99% 的人问「DeepSeek 能不能生成图片」,其实问错了对象。你看到的 DeepSeek 聊天机器人、API 定价页、第三方「DeepSeek 图片生成器」页面,很可能都不是同一件东西。如果搞不清谁负责聊天、谁负责画图,就很容易踩坑、白折腾。
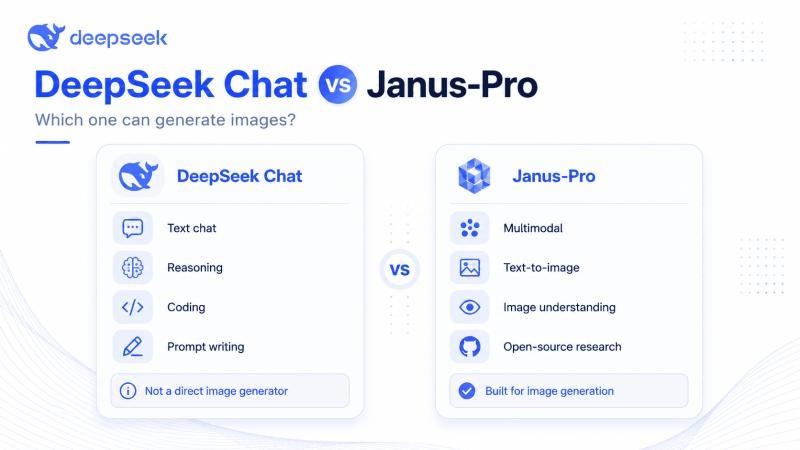
简单说:DeepSeek Chat/API 主要做文本和推理,而 DeepSeek Janus-Pro 才是具备图像生成能力的多模态模型家族。下面我们把这件事讲清楚,并给你一套可直接照抄的实用用法。
为什么大家会搞不清 DeepSeek 能不能生成图片?
很多混乱来自一个词被多次复用——「DeepSeek」。有 DeepSeek 聊天机器人,有 DeepSeek API,还有 DeepSeek-R1、DeepSeek V4 这类推理模型,另外又有 Janus、JanusFlow、Janus-Pro 这样的多模态项目。名字都挂着 DeepSeek,但功能完全不一样。
据 DeepSeek 官方 API 文档,目前主力接口是聊天补全,模型包括 deepseek-v4-flash、deepseek-v4-pro 等,重点是 JSON 输出、工具调用、前缀补全、FIM 补全等能力,看不到面向普通用户的「图片生成」端点。这部分就是你平时用来写代码、写文案、做推理的那一套。
Janus-Pro 则是另一条线。DeepSeek 在 Janus 的 GitHub 仓库中,把 Janus-Pro 定义为在多模态理解和视觉生成上大幅增强的版本,并提供了 Janus-Pro-1B 和 Janus-Pro-7B 的模型下载链接,还有在线 Demo 入口。这说明:DeepSeek 体系里,真正负责「看图+画图」的是 Janus-Pro,而不是你常用的聊天模型。
换句话说,如果你只打开一个「DeepSeek 聊天框」就期待它直接吐出图片,多半会失望;但如果你找到 Janus-Pro 或基于它的可靠界面,DeepSeek 的确能从文字生成图像。
所以,一个简单的「能不能」其实不够准确。更精确的说法是:DeepSeek Chat 不是专门的图片生成器,而 Janus-Pro 模型家族具备文本生成图片的能力。
DeepSeek 到底能不能生成图片?
答案是:能,但要用对入口。
如果你的目标是「用 DeepSeek 生成图片」,应该优先去找 Janus-Pro 或者基于 Janus-Pro 搭建的可靠界面。它们才是真正的图像生成主力。普通 DeepSeek 聊天机器人依然很有用,只是角色不同——它更适合帮你写高质量的图片提示词,然后把这些提示词丢给 DALL·E、Midjourney、Flux、Stable Diffusion、Gemini 或 ChatGPT 的图像工具,让这些专门的图像模型来出图。
很多用户的最佳实践,其实是:用 DeepSeek 写 prompt,用其他模型画图,这样既省心又稳定。
什么是 DeepSeek Janus-Pro?
