你以为LLM算得慢是因为算力不够,其实很多时候是显存被白白浪费掉了。大模型推理卡住的往往不是GPU算不动,而是内存利用率低得离谱。要想把同一块GPU“榨干”,就得先搞懂分页注意力是怎么把碎片显存重新拼起来的。
KV缓存:为什么必须存在?
KV缓存在干什么
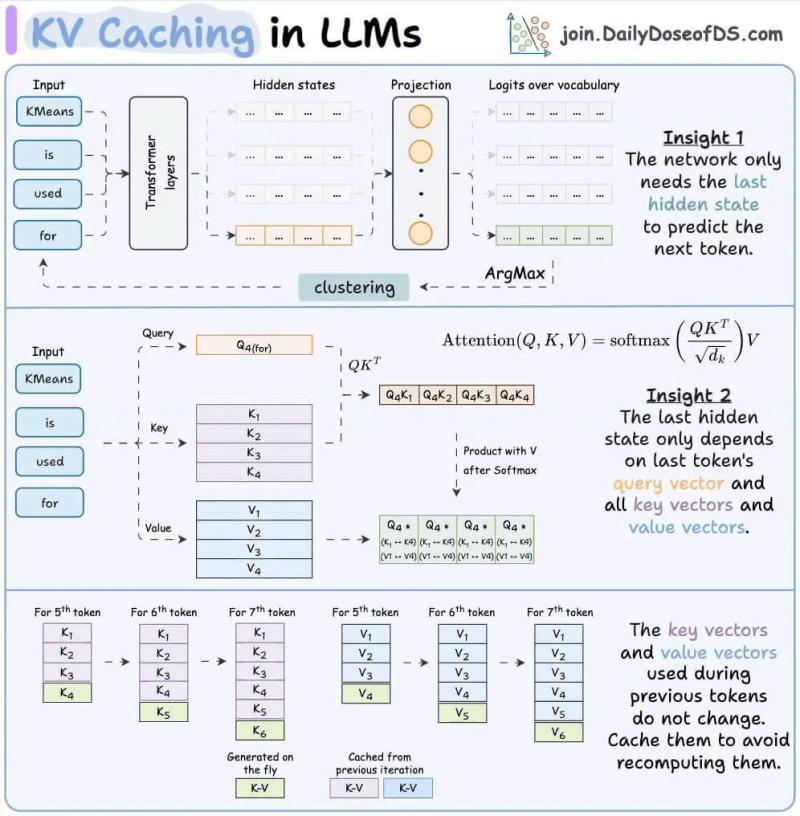
在LLM推理时,模型会把已经处理过的所有 token 的键向量和值向量存进显存,这块区域就叫 KV 缓存(之前我们有一篇专门拆解 KV 缓存的文章)。
这么做的好处很直接:生成新 token 时,模型不用重新对历史 token 做一遍完整前向计算,只需要从 KV 缓存里把对应的向量拿出来,算一遍注意力权重就行。
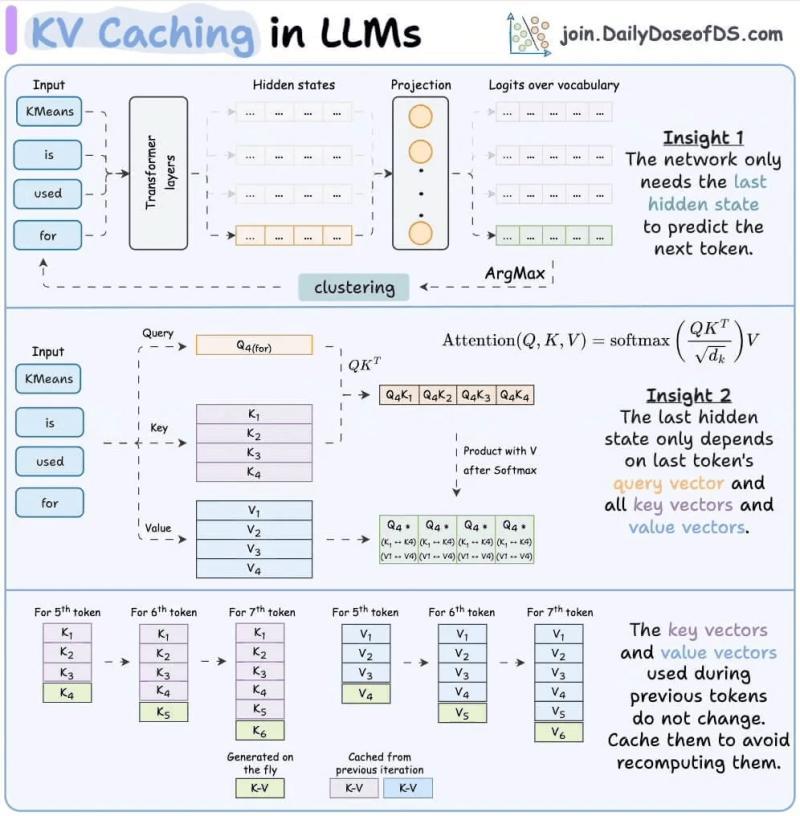
如果没有 KV 缓存,生成长度为 1000 的回复,每一步都要重新对前面所有 token 计算注意力,复杂度是 O(n²)。有了缓存,复杂度更接近 O(n),推理速度会有数量级的差别。

有用户反馈,在关闭 KV 缓存的实验环境里,同一条 1k token 的回复,生成时间直接从几秒飙到几十秒,体验几乎不可用。
O(n²) 到 O(n) 的直观差别
可以把它想象成查字典:
