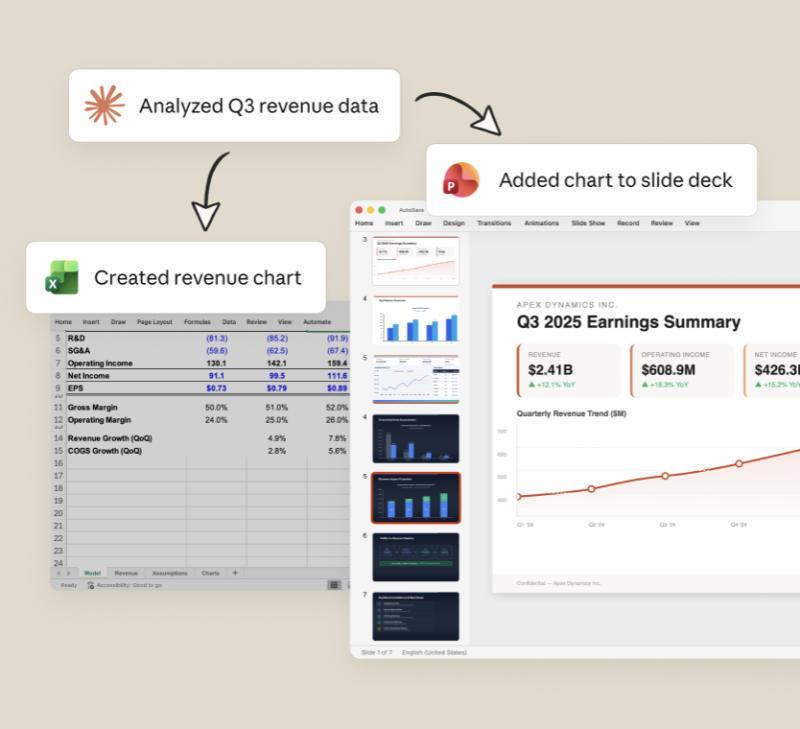
从使用场景出发
在编写任何代码之前,先确定你的 Skill 应该实现的 2-3 个具体使用场景。
良好的使用场景定义示例:
使用场景:项目冲刺规划
触发条件:用户说"帮我规划这个冲刺"或"创建冲刺任务"
步骤:
1. 从 Linear(通过 MCP)获取当前项目状态
2. 分析团队速度和容量
3. 建议任务优先级
4. 在 Linear 中创建带有适当标签和估算的任务
结果:已规划完成的冲刺,并创建了任务
问自己:
- 用户想完成什么?
- 这需要哪些多步骤工作流程?
- 需要哪些工具(内置或 MCP)?
- 应该嵌入哪些领域知识或最佳实践?
常见 Skill 使用场景类别
在 Anthropic,我们观察到三类常见使用场景:
第 1 类:文档与资产创建
用途: 创建一致、高质量的输出,包括文档、演示文稿、应用、设计、代码等。
真实案例: frontend-design skill(另见用于 docx、pptx、xlsx 和 ppt 的 Skills)
"创建具有高设计质量的独特、生产级前端界面。在构建 Web 组件、页面、artifact、海报或应用时使用。"
核心技巧:
- 内嵌样式指南和品牌标准
- 一致输出的模板结构
- 定稿前的质量检查清单
- 无需外部工具——使用 Claude 的内置能力
第 2 类:工作流程自动化
用途: 受益于一致方法论的多步骤流程,包括跨多个 MCP 服务器的协调。
真实案例: skill-creator skill
"创建新 Skills 的交互式指南。引导用户完成使用场景定义、frontmatter 生成、指令编写和验证。"
核心技巧:
- 带有验证节点的分步工作流程
- 常见结构的模板
- 内置审查和改进建议
- 迭代精炼循环
第 3 类:MCP 增强
用途: 工作流程指导,以增强 MCP 服务器提供的工具访问能力。
真实案例: sentry-code-review skill(来自 Sentry)
"通过 Sentry 的 MCP 服务器,使用 Sentry 错误监控数据自动分析并修复 GitHub Pull Request 中检测到的 bug。"
核心技巧:
- 按顺序协调多个 MCP 调用
- 嵌入领域专业知识
- 提供用户否则需要自行指定的上下文
- 处理常见 MCP 问题的错误处理
定义成功标准
你如何知道你的 Skill 在正常工作?
这些是有抱负的目标——粗略的基准,而非精确的阈值。力求严谨,但要接受其中会有一定程度的主观判断。我们正在积极开发更完善的测量指导和工具。
量化指标:
- Skill 在 90% 的相关查询上触发
- 测量方法:运行 10-20 个应该触发你的 Skill 的测试查询。追踪它自动加载的次数 vs. 需要显式调用的次数。
- 在 X 次工具调用内完成工作流程
- 测量方法:在启用和不启用 Skill 的情况下比较相同任务。统计工具调用次数和消耗的 token 总量。
- 每个工作流程 0 次 API 调用失败
- 测量方法:在测试运行期间监控 MCP 服务器日志。追踪重试率和错误代码。
定性指标:
- 用户不需要提示 Claude 下一步该做什么
- 评估方法:在测试期间,记录你需要重定向或澄清的频率。向测试用户征求反馈。
- 工作流程无需用户纠正即可完成
- 评估方法:将相同请求运行 3-5 次。比较输出的结构一致性和质量。
- 跨会话结果一致
- 评估方法:新用户能否在最少指导下第一次就完成任务?
