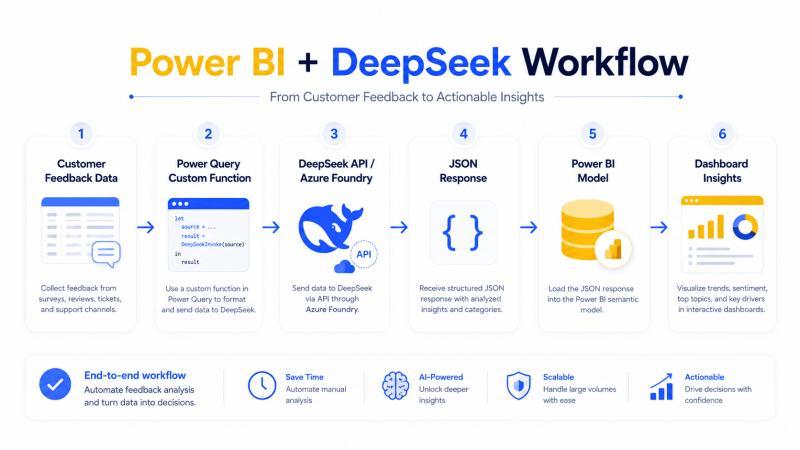
99% 的团队都以为「等有官方连接器再说」,结果白白错过了把 DeepSeek 接进 Power BI 的窗口期。其实,只要会写一点 Power Query M,用 API 的方式就能把 DeepSeek 变成你的文本分析引擎,把杂乱的评论、工单、问卷,直接变成报表里的字段。
这篇指南会带你一步步搭好 Power BI + DeepSeek 的工作流:从 Power Query 调用 DeepSeek API、把分类结果写回列,到控制刷新成本、规避隐私风险。我也会穿插一些真实踩坑经验和数据,让你少走弯路。
据一位零售客户反馈,他们用类似方案清洗了约 3 万条评论,人工标注时间从两周缩短到两天,但如果不控制刷新策略,API 账单会吓人。
什么是 Power BI DeepSeek 集成?
用大模型给 Power BI「长一双眼睛」
Power BI DeepSeek 集成,说白了就是:在 Power BI 的数据准备或建模阶段,把 DeepSeek 的大语言模型当成一个外部服务来调用。你把文本丢给它,它把结构化结果丢回来,Power BI 再把这些结果当普通字段用在表格、图表和度量值里。
典型流程大致是这样:
- 从 Power Query 把客户评论、工单描述、问卷开放题、商品评价等文本发给 DeepSeek。
- DeepSeek 返回情感标签、问题类型、摘要、解释,或者一个 JSON 对象。
- Power BI 把这些返回值加载进语义模型,变成
Sentiment、IssueType、Summary、RecommendedAction等字段。
当你的数据里有大量「非结构化文本」时,这种组合特别有用。Power BI 擅长建模和可视化,DeepSeek 擅长理解自然语言,两者配合,就能把原本只能人工阅读的内容,变成可筛选、可聚合的指标。
为什么从 Power Query 开始最现实?
很多人会等「原生 DeepSeek 连接器」,但真正落地最快的地方,其实是 Power Query。原因很简单:
- Power Query 自带
Web.Contents,可以发 HTTP 请求。 - 用
Json.FromValue构造 JSON 请求体,用Json.Document解析 JSON 响应。 - 自定义函数可以复用到整列数据上,适合做批量分类或摘要。
微软文档里明确示例了如何用 Web.Contents 做 POST 请求并解析 JSON,你只需要把 URL 换成 DeepSeek 的 /chat/completions,再按 DeepSeek 的 API 规范组织请求体就行。
有用户在内部试点时,只用一个自定义函数,就把 NPS 调研中的开放题全部自动打了标签,后面分析满意度驱动因素轻松很多。
DeepSeek 能不能接入 Power BI?