- 没有 KV 缓存,相当于每次查一个词,都从第一页翻到最后一页,反复扫描。
- 有 KV 缓存,就像直接用索引,翻到对应页码就能拿到结果。
据一些开源推理框架的基准测试数据,开启 KV 缓存后,长上下文生成的吞吐量可以提升 5 倍以上。听上去很美,但问题也埋在这里:缓存虽然省了算力,却把显存吃得死死的。
内存利用率为什么这么惨
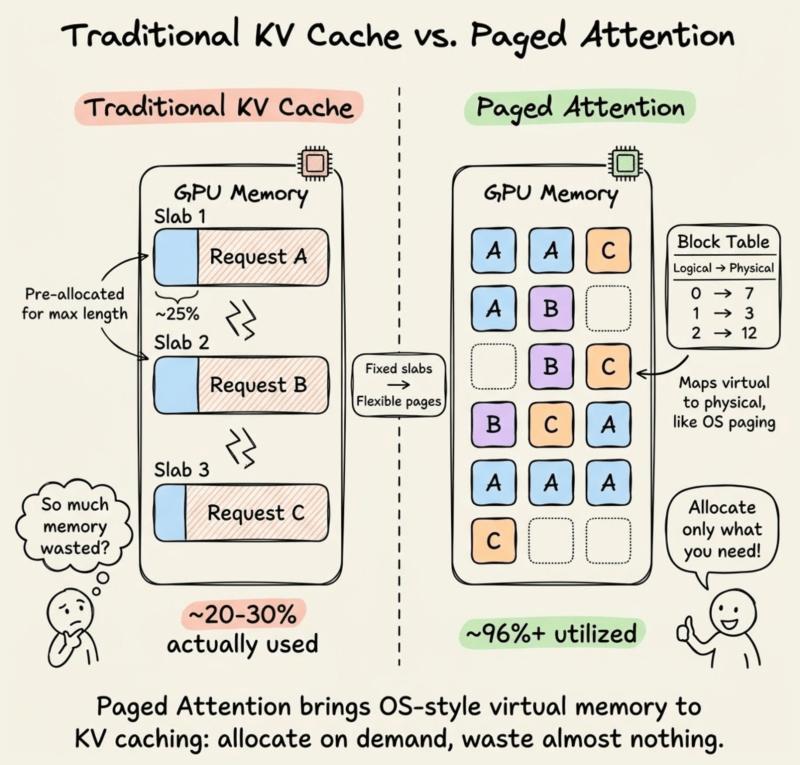
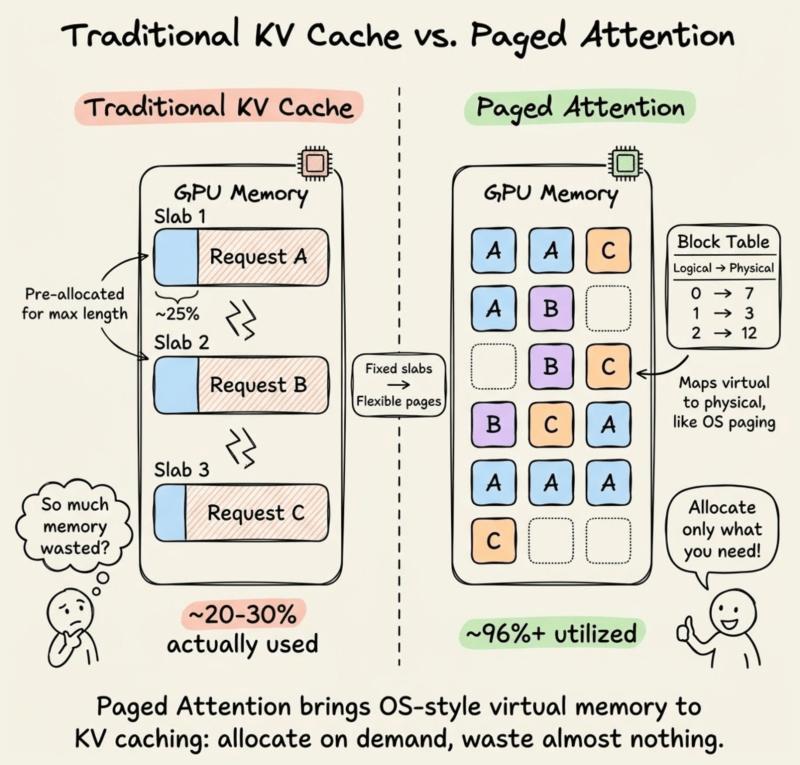
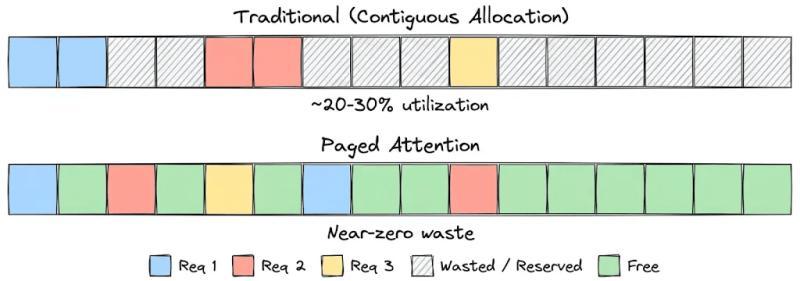
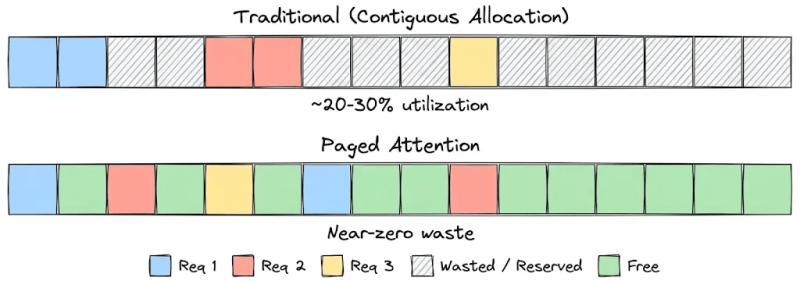
预分配带来的巨大浪费
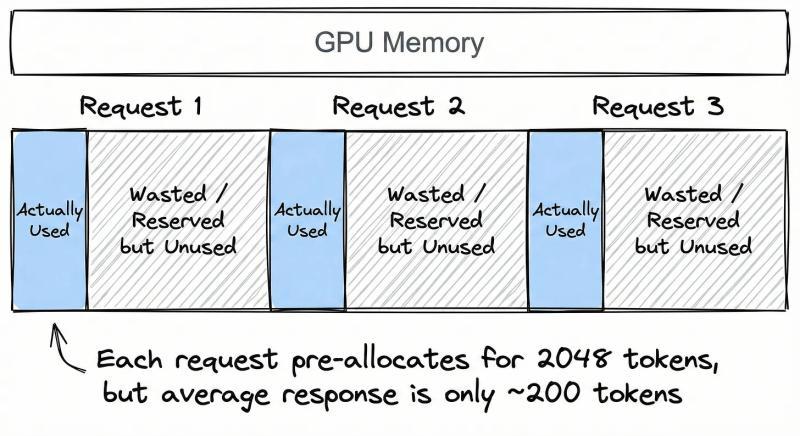
传统 KV 缓存实现有个“老毛病”:给每个请求预分配一大块连续显存。假设你同时服务 100 个用户,为了保险,每个请求都按最大长度 2048 token 预留空间,而真实平均回复长度只有 200 token。
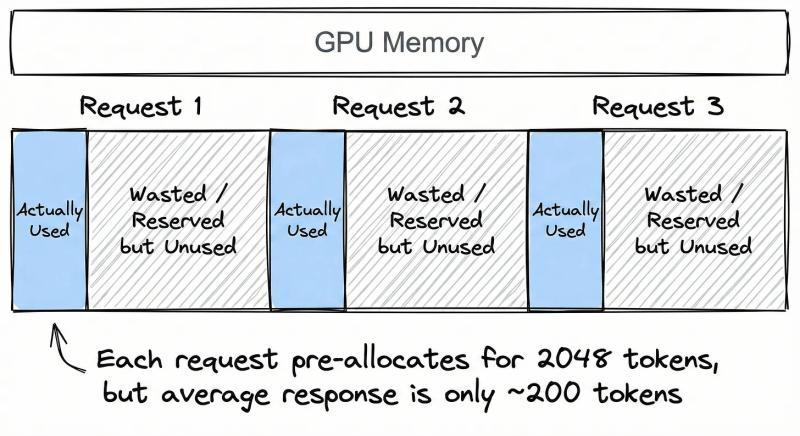