Janus-Pro 的定位:统一的多模态模型家族
DeepSeek Janus-Pro 是一个统一的多模态模型家族。「多模态」的意思,是它既能处理文本,也能处理图像输入输出,而不是只会聊天或只会画图的单一模型。
根据 Hugging Face 上的模型卡描述,Janus-Pro 是一种自回归框架,试图「统一多模态理解和生成」。它把视觉编码拆成不同路径,同时又保持统一的 Transformer 架构。通俗一点说:看图和画图走的是不同的视觉通道,但在同一个大脑里协同工作,减少两种任务互相抢资源、互相干扰的问题。
Janus-Pro 系列目前包括 Janus-Pro-1B 和 Janus-Pro-7B 两个规模。官方论文中提到,这个家族在 1B 和 7B 参数量级上做了扩展,方便在不同算力环境下部署。对开发者和研究者来说,这种「同一架构、多种大小」的设计,更利于做实验和对比。
Janus-Pro 更适合谁?
Janus-Pro 不是一个「带图片按钮的聊天框」,而是一套偏底层的多模态模型。它更像是给开发者、研究者用的积木,而不是给设计师的成品海报工具。你可以用它做:
- 文本到图像的生成实验
- 图像理解与问答
- 多模态推理任务
- 教学或研究 Demo
对只想「拖个图片、点两下就出海报」的普通用户来说,Janus-Pro 可能有点「硬核」。但对想自己搭系统、做产品的人,它的开放性和可控性反而是优势。
如何用 DeepSeek Janus-Pro 生成图片?
现实可行的路径,大致有三种。
方法一:用 Hugging Face 上的 Janus-Pro Demo
对非技术用户来说,这是门槛最低的一条路。
- 打开 Hugging Face,进入 DeepSeek 官方账号页面:
https://huggingface.co/deepseek-ai/。 - 搜索 deepseek-ai/Janus-Pro-7B 或其他官方/可信的 Janus-Pro Space。
- 找到带有文本生成图片(text-to-image)功能的 Demo 页面。
- 在输入框里写一个尽量详细的英文或中文提示词。
- 点击生成,等待模型出图。
- 如果界面支持,就把生成的图片保存或下载到本地。
Hugging Face 上的 Janus-Pro-7B 页面,会标注这是一个多模态、支持 text-to-image 的模型,并链接到 Janus-Pro 论文和相关 Spaces。你也能看到有多少人下载、多少人点赞,这些都是判断是否靠谱的信号。
安全提醒:只在官方或可信的 Hugging Face Space 里操作,不要在来路不明的网站输入隐私照片、身份证件、银行卡信息或账号密码。市面上一些打着「DeepSeek 图片生成器」旗号的站点,既不官方,也不透明,风险很高。
方法二:在本地运行 Janus-Pro
这条路更适合开发者和技术用户。
DeepSeek 的 Janus GitHub 仓库提供了安装说明、模型路径、推理示例,以及一条本地 Gradio Demo 启动命令。仓库里会写明需要的 Python 环境版本、依赖包,以及如何从 Hugging Face 下载 Janus-Pro 模型权重。
本地部署通常需要准备:
- 安装好 Python 和相关依赖包
- 克隆 Janus 仓库代码
- 下载 Janus-Pro 模型文件(1B 或 7B)
- 一块算力还不错的 GPU 和足够的显存
- 基本的命令行操作能力
- 预留一些时间排查依赖冲突和报错
好处是:你完全掌控环境,不用排队、不怕 Demo 下线,还能把 Janus-Pro 集成进自己的应用或工作流。代价是:过程偏折腾,对非技术用户来说,门槛确实不低。有用户反馈,第一次从零搭环境,可能要花一整天甚至更久。
方法三:用 DeepSeek 帮你写更好的图片提示词
对很多人来说,这反而是最实用、性价比最高的方案。
你可以把普通 DeepSeek 聊天模型当成「提示词工程师」,让它帮你写出结构清晰、细节丰富的 prompt,然后把这些 prompt 复制到 DALL·E、Midjourney、Flux、Stable Diffusion、Gemini 或 ChatGPT 的图像工具里,由这些专门的图像模型负责出图。
一个通用可复用的提示模板是:
Create a detailed image-generation prompt for [tool name] showing [subject], [style], [composition], [lighting], [camera/medium], [mood], and [negative prompt if supported].