直接用 DeepSeek API 调 Power Query
答案是可以,而且现在就能做。你不需要等官方 DeepSeek 连接器,只要会用 Power Query 的 Web.Contents。
最直接的方式是:
- 在 Power Query 里用
Web.Contents调用 DeepSeek 的 Chat Completions 接口。 - 用
Json.FromValue生成请求体,包含model、messages、response_format等字段。 - 用
Json.Document解析响应,从choices[0].message.content里取出模型输出。
DeepSeek 当前文档显示,推荐使用 deepseek-v4-flash 和 deepseek-v4-pro 这两个模型,老的 deepseek-chat 和 deepseek-reasoner 会在 2026 年 7 月 24 日弃用。接口路径是 /chat/completions,接受消息列表,返回带 usage 信息的 completion 对象。
通过 Azure AI Foundry 做企业级接入
如果你所在的是大企业,安全和治理要求比较高,可以考虑走 Microsoft Foundry Models 的路线。Foundry 可以:
- 用统一的 Azure 端点和凭据管理多个模型。
- 通过 Entra ID 做无密钥认证,减少 API Key 暴露风险。
- 在企业合规框架下审查数据流和模型部署。
微软的 DeepSeek 教程已经给出如何在 Foundry 中部署 DeepSeek 推理模型(比如 DeepSeek-R1、DeepSeek-R1-0528),并通过 Azure 风格的 /openai/deployments/{deployment-name}/chat/completions 端点调用。这里要注意:Foundry 的部署名和 DeepSeek 直连 API 的 model 字段不是一回事,参数支持也可能不同。
我也不太确定未来微软会不会出一个完全托管的 DeepSeek 连接器,但从现在的产品节奏看,API + Foundry 这条路短期内更稳。
DeepSeek + Power BI 的高价值场景
哪些任务最适合用 DeepSeek 来「结构化」?
Power BI DeepSeek 集成最值钱的地方,在于把文本变成可分析的数据。常见场景包括:
- 情感分析:把评论或问卷开放题转成「正向 / 中性 / 负向」。
- 客户反馈分类:打上「投诉、退款、咨询、技术支持、建议、表扬」等标签。
- 工单自动打标签:在进入 SLA、积压、升级分析前,先统一分类。
- 解释 KPI 变化原因:给模型一个上下文窗口,让它用自然语言总结指标波动的可能原因。
- 长文本摘要:把几百字的客户反馈压缩成管理层能快速扫一眼的摘要。
- DAX 助手:让 DeepSeek 帮你起草 DAX,再在 Desktop 里严格验证。
- Power Query M 灵感:让模型给出转换思路,再自己改写和测试。
- 自然语言解读数据:为异常值、趋势或细分群体生成「人话」说明。
关键点只有一个:输出必须可验证。分类、打标签、摘要这类任务,人工抽样检查就能发现问题,比起让模型直接做业务决策要安全得多。
先做小 PoC,再考虑生产级管道
很多团队一上来就想「全量跑」,结果在 Power BI Service 刷新时被 API 成本和限流打回原形。更稳的节奏是:
- 先在 Power Query 里做一个小 PoC,只跑几十到几百行。
- 验证分类准确率、响应时间和成本大致水平。
- 再设计生产级的 AI 富化管道(数据流、数据库、湖仓等),把结果缓存下来。
有用户在 5 万行评论上直接用 Power Query 调 API,配合每天 8 次刷新,结果一天打了 40 万次请求,成本和刷新时间都爆了,这就是典型的「没先算账」。
前置条件与环境准备
搭建前你需要准备什么?