结果就是:你为每个请求多预留了大约 10 倍的空间,大部分永远用不上,却被锁死不能给其他请求用。有人形容这像是“给每个乘客包了一整节车厢”,听着就离谱。
更麻烦的是,每个请求的显存块是独立的,互不相干。哪怕 80 个用户用的是同一段系统提示,KV 缓存里也会存 80 份一模一样的前缀副本,既不能共享,也很难回收。
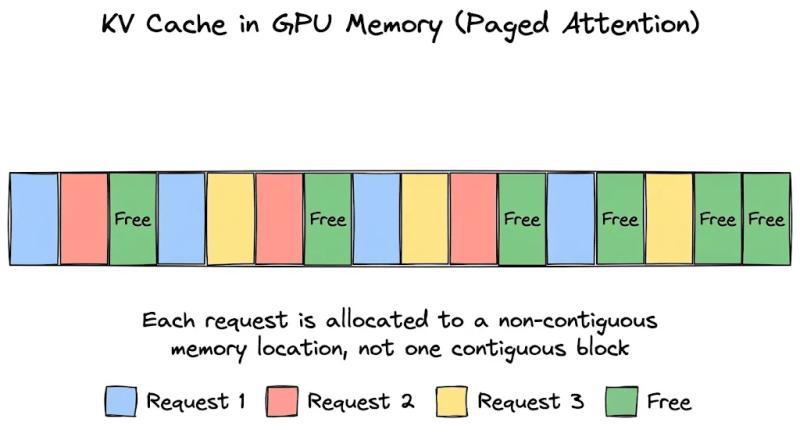
碎片化与低吞吐量
在真实生产环境里,回复长度高度不均匀,有人只问一句话,有人贴一整份合同。显存被切成一块块大预留区后,短请求结束时会留下大量“空洞”,但这些空洞又拼不成新的大连续块。
有团队在部署 70B 级别模型时统计过:显存里真正被 KV 数据占满的部分只有大约 25%,剩下的要么是预留未用,要么是碎片,肉眼看着“很满”,实际却塞不进新请求。
这就是为什么你明明还有不少显存,却已经无法再加并发,吞吐量被硬生生压在一个很低的水平。说实话,这种浪费在大模型推理这种烧钱场景里,挺让人心疼的。
分页注意力:把操作系统那一套搬进显存
块级分配:不再迷信“大块连续”
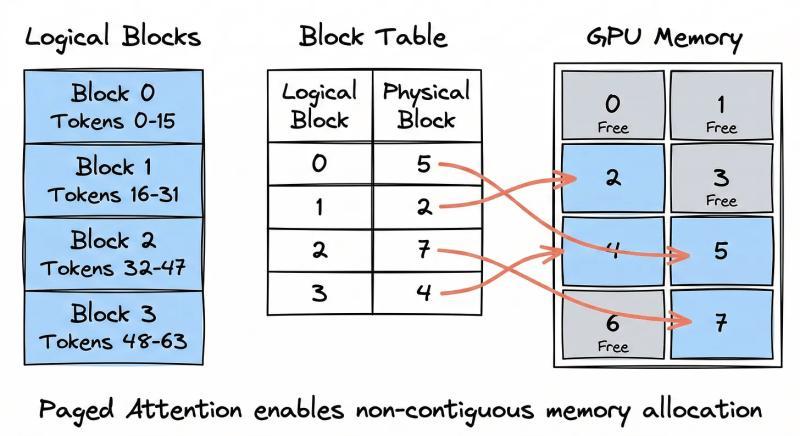
分页注意力的灵感来自操作系统的虚拟内存。程序表面上看到的是一整片连续地址空间,底层却是被拆成一页一页的小块,分散在物理内存里,由页表负责映射。
