产品详细介绍
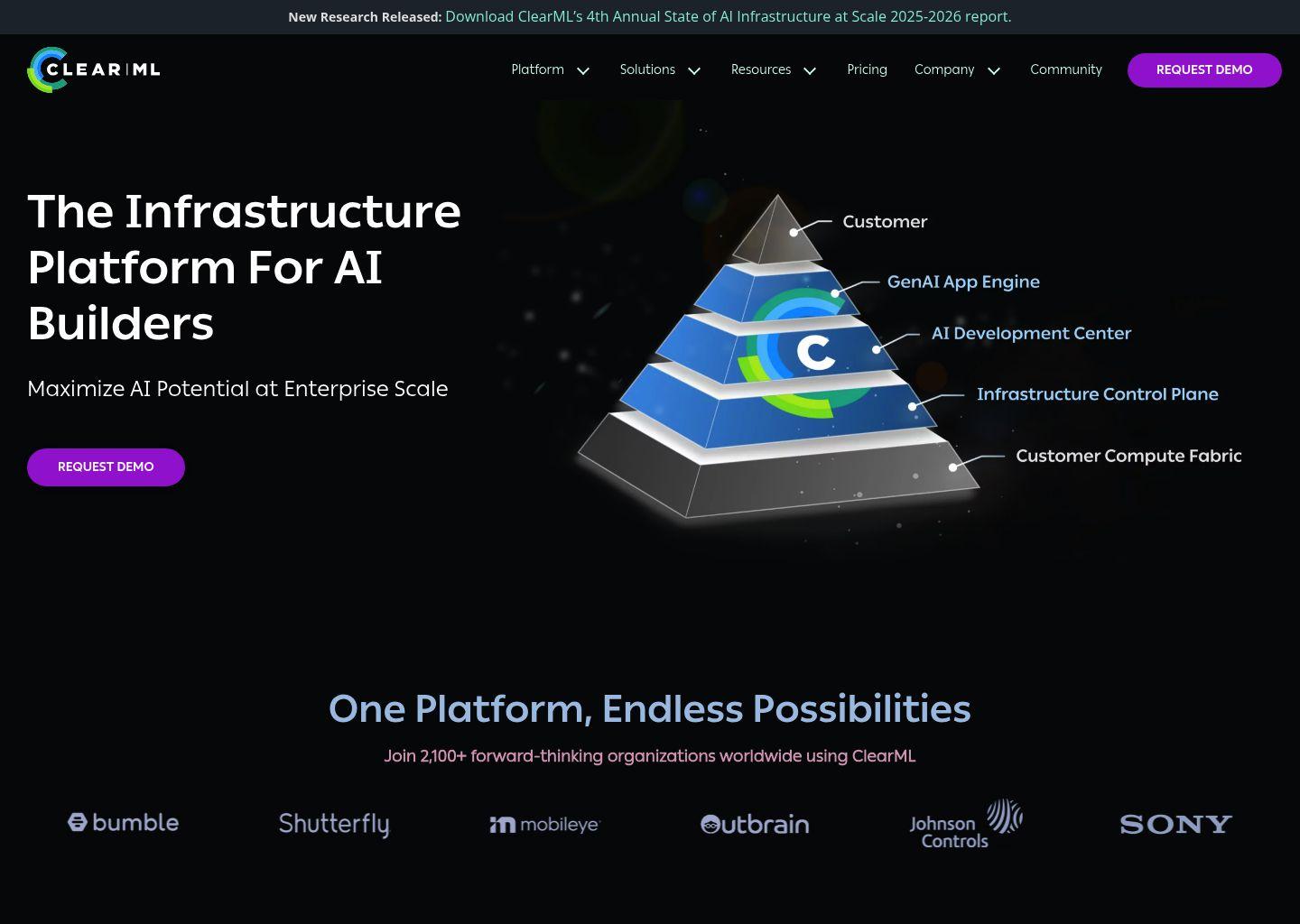
ClearML 是一套面向企业与团队的 AI 基础设施平台,提供从算力管理、模型开发到 GenAI 应用部署的端到端解决方案。平台采用三层架构设计,帮助组织在保证安全与合规的前提下,最大化 GPU 利用率、降低算力与人力成本,并加速 AI 项目从概念到落地的全流程。
- 基础设施控制平面(Infrastructure Control Plane)
ClearML 的控制平面用于统一连接与管理分布在本地数据中心、公有云或混合云环境中的 GPU 集群:
- 支持多云与本地混合部署,真正做到 云无关、厂商无关、芯片无关、环境无关;
- 提供集群统一视图与调度能力,自动分配与回收算力资源,提高 GPU 利用率;
- 内置多租户(Multi-tenancy)、基于角色的访问控制(RBAC)与计费/成本核算能力,方便企业进行安全隔离与成本管理;
- 通过策略化调度与资源配额控制,帮助团队在性能与成本之间取得最佳平衡,延长现有硬件的使用周期,推迟新硬件采购。
- AI 开发中心(AI Development Center)
AI 开发中心为数据科学家、机器学习工程师和研究人员提供统一的开发与实验环境:
- 支持远程访问与协作,团队成员可在任意地点接入统一平台进行开发、训练与测试;
- 集成实验管理、版本控制与可视化监控,便于对模型训练过程进行追踪与复现;
- 通过与底层控制平面打通,实现从 Notebook/训练脚本到大规模分布式训练的无缝切换;
- 支持多种框架与工具链,适配不同技术栈与业务场景,减少环境搭建与维护成本。
- GenAI 应用引擎(GenAI App Engine)
GenAI 应用引擎专注于大语言模型(LLM)及生成式 AI 工作负载的部署与运维:
- 一键将 LLM 部署到已连接的 GPU 集群上,无需手动处理复杂的网络、认证与安全配置;
- ClearML 负责底层服务编排、负载均衡与安全接入,用户只需关注模型与业务逻辑;
- 支持自定义工作流与访问策略,可为不同团队、业务线或应用配置独立的访问与配额;
- 内置调度器自动根据负载情况分配资源,确保关键 GenAI 工作负载的性能与稳定性。
通过这三层架构,ClearML 将基础设施管理、AI/ML 开发与 GenAI 部署整合在同一平台中,帮助企业:
- 提升 GPU 利用率,减少闲置算力;
- 降低计算与人力成本,减少重复运维与环境搭建工作;