在动手前,先确认这些条件:
- 已安装 Power BI Desktop。
- 能打开 Power Query 编辑器。
- 有 DeepSeek API Key,或已配置好的 Microsoft Foundry 端点与凭据。
- 了解一点 Power Query M 语法。
- 有一份小规模测试数据集(几十行就够)。
- 明确的数据治理方案,知道哪些数据可以发到外部模型。
- 对 API 成本、刷新频率、错误处理有基本规划。
DeepSeek 当前 Quick Start 文档给出的基础 URL 是 https://api.deepseek.com,模型表中列出了 deepseek-v4-flash 和 deepseek-v4-pro。在 Power Query 里,你会主要用到:
Web.Contents:发 HTTP 请求。Json.FromValue:把 M 值转成 JSON 请求体。Json.Document:解析 JSON 响应。
数据显示,很多失败案例都不是技术问题,而是「没想清楚能不能把这些数据发到外部」,所以治理和合规要先过一遍。
用 Power Query 从 Power BI 调用 DeepSeek API
步骤 1:打开 Power BI Desktop
先打开 Power BI Desktop,新建一个报表或打开现有 PBIX。为了控制成本和调试难度,建议先用一张只有少量文本行的小表测试,不要一上来就几万行,因为每一行理论上都可能触发一次 API 调用。
步骤 2:加载示例数据
准备一张类似这样的表:
- 表名:
CustomerComments - 列:
CustomerFeedback(客户反馈文本)
可以从 Excel、CSV、数据库导入,或者直接在 Power BI 里手工输入几条测试数据。
步骤 3:打开 Power Query 编辑器
在 Power BI Desktop 顶部菜单选择 转换数据(Transform data),进入 Power Query 编辑器。后续所有 API 调用逻辑都在这里完成。
步骤 4:创建空白查询并命名函数
在查询窗格中右键,选择 新建查询 → 空白查询。微软文档说明,自定义函数可以从空白查询开始,在高级编辑器里直接写 M 代码。
把这个查询重命名为:
fnDeepSeekClassifyFeedback
这样后面在「调用自定义函数」时就能直接选到它。
步骤 5:编写 Power Query 自定义函数
打开 高级编辑器(Advanced Editor),粘贴下面的示例代码,并按需调整:
// Power Query M 自定义函数
// 函数名:fnDeepSeekClassifyFeedback
// 作用:把一条客户反馈文本发给 DeepSeek,返回一个分类结果。
// 安全提示:不要在公开 PBIX 中硬编码真实 API Key。
// 仅在本地测试时替换 YOUR_DEEPSEEK_API_KEY,生产环境请用更安全的参数/凭据方案。
let
fnDeepSeekClassifyFeedback =
(feedbackText as nullable text, optional apiKey as nullable text) as nullable text =>
let
// 演示用占位 API Key
DeepSeekApiKey =
if apiKey null
then apiKey
else "YOUR_DEEPSEEK_API_KEY",
SafeFeedback =
if feedbackText = null
then ""
else Text.From(feedbackText),
Endpoint =
"https://api.deepseek.com/chat/completions",
SystemPrompt =
"You are a careful data classification assistant for a Power BI report. " &
"Classify customer feedback into exactly one of these categories: " &
"Complaint, Refund, Inquiry, Technical Support, Suggestion, Praise. " &
"Return only valid JSON in this exact format: {""category"":""Complaint""}.",
UserPrompt =
"Classify this customer feedback as JSON: " & SafeFeedback,
RequestBody =
[
model = "deepseek-v4-flash",
thinking = [type = "disabled"],
messages =
{
[role = "system", content = SystemPrompt],
[role = "user", content = UserPrompt]
},
response_format = [type = "json_object"],
temperature = 0.2,
max_tokens = 80
],
RawResponse =
try
Web.Contents(
Endpoint,
[
Headers =
[
#"Content-Type" = "application/json",
#"Authorization" = "Bearer " & DeepSeekApiKey
],
Content = Json.FromValue(RequestBody),
ManualStatusHandling = {400, 402, 404, 422, 429, 500, 503},
Timeout = #duration(0, 0, 2, 0)
]
)
otherwise
null,
StatusCode =
if RawResponse null
then try Value.Metadata(RawResponse)[Response.Status] otherwise 200
else null,
ParsedResponse =
if RawResponse null
then try Json.Document(RawResponse) otherwise null
else null,
AssistantContent =
if StatusCode null and StatusCode >= 400 then
"ERROR " & Number.ToText(StatusCode) & ": check API key, endpoint, quota, rate limit, or request body."