在分页注意力里,KV 缓存不再为每个请求预留一整条长条形显存,而是被拆成很多小块,每块固定容纳一定数量的 token(比如 16 个)。这些块可以散落在 GPU 显存的任意位置,不需要连续。
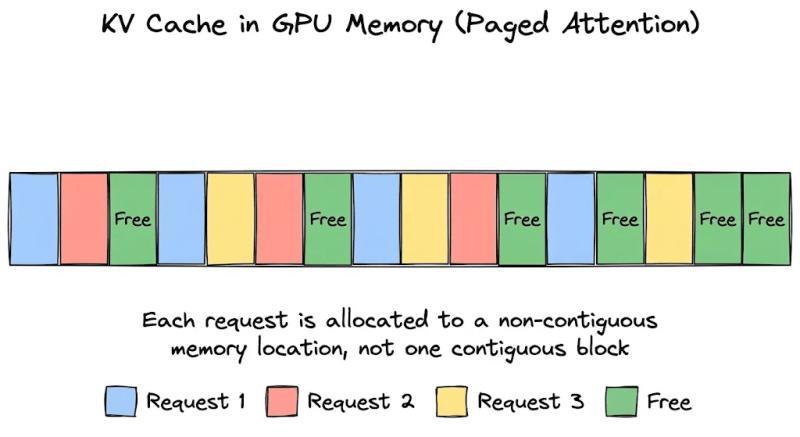
这样一来,请求只会按需申请若干个小块,生成多少 token 就占多少块,不再提前锁死一大条显存。显存碎片也能被重新利用,因为新请求可以把这些零散小块拼起来用。
块表:LLM只看“逻辑地址”
每个请求会维护一张“块表”,作用类似操作系统里的页表:
- 逻辑上,第 0、1、2…号块对应着 token 的顺序位置;
- 物理上,这些块可能散落在显存的不同区域;
- 模型要访问第 33 个 token 的 KV 时,只需通过块表找到对应物理块,再从中取出数据。
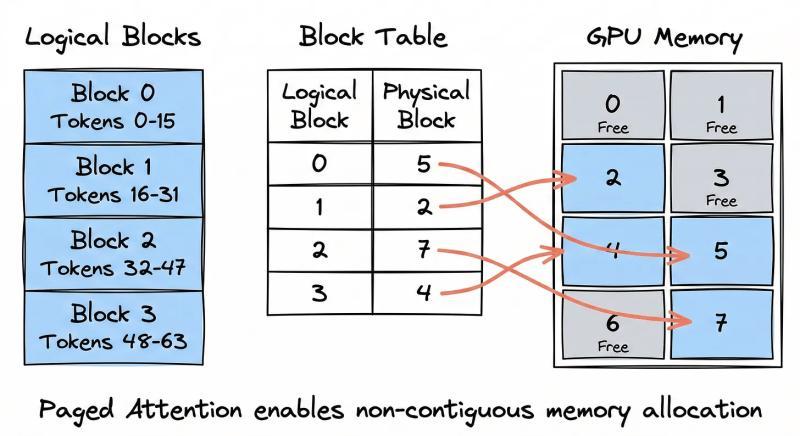
对 LLM 本身来说,它看到的仍然是一段“连续”的上下文序列,完全不用关心底层这些块是怎么拼出来的。调度器在背后悄悄搬运和重排块,模型只管算注意力。
这套机制听起来有点复杂,但从工程实践看,块表查找的开销远小于节省下来的显存和提升的并发能力。
