中国AI实验室DeepSeek近日推出了其最新大型语言模型DeepSeek V4的两个预览版本——V4 Flash和V4 Pro。这是继去年发布的V3.2版本及其备受关注的R1推理模型之后的重要升级。DeepSeek表示,这两款模型均采用了专家混合(mixture-of-experts)架构,拥有高达100万令牌的上下文窗口,能够处理大型代码库或文档输入。专家混合技术通过激活部分参数来降低推理成本。
其中,V4 Pro模型拥有1.6万亿参数(活跃参数490亿),成为目前最大的开源权重模型,超过了Moonshot AI的Kimi K 2.6(1.1万亿参数)、MiniMax的M1(4560亿参数)以及DeepSeek之前的V3.2(6710亿参数)。较小的V4 Flash版本则拥有2840亿参数(活跃参数130亿)。
DeepSeek称,由于架构上的改进,这两款模型在效率和性能上均优于V3.2,并且在推理基准测试中几乎“缩小了与当前领先模型的差距”,无论是开源还是闭源模型。
公司还声称其新推出的V4-Pro-Max模型在推理基准测试中表现优于开源同类产品,并在部分任务上超过了OpenAI的GPT-5.2和Gemini 3.0 Pro。在编程竞赛基准测试中,DeepSeek表示两款V4模型的表现“可与GPT-5.4相媲美”。
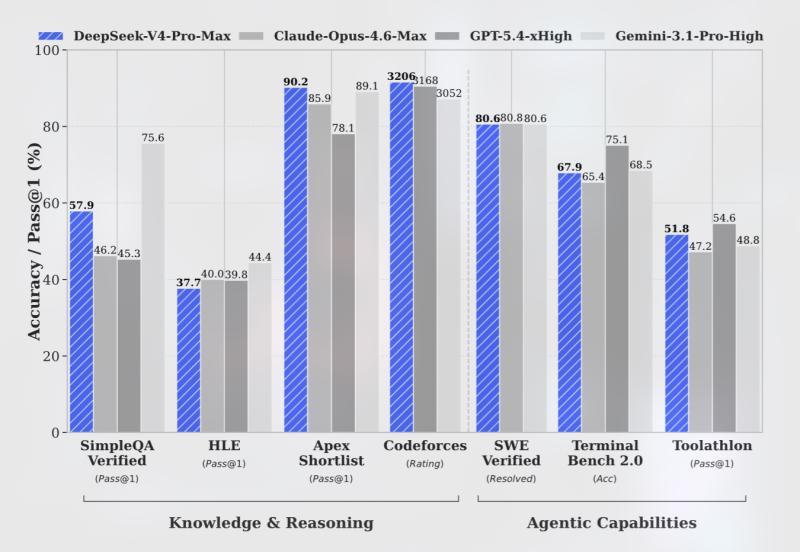

不过,在知识测试方面,这些模型稍逊于最前沿的模型,特别是OpenAI的GPT-5.4和谷歌最新的Gemini 3.1 Pro。DeepSeek实验室指出,这表明其模型的发展轨迹大约落后于顶尖模型3到6个月。
值得注意的是,V4 Flash和V4 Pro目前仅支持文本输入输出,与许多闭源竞争对手支持音频、视频和图像的多模态能力不同。
此外,DeepSeek V4的使用成本远低于目前市场上的顶尖模型。V4 Flash每百万输入令牌收费0.14美元,输出令牌收费0.28美元,价格低于GPT-5.4 Nano、Gemini 3.1 Flash、GPT-5.4 Mini和Claude Haiku 4.5。V4 Pro则分别为每百万输入令牌0.145美元和输出令牌3.48美元,同样低于Gemini 3.1 Pro、GPT-5.5、Claude Opus 4.7和GPT-5.4。
此次发布恰逢美国指控中国通过数千个代理账户大规模窃取美国AI实验室知识产权之际。此前,DeepSeek也曾被Anthropic和OpenAI指控“提炼”其AI模型,实质上是复制其技术。