else
try ParsedResponse[choices]{0}[message][content] otherwise null,
ParsedAssistantJson =
if AssistantContent null and not Text.StartsWith(AssistantContent, "ERROR")
then try Json.Document(AssistantContent) otherwise null
else null,
Category =
if ParsedAssistantJson null
then try ParsedAssistantJson[category] otherwise AssistantContent
else AssistantContent
in
Category
in
fnDeepSeekClassifyFeedback
提醒一句:标准 Power Query 对 401、403 这类认证错误,可能会触发凭据对话框,而不是把状态码直接返回给函数。生产环境要么用自定义连接器,要么用中间层服务或 Foundry 端点来做更完整的认证和错误处理。
步骤 6:理解 API 调用逻辑
这个函数会向 DeepSeek 的 Chat Completions 端点发一个 POST 请求。当前 DeepSeek 文档要求 model 字段必填,并列出了 deepseek-v4-flash 和 deepseek-v4-pro 两个可选值,同时说明可以通过 thinking 对象控制推理模式开关。
对于简单分类任务,deepseek-v4-flash 且关闭 thinking 模式通常就够用,响应快、成本低。如果你要做复杂分析或多步推理,可以再测试 deepseek-v4-pro,但要注意 token 消耗会明显增加。
步骤 7:解析响应并抽取分类结果
代码里先从响应中取出:
choices[0].message.content
因为我们在提示词里要求模型返回 JSON,所以还要再用一次 Json.Document 把这段文本解析成结构化对象,例如:
{"category":"Complaint"}
DeepSeek 的 JSON 输出文档建议:
- 把
response_format设为{ "type": "json_object" }。 - 在提示词中明确提到「json」,并给出示例格式。
- 合理设置
max_tokens,避免输出被截断。
步骤 8:把分类结果写回表格列
回到你的客户反馈表 CustomerComments。在 Power Query 中:
- 选择 添加列 → 调用自定义函数。
- 选择函数:
fnDeepSeekClassifyFeedback。 - 把
feedbackText参数映射到CustomerFeedback列。 - 如果函数有
apiKey参数,建议传入 Power Query 参数,而不是在函数调用里硬编码。
函数执行后,Power Query 会新增一列,类似:
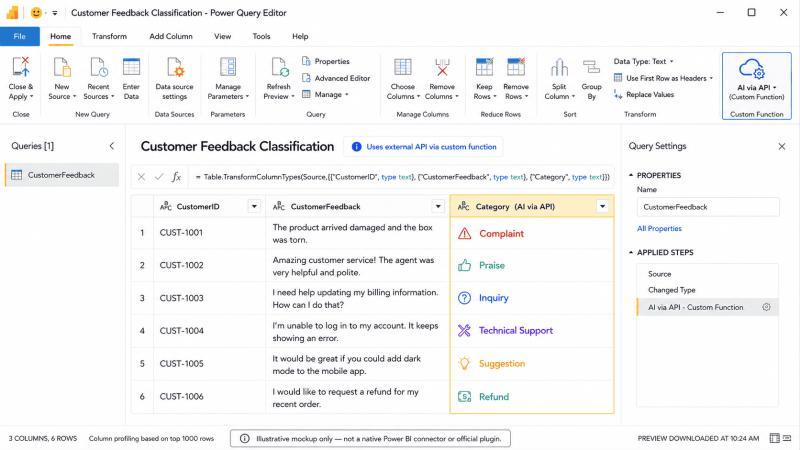
点击 关闭并应用(Close & Apply),这些分类结果就会加载进 Power BI 模型,可以直接用于图表和度量值。
在 Azure AI Foundry 中调用 DeepSeek 并接入 Power BI
为什么企业更偏向 Foundry 方案?
对很多大型组织来说,直接把 API Key 塞进 PBIX 并不是一个可接受的方案。Azure AI Foundry 提供了更「企业味」的路径:
- 统一的端点管理和访问控制。
- 基于 Azure 角色的权限治理。
- 通过 Entra ID 实现无密钥认证。
- 集中审查模型部署、数据流向和合规性。
- 配合内容过滤和负责任 AI 控制。
微软文档中给出的 Azure 风格 Chat Completions 路径类似:
https://.services.ai.azure.com/openai/deployments//chat/completions?api-version=2024-10-21
这里 `` 是你在 Foundry 资源里创建的模型部署名,而不是 DeepSeek 文档里的 model 字符串,两者不要混用。
Azure 风格端点的 Power Query 示例
下面是一个适配 Azure 端点的 Power Query 函数模板,你需要把资源名、部署名、API 版本和 Key 换成自己的配置:
let
fnAzureDeepSeekClassifyFeedback =
(feedbackText as nullable text, azureApiKey as text) as nullable text =>
let
ResourceBaseUrl = "https://YOUR_RESOURCE.services.ai.azure.com",
DeploymentName = "YOUR_DEEPSEEK_DEPLOYMENT_NAME",
SafeFeedback =
if feedbackText = null
then ""
else Text.From(feedbackText),
RequestBody =
[
messages =
{
[
role = "system",
content =
"You classify customer feedback for a Power BI report. " &
"Return only valid JSON like {""category"":""Complaint""}."