共享前缀:系统提示只存一份
多请求共享同一段上下文
分页注意力里最聪明的一招,是利用“共享前缀”。在真实业务里,大部分请求都会带上同一段系统提示,甚至还有相同的 few-shot 示例。
传统实现会为每个请求单独算一遍这段前缀的 KV,并各自存一份。分页注意力则允许多个请求的块表同时指向同一组物理块:
- 系统提示 + 公共上下文只算一次,KV 只存一份;
- 不同用户的块表共享这些块;
- 当生成阶段开始分叉时,再为各自新增新的块。
在一个典型企业内部助手场景里,有团队统计过:超过 90% 的请求共享同一段系统提示和安全策略说明。用共享前缀后,这部分 KV 显存占用几乎被压缩成“1 份”的成本。
写时复制与风险点
共享前缀的实现通常会用到“写时复制”(Copy-on-Write)思路:
- 只要大家都不改前缀,就共享同一物理块;
- 一旦某个请求需要在前缀上做特殊扩展,就为它单独分配新块。
这种做法的风险在于实现复杂度明显上升,调度器需要非常小心地管理引用计数和块生命周期。一些早期实现里就出现过“块被提前回收导致读到脏数据”的 bug,这类问题排查起来会比较折磨人。
分页注意力带来的实际收益
显存利用率与吞吐量的提升