示例 1:产品效果图
Create a premium product mockup prompt for a matte black smart water bottle on a stone kitchen counter, soft morning light, minimalist luxury style, shallow depth of field, realistic reflections, clean background, no text, no distorted logos.
示例 2:社交媒体插画
Create a square social media illustration of a small business owner using AI tools at a desk, friendly modern vector style, warm colors, clear composition, simple background, space at the top for headline text.
示例 3:写实风景概念图
Create a cinematic image prompt for a desert research station at sunset, wide-angle composition, dramatic clouds, realistic lighting, subtle futuristic architecture, natural colors, high detail, no people, no text.

很多设计师的真实体验是:让 DeepSeek 帮忙写 prompt,再丢给 Midjourney 或 Stable Diffusion,出图质量和效率都明显提升,而且完全不用自己折腾 Janus-Pro 环境。
DeepSeek Janus-Pro 生成图片的局限

Janus-Pro 的表现很亮眼,但离「完美」还有距离。
在官方论文中,Janus-Pro-7B 在 GenEval 上的整体得分约为 0.80,在 DPG-Bench 上整体得分约为 84.19,这在开源多模态模型里属于相当不错的水平。不过,基准测试是基准测试,不能保证你每一个真实业务场景的 prompt 都能打赢商业闭源大模型。
目前比较重要的限制包括:
- 输出质量受提示词、Demo 配置、硬件环境影响较大
- 在极细节层面,可能不如专门为商业设计优化的高端图像模型
- 小尺寸人脸、手部、复杂物体、图中嵌入文字等场景,容易出现瑕疵
- 论文和模型卡提到,多模态理解部分存在 384 × 384 输入分辨率限制,对 OCR 等精细任务有影响
- 公共 Demo 可能排队时间长、偶尔无法访问或有调用上限
- 本地部署对算力和技术能力要求较高
更合理的期待是:把 Janus-Pro 当成一个能力很强的开源多模态模型,而不是一款打磨到极致的商业设计工具。要做高端广告物料,它未必是最省心的选择。
DeepSeek 生成图片是免费的吗?
要看你怎么用。
从模型本身来看,Janus 系列以开源形式发布,代码仓库采用 MIT 许可证,模型使用则受 DeepSeek Model License 约束。理论上,你可以免费访问模型权重,但这不代表所有界面都免费。Hugging Face 的 Demo 可能有排队、调用次数限制,甚至临时下线。
如果你在本地跑 Janus-Pro,不需要按「每张图」付费,但你要自己承担硬件成本、电费、存储空间和维护时间。有用户算过账,一块中高端显卡加电费,长期下来也不是小数目。
在把 DeepSeek 生成的图片用于商业用途之前,务必查看你所用模型、Demo 或第三方服务当前的许可证条款,确认是否允许商用、是否需要署名或购买额外授权。
DeepSeek 和 DALL·E、Midjourney、Flux、Stable Diffusion 谁更强?