],
[
role = "user",
content =
"Choose one category: Complaint, Refund, Inquiry, Technical Support, Suggestion, Praise. " &
"Feedback: " & SafeFeedback
]
},
temperature = 0.2,
max_tokens = 80
],
RawResponse =
try
Web.Contents(
ResourceBaseUrl,
[
RelativePath =
"openai/deployments/" & DeploymentName & "/chat/completions",
Query =
[#"api-version" = "2024-10-21"],
Headers =
[
#"Content-Type" = "application/json",
#"api-key" = azureApiKey
],
Content = Json.FromValue(RequestBody),
ManualStatusHandling = {400, 401, 403, 404, 429, 500, 503}
]
)
otherwise
null,
ParsedResponse =
if RawResponse null
then try Json.Document(RawResponse) otherwise null
else null,
AssistantContent =
try ParsedResponse[choices]{0}[message][content] otherwise null,
ParsedAssistantJson =
if AssistantContent null
then try Json.Document(AssistantContent) otherwise null
else null,
Category =
if ParsedAssistantJson null
then try ParsedAssistantJson[category] otherwise AssistantContent
else AssistantContent
in
Category
in
fnAzureDeepSeekClassifyFeedback
主要差异在于:
- 认证方式从
Authorization: Bearer换成api-key头。 - URL 结构改为 Azure 的
openai/deployments/{deployment-name}/chat/completions。
示例:在 Power BI 中用 DeepSeek 分类客户反馈
设计一个可复用的分类方案
假设你有一张表 CustomerComments,包含列:
CustomerFeedback:客户反馈文本
你希望新增一列:
Category:分类结果
允许的分类值为:
- Complaint
- Refund
- Inquiry
- Technical Support
- Suggestion
- Praise
可以用一个严格的英文提示词(方便模型理解):
You are a careful data classification assistant for a Power BI report.
Classify customer feedback into exactly one of these categories:
Complaint, Refund, Inquiry, Technical Support, Suggestion, Praise.
Return only valid JSON in this exact format:
{"category":"Complaint"}
Do not add commentary.
Do not invent new categories.
在 Power Query 中,对 CustomerFeedback 列调用 fnDeepSeekClassifyFeedback 函数,例如:
= Table.AddColumn(
PreviousStep,
"Category",
each fnDeepSeekClassifyFeedback([CustomerFeedback], pDeepSeekApiKey),
type text
)
点击 关闭并应用 后,新的 Category 列就进入了 Power BI 模型,你可以用它做:
- 各类别按月份的趋势图。
- 不同产品的投诉数量对比。
- 各区域技术支持问题占比。
- 各客户分群的表扬比例。
- 各销售渠道的退款相关评论数量。
为了提高报表质量,建议建立一个人工复核机制,比如每周抽样检查一部分 AI 分类结果,把修正后的标签存入参考表,用来监控模型表现。
用 DeepSeek 辅助编写和优化 DAX
把 DeepSeek 当「高级 DAX 搭档」,但别盲信
DeepSeek 也可以帮你写 DAX、解释 DAX、调试 DAX,尤其是对新手或业务分析师很友好。不过有一点必须强调:AI 生成的 DAX 一定要在 Power BI Desktop 里严谨测试。
原因很现实:
- 模型可能误解表关系和筛选上下文。
- 业务定义有细微差别,AI 不一定完全理解。
- 性能优化需要结合实际数据量和模型结构。
微软自己的 Copilot 文档也是类似态度:Copilot 可以生成 DAX,但是否采用,要由用户在 Desktop 里跑过、对过结果再决定。
常用 DAX 提示词模板
模板 1:生成 DAX 度量
You are a senior Power BI developer.
Create a DAX measure for this requirement:
Requirement:
[Describe the business calculation]
Model tables:
[Paste table names, column names, relationships, and existing measures]
Rules:
- Return only the DAX measure.
- Explain assumptions after the code.
- Mention any required relationships or filter context dependencies.
模板 2:调试错误的 DAX
You are a DAX debugging expert.
This measure returns incorrect results:
[Paste measure]
Expected result:
[Describe expected result]
Actual result:
[Describe actual result]
Model context:
[Paste relevant tables, relationships, and filters]
Find the likely issue and provide a corrected version.
模板 3:优化慢的 DAX
You are a Power BI performance optimization expert.
Optimize this DAX measure for readability and performance:
[Paste measure]
Model context:
[Paste relevant table sizes, relationships, and columns]
Constraints:
- Keep the same business logic.
- Avoid unnecessary row context.