在分页注意力的原始论文中,作者测量了多种主流推理系统的 KV 显存利用率,发现有效利用率通常只有 20%~38%,其余都浪费在碎片和过度预留上。
引入分页注意力后,情况有明显改善:
- 在相同延迟要求下,吞吐量可以提升约 2~4 倍;
- 显存几乎只为“真实存在的 token”付费,浪费接近于零;
- 批处理能力增强,同一块 GPU 能同时服务更多并发请求。
我自己在一个内部工具上做过简单对比:同样是 24GB 显存的单卡,切到分页注意力后,并发从 16 提到 48,平均延迟变化不大,但显存占用从“看着就要爆”变成了比较平滑的锯齿形曲线。当然,这只是一个小样本实验,我也不太确定能不能代表所有场景。
谁在用分页注意力
vLLM 把分页注意力作为核心算法,几乎成了很多团队做生产部署时的首选推理引擎。TensorRT-LLM、SGLang 等框架也都实现了类似的分页机制,用来提升长上下文和高并发场景下的性能。
在最近一波“长上下文大战”里,不少厂商都在宣传 100k、甚至百万 token 上下文能力,而分页式 KV 管理几乎是这些能力背后的标配基础设施。
当你需要长期运行推理服务、面对高度不稳定的请求长度分布、又要在成本上精打细算时,分页注意力这种“显存调度层”的优化,往往比单纯堆更多 GPU 更划算。
还能从操作系统借鉴什么?