技术要求
文件结构
your-skill-name/
├── SKILL.md # 必须——主 Skill 文件
├── scripts/ # 可选——可执行代码
│ ├── process_data.py # 示例
│ └── validate.sh # 示例
├── references/ # 可选——文档
│ ├── api-guide.md # 示例
│ └── examples/ # 示例
└── assets/ # 可选——模板等
└── report-template.md # 示例
关键规则
SKILL.md 命名:
- 必须完全命名为
SKILL.md(区分大小写) - 不接受任何变体(SKILL.MD、skill.md 等)
Skill 文件夹命名:
- 使用 kebab-case:
notion-project-setup✅ - 不使用空格:
Notion Project Setup❌ - 不使用下划线:
notion_project_setup❌ - 不使用大写:
NotionProjectSetup❌
不包含 README.md:
- 不要在你的 Skill 文件夹内包含 README.md
- 所有文档放在 SKILL.md 或 references/ 中
- 注意:通过 GitHub 分发时,你仍然需要在仓库级别为人类用户提供 README——参见「分发与共享」章节。
YAML Frontmatter:最重要的部分
YAML frontmatter 是 Claude 决定是否加载你的 Skill 的方式。务必把这部分做好。
最小必要格式:
---
name
: your-skill-name
description
: What it does. Use when user asks to [specific phrases].
---这就是你开始所需的全部内容。
字段要求:
name(必须):
- 仅使用 kebab-case
- 无空格或大写字母
- 应与文件夹名称匹配
description(必须):
- 必须同时包含:
- 该 Skill 的功能
- 何时使用它(触发条件)
- 少于 1024 个字符
- 无 XML 标签(
<或>) - 包含用户可能说的具体任务
- 如相关,提及文件类型
license(可选):
- 将 Skill 开源时使用
- 常用:MIT、Apache-2.0
compatibility(可选):
- 1-500 个字符
- 说明环境要求:例如目标产品、所需系统包、网络访问需求等
metadata(可选):
- 任意自定义键值对
- 建议:author、version、mcp-server
- 示例:
metadata
:
author
: ProjectHub
version
: 1.0.0 mcp-server: projecthub
安全限制
Frontmatter 中禁止:
- XML 尖括号(
< >) - 名称中含有 "claude" 或 "anthropic" 的 Skills(保留字)
原因: Frontmatter 出现在 Claude 的系统提示中。恶意内容可能注入指令。
编写高效的 Skills
Description 字段
根据 Anthropic 工程博客的说法:"这些元数据……提供恰到好处的信息,让 Claude 知道何时应使用每个 Skill,而无需将全部内容加载到上下文中。"这是递进式披露的第一级。
结构:
[它做什么] + [何时使用] + [核心能力]
良好 description 的示例:
# 好——具体且可执行
description
: Analyzes Figma design files and generates
developer handoff documentation. Use when user uploads .fig
files, asks for "design specs", "component documentation", or
"
design-to-code handoff
"
.
# 好——包含触发短语
description
: Manages Linear project workflows including sprint
planning, task creation, and status tracking. Use when user
mentions "sprint", "Linear tasks", "project planning", or asks
to "create tickets".
# 好——清晰的价值主张
description
: End-to-end customer onboarding workflow for
PayFlow. Handles account creation, payment setup, and
subscription management. Use when user says "onboard new
customer", "set up subscription", or "create PayFlow account".
糟糕 description 的示例:
# 太模糊
description
: Helps with projects.
# 缺少触发条件
description
: Creates sophisticated multi-page documentation
systems.
# 过于技术性,没有用户触发词
description
: Implements the Project entity model with
hierarchical relationships.
编写主体指令
在 frontmatter 之后,用 Markdown 编写实际指令。
推荐结构:
根据你的 Skill 调整此模板。用你的具体内容替换括号中的部分。
---
name
: your-skill
description
: [...]
---
#
Your Skill Name
##
Instructions
###
Step 1:
[
First Major Step
]
Clear explanation of what happens.
```
bash
python scripts/fetch_data.py --project-id PROJECT_ID
Expected output: [describe what success looks like]
```
(Add more steps as needed)
Examples
Example 1: [
common scenario]
User says: "Set up a new marketing campaign"
Actions:
1
.
Fetch existing campaigns via MCP
2
.
Create new campaign with provided parameters
Result: Campaign created with confirmation link
(Add more examples as needed)
Troubleshooting
Error: [
Common error message]
Cause: [
Why it happens]
Solution: [
How to fix]
(Add more error cases as needed)指令最佳实践
具体且可执行
✅ 好:
Run `python scripts/validate.py --input {filename}` to check
data format.
If validation fails, common issues include:
- Missing required fields (add them to the CSV)
- Invalid date formats (use YYYY-MM-DD)
❌ 差:
Validate the data before proceeding.
包含错误处理
##
Common Issues
###
MCP Connection Failed
If you see "Connection refused":
1
.
Verify MCP server is running: Check Settings > Extensions
2
.
Confirm API key is valid
3
.
Try reconnecting: Settings > Extensions > [
Your Service]
>
Reconnect清晰引用捆绑的资源
Before writing queries, consult `references/api-patterns.md`
for:
- Rate limiting guidance
- Pagination patterns
- Error codes and handling
使用递进式披露
保持 SKILL.md 专注于核心指令。将详细文档移至 references/ 并添加链接。(参见「核心设计原则」了解三级系统的工作方式。)