- Explain why the revised version should perform better.
模板 4:用「人话」解释一个度量
Explain this DAX measure in plain English for a business analyst:
[Paste measure]
Include:
- What it calculates
- How filters affect it
- Possible edge cases
- One simple example
模板 5:生成一组 KPI 度量
Create DAX measures for a KPI card:
KPI:
[Example: Monthly recurring revenue growth]
Fields:
[Paste columns and tables]
Need:
- Current value
- Prior period value
- Percentage change
- Status label: Good, Warning, Bad
- Short explanation of each measure
说实话,DeepSeek 在给出思路和初稿方面很省时间,但真正决定能不能上生产的,还是你的语义模型质量、命名规范、测试用例和对业务的理解。
Power BI Service 刷新与 DeepSeek 成本陷阱
为什么很多集成死在「刷新」这一步?
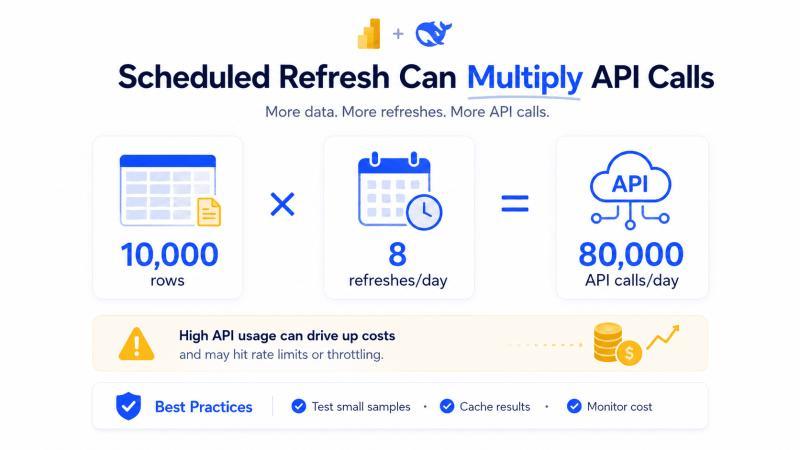
很多 Power BI + DeepSeek 项目,开发阶段一切顺利,一上 Power BI Service 就开始报错、超时、成本飙升。根源在于:刷新会重复触发 API 调用。
微软文档说明,导入模式的语义模型在刷新时会重新从数据源拉取数据。如果你的 Power Query 步骤里包含对 DeepSeek 的调用,那么每次刷新都可能对每一行重新发请求。
这会带来:
- API 成本被放大。
- 刷新时间变长,甚至超时失败。
- 触发 DeepSeek 的限流或配额限制。
- 如果提示词不够稳定,标签结果前后不一致。
- 凭据过期或网关配置错误时,刷新直接失败。
微软的计划刷新文档提到:
- Pro 用户每天最多 8 次计划刷新。
- Premium / Fabric 容量下最多可到 48 次。
配合行数一算,就知道风险有多大:
10,000 行 × 8 次刷新 = 80,000 次 API 调用/天
控制刷新成本的实用做法
在发布前,建议这样做:
- 只用 10–50 行做初次测试。
- 提示词写得稳定、明确,减少随机性。
- 把
max_tokens设得尽量小。 - 尽量缓存输出,不要每次刷新都重算。
- 把 AI 结果落地到数据库、数据流或湖仓,再由 Power BI 读取。
- 在 Power BI Service 中正确配置数据源凭据和网关。
- 发布后定期查看刷新历史,关注失败和耗时。
- 对已经分类过的行加标记,避免重复调用。
微软也提醒,Desktop 和 Service 在获取架构信息或数据时,可能会发多次查询,这在你把 API 调用嵌进 Power Query 时同样会放大调用次数。
安全与隐私:别让 AI 成为数据泄露入口
六条必须重视的安全实践
AI 富化很香,但如果处理不好,极容易变成数据泄露通道。建议遵循这些做法:
-
绝不暴露 API Key
不要在截图、博客、GitHub、共享 PBIX 模板里出现真实 Key。 -
未经批准不要发敏感 PII
客户姓名、邮箱、电话、支付信息、健康数据、员工信息、内部事故细节等,都可能需要法务、安全或合规团队审批。 -
优先用参数和凭据管理
Power Query 参数比硬编码安全一些,但还不算企业级方案。生产环境更适合用自定义连接器、中间层 API、Azure 端点或组织级密钥管理。 -
理解 Power Query 隐私级别
微软文档说明,隐私级别可以防止在合并不同源数据时,把私有数据意外发送到不可信源,这在你调用外部 API 时尤其重要。 -
企业场景优先考虑 Foundry
Foundry 部署可以集中管理端点、认证和治理,配合服务器无服务器部署模式,在安全和合规框架内以 API 形式消费模型。 -