更多可迁移的 OS 思路
如果把 LLM 推理看成一个“分布式操作系统问题”,分页注意力只是第一步。还有不少 OS 概念正在被搬进大模型基础设施里:
- 优先级调度:为不同租户、不同请求类型设置优先级队列;
- 内存换页:把冷 KV 块临时挪到 CPU 内存或磁盘,再按需拉回;
- 隔离与配额:用类似 cgroup 的方式限制单个租户的显存和算力占用;
- NUMA 感知调度:在多卡、多机环境下,尽量减少跨节点通信。
这些机制组合在一起,才构成了真正可运营、可扩展的 LLM 服务平台。很多团队现在都在摸索自己的“LLMOps 操作系统”,有的偏重成本,有的偏重延迟,路线不太一样。
一个可复用的判断方法
如果你在评估某个推理框架是否适合生产使用,可以用一个简单的三步检查:
- 看它是否支持分页式 KV 管理或等价机制,而不是简单预分配;
- 看是否有共享前缀、连续对话复用 KV 的能力;
- 看监控里显存利用率与并发数的关系,是否存在“显存很满但并发上不去”的拐点。
能在这三点上给出清晰答案的框架,通常更适合承载复杂业务流量。如果你正处在选型阶段,这个小 checklist 值得先收藏一下。
如果你打算长期运营自己的大模型服务,分页注意力这套思路会反复派上用场。等哪天你发现显存又开始“看着很满却塞不下新请求”,翻回来看一眼这篇,也许会少走几步弯路。
常见问题
Q:分页注意力会不会增加延迟,得不偿失?
A:一般来说,分页注意力带来的延迟开销很小,多数场景下可以忽略。原因在于块表查找和块调度的计算量远小于注意力本身的矩阵运算,而显存利用率提升后,可以用更大的批次、更高的并发摊薄单请求延迟。实操建议是:在自己的典型负载下做 A/B 测试,对比开启和关闭分页注意力时的 P50、P95 延迟和吞吐量,再决定是否默认开启。
Q:分页注意力对长上下文有什么特别优势?
A:对长上下文请求,分页注意力的收益会更明显。因为长上下文会占用大量 KV 显存,如果按传统方式预分配,很快就会把显存挤爆,导致无法再接新请求。分页机制可以按块回收不再需要的上下文部分,并把冷数据迁移到更便宜的存储层。建议在支持 32k 以上上下文长度的服务里,优先启用分页注意力,并配合监控观察显存曲线是否更平滑。
Q:共享前缀会不会带来安全或隔离问题?
A:如果实现不当,确实可能出现隔离问题,比如块引用计数错误导致数据被错误复用。安全风险主要来自实现层面的 bug,而不是概念本身。比较稳妥的做法是:只对“只读且全局一致”的系统提示和公共模板启用共享前缀,对包含用户敏感信息的上下文一律不共享;同时在测试环境中加入针对块回收、并发读写的压力测试用例,尽量提前暴露问题。
Q:已有服务要迁移到分页注意力,改造成本大吗?
A:如果你使用的是 vLLM、TensorRT-LLM 这类已经内置分页机制的框架,迁移成本相对可控,多数工作在于改推理后端和部署脚本。真正成本较高的是自研推理引擎,需要重构 KV 管理和调度逻辑。建议的路径是:先在非核心业务上试点新的推理后端,验证稳定性和收益,再逐步迁移主流量入口,过程中要同步升级监控和告警,避免显存相关问题被放大。
Q:分页注意力适合小模型或低并发场景吗?
A:在小模型、低并发场景下,分页注意力的收益会相对有限,但并不意味着完全没用。原因是这类场景本身显存压力不大,预分配带来的浪费不那么致命。不过,如果你计划未来扩容,提前选用支持分页的框架,可以减少后续迁移成本。建议是:个人实验或小团队 demo 阶段可以不强求,但一旦开始面向真实用户、需要控制成本时,就该认真考虑分页机制。