没有一个统一的「谁更强」答案。
Janus-Pro 在多模态基准上的成绩很亮眼,但设计师更关心的是:出图好不好看、风格稳不稳定、调参麻不麻烦。很多专业设计师依然偏爱 Midjourney 的风格和生态;喜欢高度可控和本地部署的开发者,会更倾向 Stable Diffusion 或 Flux;而研究者和开源爱好者,则更看重 Janus-Pro 的开放性和多模态统一架构。
从我自己的观察看,如果你追求的是「研究+可定制」,Janus-Pro 很有吸引力;如果你追求的是「马上出一批能上广告位的图」,商业闭源工具往往更省事。
DeepSeek 图片生成最适合用在什么场景?
DeepSeek Janus-Pro 更适合这些用途:
- 需要高度贴合文字描述的概念图
- 多模态研究与实验项目
- 开发者测试和对比不同开源多模态模型
- 低成本原型设计和快速验证想法
- 教学、课程或公开演示中的多模态 Demo
- 帮其他图像工具写更精准的提示词
它也很适合用来观察「开源多模态模型正在往哪里走」。Janus-Pro 把理解和生成放在同一框架里,而不是把「画图」做成一个完全独立的产品,这种设计思路本身就很值得关注。
什么时候更应该用其他 AI 图片生成器?
如果你有这些需求,优先考虑其他图像生成工具会更稳:
- 高分辨率、极度精修的商业视觉稿
- 复杂的图片编辑、局部修改
- Inpainting / Outpainting 等高级修图能力
- 长期项目中需要角色形象高度一致
- 品牌视觉风格长期统一管理
- 极简、零门槛的操作界面
- 快速产出可直接投放的营销素材
- 图片中需要清晰、可控的文字排版
在这种场景下,DeepSeek Janus-Pro 虽然能用,但可能不是最优解。更现实的做法是:用 DeepSeek 帮你写 prompt,再交给 DALL·E、Midjourney、Flux 或 Stable Diffusion 出最终图,这样既利用了 DeepSeek 的语言优势,又享受了专业图像模型的画面质量。
如何用 DeepSeek 写出更好的图片提示词?
一个简单好记的提示词公式是:
主体 + 环境 + 风格/媒介 + 构图 + 光线 + 镜头/画面形式 + 氛围 + 质量/细节要求 + 约束条件
示例:
A futuristic electric bicycle parked outside a modern glass café, rainy evening street, realistic commercial photography, three-quarter angle, soft reflections on pavement, warm interior lighting, 50mm lens, premium technology mood, high detail, no text, no people.
实用小技巧:
- 把主体说清楚:是什么、多少个、在做什么
- 描述环境:室内/室外、城市/自然、时间、天气
- 指定风格或媒介:油画、赛博朋克、商业摄影、扁平插画等
- 写明光线和氛围:暖光/冷光、柔和/强烈、轻松/紧张
- 给出构图:特写、半身、远景、俯视、仰视等
- 少在图里要求复杂文字,容易翻车
- 一次生成多张,挑最好的再微调
- 每次只改动一个要素,方便对比效果
- 如果工具支持,再加负面提示词(不要的元素)
无论你是直接用 Janus-Pro,还是用 DeepSeek 帮其他图像模型写 prompt,这套方法都能复用,属于值得收藏的通用模板。
使用「DeepSeek 图片生成器」前的安全与来源检查
在任何网站上传图片或输入提示词前,可以先过一遍这个小清单:
- 是否明确标注为 DeepSeek 官方、官方 GitHub 仓库或官方 Hugging Face 模型页?
- 网站是否清楚说明运营方是谁、公司或个人信息是否透明?
- 是否在你了解功能前就急着要你付费或绑定银行卡?
- 你是否上传了隐私照片、证件、工作文档等敏感内容?
- 是否清楚写明许可证和商业使用条款?
- 页面宣传是否夸大其词、与官方信息明显不符?
- 是否假装是官方,却完全不链接 DeepSeek、GitHub 或 Hugging Face?
DeepSeek 官方也提醒用户,获取项目信息要以官方账号为准,其他渠道的说法不代表官方立场。遇到「一键生成、永久免费、官方合作」这类话术时,多留个心眼比较好。
最后一句:DeepSeek 能不能生成图片?