保留审计线索
记录模型名称、提示词版本、分类日期、人工复核状态等,尤其当 AI 标签被用于运营报表或决策时,这一点非常关键。
有团队在内部审计时被问到「这条标签是谁打的、基于哪个模型版本」,如果没有日志,很难自证清白。
成本与性能优化:别让 Token 吃掉预算
控制 Token 消耗的几个关键杠杆
DeepSeek 的计费与 Token 使用挂钩,官方文档说明,Token 是模型计费的基本单位。要控制成本和性能,可以从这些方面下手:
- 先用小样本测试,估算单行平均 Token 消耗。
- 提示词尽量短,但要清晰、明确。
- 用
max_tokens限制输出长度。 - 只要一个字段就够时,就别让模型写一大段解释。
- 分类任务用低温度(如 0–0.2),减少随机性和重试。
- 简单标签任务关闭 thinking 模式。
- 简单任务优先用便宜、快速的模型,高级推理模型留给复杂场景。
- 把结果缓存到表里,避免重复调用。
- 源文本没变就不要重新发请求。
- 监控 API 响应中的 usage 字段,了解真实消耗。
DeepSeek 的响应里会包含 prompt_tokens、completion_tokens、cache_hit_tokens、cache_miss_tokens、total_tokens 等字段。官方也介绍了上下文缓存(KV Cache),可以在相似上下文下减少重复计算。不过在 Power BI 场景里,不要指望缓存帮你解决刷新成本问题,应用层面的缓存和管道设计才是更可靠的控制手段。
DeepSeek、Copilot、ChatGPT:Power BI 场景怎么选?
三者各自适合什么位置?
在 Power BI 相关工作里,这三者的定位大致可以这样理解:
- Copilot:最原生的微软体验,适合在 Power BI 内部做自然语言提问、自动生成可视化、辅助写 DAX 等,前提是你有对应的许可证。
- DeepSeek:更适合做「把文本变成字段」的自定义 API 工作流,比如评论分类、摘要、原因解释等,直接嵌入到数据准备或外部管道里。
- ChatGPT:更偏通用助手,用来做分析思路、文档撰写、DAX 代码审查、开发支持等也很顺手。
很多团队的最佳实践是「组合拳」:
- 用 DeepSeek 做结构化文本处理。
- 用 Copilot 做交互式分析和报表内智能体验。
- 用 ChatGPT 做学习、文档和开发辅助。
什么时候该把 DeepSeek 放进 Power BI,什么时候该放到外部管道?
适合直接在 Power BI 里调用 DeepSeek 的情况
可以考虑在 Power Query 里直接调 DeepSeek API 的场景包括:
- 只对导入模式数据做富化。
- 在数据准备阶段做文本分类或摘要。
- 正在做概念验证或小范围试点。
- 数据量不大,行数在可控范围内。
- API Key 管理有基本安全措施。
- 业务方认可当前的数据治理方案。
不适合直接在 Power Query 里调 API 的情况
下面这些情况,更建议你把 AI 富化放到外部管道:
- 行数达到几十万甚至上百万。
- 数据中包含敏感 PII 或受严格监管的数据。
- 需要非常严格的可审计性和可追溯性。
- 刷新成本必须高度可预测。
- 报表刷新时间有严格 SLA 要求。
- 模型输出必须经过人工审核才能对外展示。
更稳妥的生产架构通常长这样:
源数据
→ 治理良好的 AI 富化管道
→ 把 AI 输出缓存到数据库/湖仓/数据流
→ Power BI 语义模型
→ 报表可视化
这种设计可以避免每次刷新都打 AI 接口,同时在成本、质量和治理上都更可控。
结尾:把这套方法用熟,比问十个同事都管用
如果你正在犹豫要不要在 Power BI 里上 AI,其实可以先从一张小表、一个自定义函数开始,把 DeepSeek 当成「文本转字段」的工具,用最小成本验证价值。等你跑通分类、摘要、解释这几个基础场景,再决定要不要升级到 Foundry 或外部管道。
这套判断思路和实践步骤,在不同团队里已经被反复验证有效。哪怕你暂时不打算立刻落地,也值得收藏起来,当你下次需要给老板解释「AI 在 BI 里到底能干嘛、怎么干才安全」时,会比临时抱佛脚靠谱得多。
常见问题
Q:Power BI 具体怎么连到 DeepSeek?