- 加速产品上市时间(Time-to-Market),让 AI 项目更快从实验走向生产;
- 在保持灵活性的同时,避免对单一云厂商或硬件供应商的过度绑定。
简单使用教程
以下是基于 ClearML 平台的一个简明上手流程,帮助你从零开始完成基础设施接入、模型开发与 GenAI 部署的初步体验:
- 注册与基础配置
- 访问 ClearML 官网并注册账号,创建组织或团队空间;
- 在管理控制台中完成基础设置,包括组织成员、角色与权限(RBAC)配置;
- 根据企业安全策略,启用多租户隔离与审计日志等安全选项。
- 连接 GPU 集群与云资源
- 在控制平面中添加你的算力资源:可以是本地 GPU 集群、公有云 GPU 实例或混合环境;
- 按向导配置访问凭证与网络连接(如 VPC、VPN 或专线),确保平台可以安全访问集群;
- 为不同项目或团队设置资源池与配额策略,便于后续调度与成本控制。
- 搭建 AI 开发环境
- 在 AI 开发中心中创建项目空间,用于管理数据集、代码与实验;
- 通过 Web 界面或命令行工具,将现有代码仓库(如 Git)与 ClearML 进行集成;
- 为开发人员分配 Notebook/开发容器或训练环境镜像,统一依赖与运行环境;
- 启动一次示例训练任务,验证与底层 GPU 集群的连接与调度是否正常。
- 管理与追踪模型训练
- 在平台中查看训练任务的实时日志、指标与资源使用情况;
- 使用实验管理功能记录不同超参数、数据版本与模型版本,便于对比与回溯;
- 将表现最佳的模型标记为候选版本,为后续部署做准备。
- 部署 GenAI / LLM 应用
- 进入 GenAI 应用引擎,选择需要部署的 LLM 或自训练模型;
- 选择目标集群与资源规格(GPU 数量、显存、并发限制等);
- 配置访问方式(API 端点、鉴权方式)和安全策略(如仅内部网络访问);
- 一键启动部署,由 ClearML 负责底层服务编排与网络配置;
- 部署完成后,通过提供的 API 或 SDK 将模型接入你的业务应用或内部工具。
- 监控与优化
- 在平台监控面板中持续观察 GPU 利用率、请求延迟与吞吐量等关键指标;
- 根据业务负载动态调整资源配额与调度策略,优化成本与性能;
- 利用计费与成本分析功能,评估不同项目或团队的算力消耗,指导后续资源规划。
通过以上步骤,你可以快速完成从基础设施接入、模型开发到 GenAI 部署的端到端流程,在统一平台上高效管理 AI 资产与算力资源。