都大学的二次考试试题进行了答题测试。
由日本河合塾讲师和KIES评分,结果显示ChatGPT 5.2 Thinking和Gemini 3 Pro Preview在东京大学所有科类及京都大学几乎所有学部和学科中,均超过了合格者的最高分(相当于首席成绩)。其中数学科目表现尤为突出,多门科目获得满分。
主要测试结果
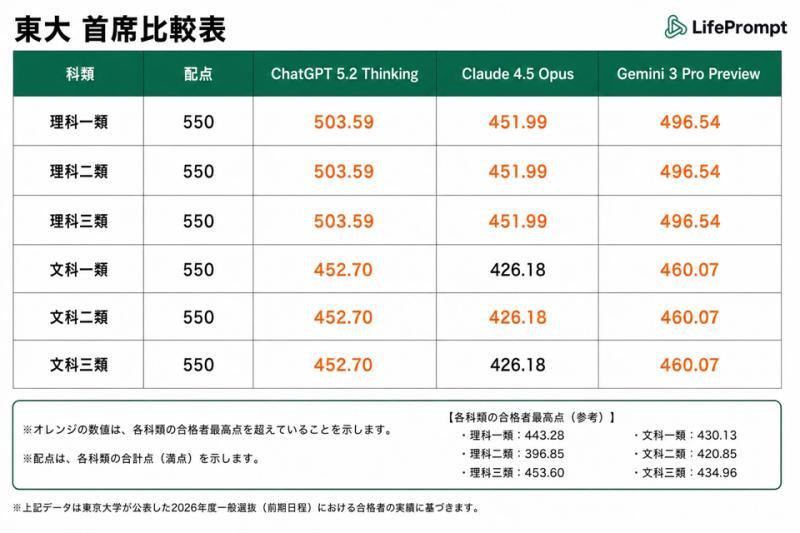
日本东京大学(最难科类:理科三类,满分550分)
- ChatGPT 5.2 Thinking:503.59分
- Gemini 3 Pro Preview:496.54分
- Claude 4.5 Opus:451.99分
- 参考:2026年度理科三类合格者最高分453.60分
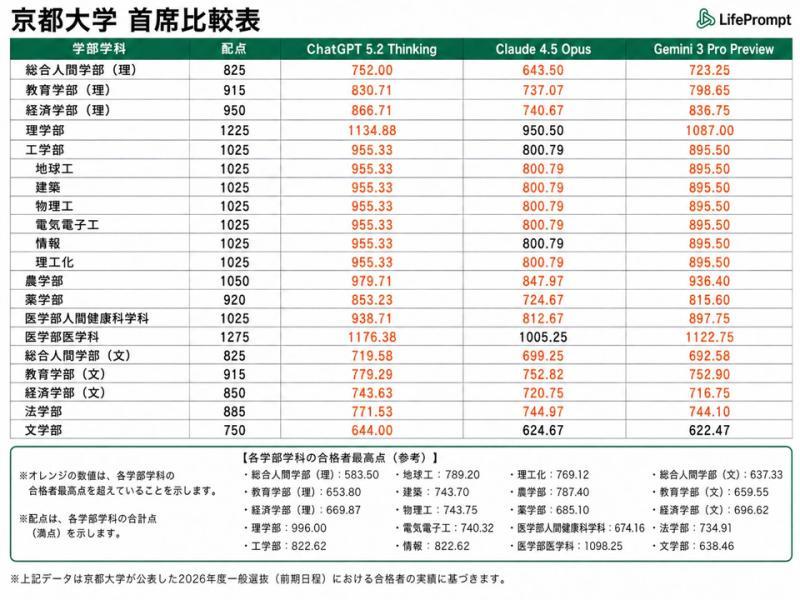
日本京都大学(最难科类:医学部医学科,满分1275分)
- ChatGPT 5.2 Thinking:1176.38分
- Gemini 3 Pro Preview:1122.75分
- Claude 4.5 Opus:1005.25分
- 参考:2026年度医学部医学科合格者最高分1098.25分
满分科目
- 东京大学理科数学(120分):ChatGPT、Gemini
- 东京大学文科数学(80分):ChatGPT、Gemini
- 京都大学理科数学(200分):ChatGPT、Gemini
- 京都大学文科数学(150分):ChatGPT
- 京都大学化学(100分):ChatGPT
去年同类测试中,最新AI模型在东京大学理科数学仅得38分,短短一年时间内达到满分,充分体现了生成式AI推理能力的高速进化。
测试方法
为了保证测试的公平性,LifePrompt使用了自主开发的自动考试系统:
- 将考试试题PDF按页转换为图片,通过API发送给各AI模型
- 避免通过聊天界面,系统间直接交互,排除人为干预
- 所有科目使用统一提示语,仅依赖高中教养课程知识回答,数学公式以LaTeX格式输出
- 不使用网络搜索,完全依赖AI已学习知识和推理能力作答
- 记述题由日本河合塾讲师按照人类考生标准评分
日本河合塾讲师点评(节选)
负责评分的讲师指出,AI表现远超预期,尤其是ChatGPT的答题能力令人震惊(东京大学生物科目评分讲师向井亮先生)。
各AI均达到合格水平,尤其在处理速度上远超人类(京都大学日本史评分讲师小仓匡先生)。
但也暴露出明显弱点:
- 图像识别存在问题,尤其是结构式、图表和地图(Claude表现较弱)
- 论述结构能力不足,逻辑关系和因果关系表达较弱
- 输出控制不佳,无法严格遵守字数限制和答题框物理限制
- 依赖英语物理习惯,导致日本式设定时出现错误
LifePrompt代表远藤聪志评论
“AI取得东京大学历史最高分令人感动。此次测试表明,AI能满分的任务和不能满分的任务界限明显。实际工作中,如何将业务转化为AI能解决的形式决定成效。基础模型的智能已充分展现,接下来是各公司独特竞争。如何结合自有数据和业务,创造商业价值,成为关键。数学成绩从38分到满分仅用一年,说明按当前AI极限设计系统并非明智。应着眼未来10年、20年,设计适应未来AI的业务和组织。”