法国人工智能公司Mistral于周四发布了一款全新的开源文本转语音(TTS)模型,适用于语音助手及企业场景,如客户支持等。该模型帮助企业构建销售和客户互动的语音代理,直接与ElevenLabs、Deepgram和OpenAI等公司竞争。
这款名为Voxtral TTS的新模型支持九种语言,包括英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语和阿拉伯语。
Mistral AI科学运营副总裁Pierre Stock在接受TechCrunch电话采访时表示:“我们的客户一直在寻求语音模型,因此我们开发了一个小型语音模型,能够运行在智能手表、智能手机、笔记本电脑及其他边缘设备上。它的成本远低于市场上的其他产品,但性能却达到了最先进水平。”
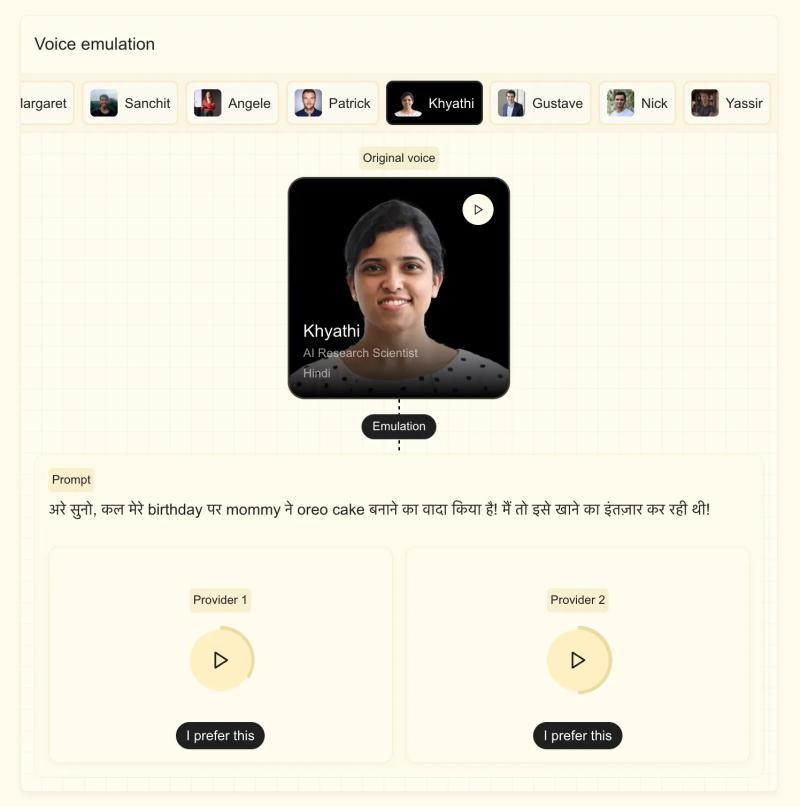
Mistral表示,该模型能够通过不到五秒的语音样本适配自定义声音,捕捉细微的口音、语调、抑扬顿挫及语流中的不规则性。基于Ministral 3B架构,模型可以轻松切换语言而不丢失声音特征,适合配音或实时翻译等应用。Stock强调,公司希望模型听起来更像人声而非机械音。

据公司介绍,该模型专为实时性能设计。其首次音频生成时间(TTFA)为90毫秒,针对500字符的10秒样本;实时因子(RTF)为6倍,意味着生成10秒音频仅需约1.6秒。
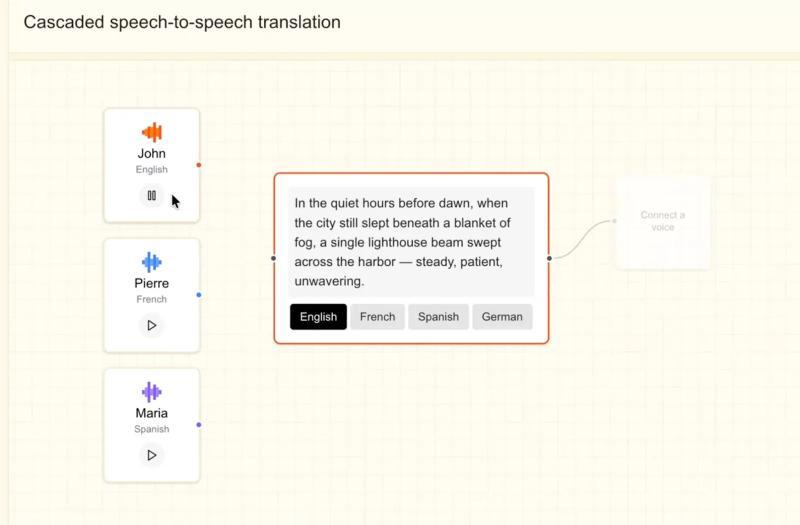
今年早些时候,Mistral推出了两款转录模型,分别针对大批量处理和低延迟实时应用。此次发布的语音模型表明公司正致力于为企业提供完整的语音产品套件。
Stock表示:“我们计划打造一个端到端平台,支持多模态输入流,包括音频、文本和图像,同时也支持多种输出。这样做的主要优势是,端到端的智能系统能处理更多信息,支持音频作为输入或输出。”
Mistral认为,其开源和高度可定制的特点将帮助企业更好地采用其语音模型,因为用户可以根据需求进行调优。