如果你还在纠结「DeepSeek 能不能生成图片」,可以这样记:
DeepSeek Chat/API 主要负责文本、推理、写代码和写提示词;DeepSeek Janus-Pro 才是负责多模态理解和图像生成的模型家族。
对普通用户来说,最轻松的路径,要么是找一个靠谱的 Janus-Pro 在线 Demo 玩一玩,要么就是把 DeepSeek 当成「提示词专家」,配合 DALL·E、Midjourney、Flux、Stable Diffusion 等图像模型使用。对开发者和研究者来说,Janus 的 GitHub 仓库和 Hugging Face 模型页,是你搭建和实验的起点。
如果你正打算选一套「AI 画图」方案,这套区分方法会帮你少走很多弯路。等哪天你真的需要做一个多模态项目时,回头翻出这篇文章,可能比问十个朋友都更有用。
常见问题
Q:普通 DeepSeek 聊天机器人能直接生成图片吗?
A:不能直接生成图片,它本身是以文本和推理为主的聊天模型。原因在于当前公开的 DeepSeek Chat/API 接口只提供聊天补全、工具调用等功能,没有面向终端用户的图片生成端点。更实际的做法,是让 DeepSeek 帮你写详细的图片提示词,再把这些提示词复制到 DALL·E、Midjourney、Flux 或 Stable Diffusion 等图像模型中使用。这样既能利用 DeepSeek 的语言优势,又能享受专业图像模型的画面质量。
Q:我想用 DeepSeek 生成图片,最简单的方式是哪种?
A:对大多数人来说,最简单的是使用 Hugging Face 上的 Janus-Pro 官方 Demo。你只需要打开浏览器,找到 deepseek-ai/Janus-Pro-7B 或其他官方 Space,输入提示词就能出图。之所以推荐这种方式,是因为不需要本地安装环境,也不必配置显卡和依赖,适合想快速体验效果的用户。操作时记得确认 Space 是否来自官方账号,并避免在不可信页面输入隐私信息或支付信息。
Q:Janus-Pro 生成的图片能用于商业用途吗?
A:有可能可以,但必须先看清具体许可证条款。Janus 系列代码仓库采用 MIT 许可证,而模型权重使用受 DeepSeek Model License 约束,不同版本和不同第三方界面可能还有额外限制。判断时要关注三点:是否允许商用、是否要求署名或回链、是否禁止特定行业或用途。建议在正式商用前,仔细阅读 GitHub 仓库和 Hugging Face 模型卡中的 License 部分,必要时保留截图或文档记录,避免后续产生合规风险。
Q:DeepSeek Janus-Pro 和 Midjourney 比,画质会差很多吗?
A:在某些精修商业场景下,Midjourney 的画质和风格一致性往往更占优势。原因是 Midjourney 长期针对设计和视觉效果做了大量闭源优化,并配套了成熟的社区和工作流,而 Janus-Pro 更偏向开源多模态研究和通用能力。实际使用中,你可以用同一组提示词分别在 Janus-Pro 和 Midjourney 上测试,对比细节表现、风格稳定性和出图速度,再决定哪个更适合你的项目。需要高端广告物料时,建议优先用商业工具,把 Janus-Pro 留给概念验证和研究实验。
Q:本地部署 Janus-Pro 需要多强的电脑?
A:至少需要一块有独立显存的中高端显卡,以及足够的内存和磁盘空间。Janus-Pro-7B 这类模型体积较大,推理时显存占用也不低,如果显卡显存不足,可能只能选择更小的 1B 版本或使用量化模型。判断是否够用的一个简单标准是:你的显卡是否能流畅跑主流大模型(如 7B 级别的 LLM),如果已经很吃力,那跑 Janus-Pro 生成图片时也会卡顿甚至报错。建议在部署前先看 GitHub 仓库中的硬件建议,并预留一定冗余,避免频繁因为显存不足而中断。