A:可以通过 Power Query 的 Web.Contents 函数调用 DeepSeek 的 Chat Completions 接口,再用 Json.Document 解析返回的 JSON。核心步骤是:在 Power Query 里写一个自定义函数,指定 DeepSeek 的 API URL、请求头(包括 Authorization Bearer Token)、请求体(包含 model、messages、response_format 等),然后把这个函数应用到包含文本的列上。建议先用少量数据测试,确认响应结构和字段路径无误,再逐步扩大范围,并在 Power BI Service 中配置好数据源凭据和刷新策略。
Q:DeepSeek 现在有原生 Power BI 连接器吗?
A:目前不要预期有官方的 DeepSeek 连接器,主流做法还是通过 Web/API 方式接入。微软的 Power BI 数据源文档会列出所有原生连接器,如果里面没有 DeepSeek,就说明需要用 Web.Contents、Azure AI Foundry 或外部自动化管道来实现集成。实操上,很多团队会在数据工厂、数据流或自建服务里先调用 DeepSeek,把结果写入数据库或湖仓,再由 Power BI 读取,这样在治理和成本控制上更稳。
Q:能不能用 DeepSeek 来写 DAX?
A:可以,把 DeepSeek 当成高级 DAX 助手是个不错的用法,但每一条 AI 生成的 DAX 都必须在 Power BI Desktop 里验证。原因在于,模型可能误解表关系、筛选上下文或业务口径,导致结果看起来「差不多」,但细节上偏差很大。建议的做法是:先让 DeepSeek 给出初稿,再根据你的模型结构和业务规则手工调整,最后通过对比已知样例、边界情况和性能表现来决定是否采用。
Q:DeepSeek 能直接「看懂」我的 Power BI 报表吗?
A:DeepSeek不会自动理解你的整个 Power BI 语义模型,它只能分析你显式发给它的数据和元数据。在 Power BI 场景下,通常是从 Power Query 或外部管道中选取部分字段、样本数据和模型说明发给 DeepSeek,让它做分类、摘要或解释。如果你希望它理解度量逻辑或模型结构,需要在提示词中清楚地粘贴表结构、关系和关键度量,否则它只能基于有限上下文做推断。
Q:把 Power BI 数据发给 DeepSeek 安全吗?
A:安全与否取决于数据内容和你所在组织的治理规则。一般不建议在未经批准的情况下发送包含敏感 PII、财务机密或受监管行业数据的内容到外部模型。实务上,你需要:审阅 DeepSeek 的 API 条款和数据处理政策,结合 Power Query 隐私级别设置,评估是否更适合使用 Azure AI Foundry 这类托管端点,并与法务、安全、合规团队确认哪些数据可以外发、需要怎样的脱敏或聚合处理。
Q:为什么报表发布到 Power BI Service 后刷新会失败?
A:常见原因包括:数据源凭据未配置或过期、网关未正确设置、隐私级别冲突、DeepSeek API 限流或配额不足、端点地址或 Key 配置错误等。排查时可以先看刷新历史中的错误信息,再检查网关状态和数据源凭据。如果错误指向外部 API,建议在 Power Query 中增加错误处理逻辑,并在 DeepSeek 控制台查看调用日志和限流情况,必要时降低刷新频率或减少每次调用的行数。
Q:在 Power BI 里用 DeepSeek,怎么把 API 成本压下来?
A:可以从三个方向入手:行数、Token 和刷新频率。行数上,先用小样本验证,再考虑是否需要全量处理,能在外部管道预处理的尽量不要在 Power BI 里做。Token 上,缩短提示词、限制 max_tokens、只返回必要字段、关闭不需要的推理模式。刷新上,避免对未变化的行重复调用,减少计划刷新次数,或改为在数据流/数据库中缓存 AI 结果。配合监控 API 响应中的 usage 字段,你可以比较精确地估算和控制成本。


