你以为算力贵,是因为模型大、推理慢,其实很多钱都浪费在一遍遍“重读同一段话”上。每次代理动一下手指,整段对话历史就被重新送进LLM,从系统指令到几轮前的上下文,全都再算一遍、再付一次钱。对长会话、长上下文的应用来说,这种隐形损耗远比你想象得大。要把这块成本压下来,关键不在“少用模型”,而在“别让模型重复干体力活”。
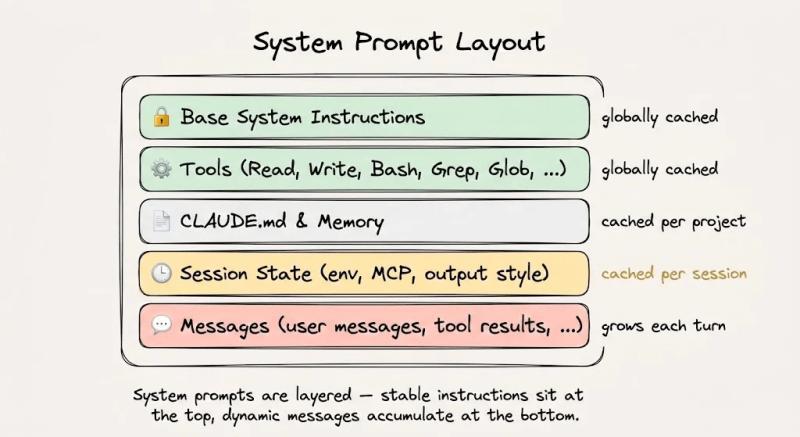
静态上下文与动态上下文
哪些内容在每一轮都没变?
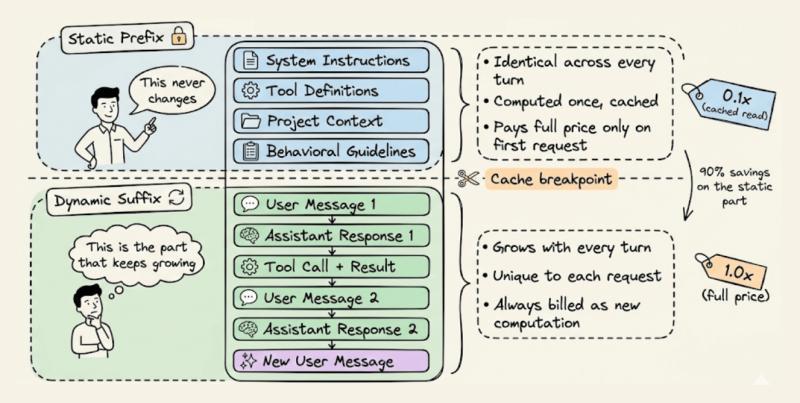
每个代理请求,其实可以拆成两块完全不同的东西:一块几乎不变,一块每轮都在长。前者就是静态前缀,后者是动态后缀。理解这点,是用好提示缓存的前提。
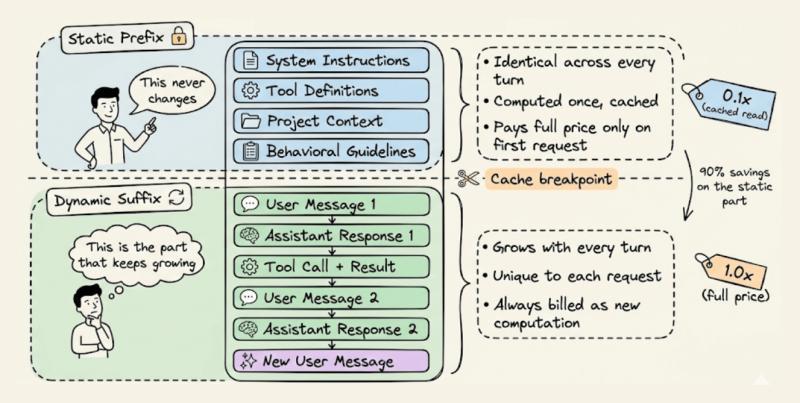
静态前缀通常包括:系统指令、工具定义、项目级上下文(比如README、CLAUDE.md)、行为准则等,这些内容在一场会话里基本不会改。动态后缀则是用户消息、助手回复、工具调用结果、终端输出等,随着对话一轮轮往后推。把这两块拆开,基础设施就能只对“变的那部分”重新算,把“没变的那部分”直接从缓存里读出来。
据一些团队的内部统计,长时间运行的代理工作流中,超过70%的输入token其实是重复的静态前缀,却被一遍遍全价计费。
一旦你接受“提示是前缀+后缀”的视角,后面所有关于缓存的架构选择都会顺理成章:什么能改、什么不能动、什么必须固定在顶部,都会变得清晰。
冗余计算到底有多贵?
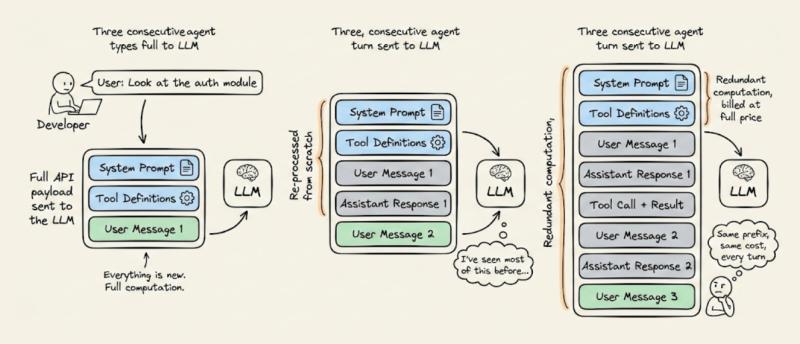
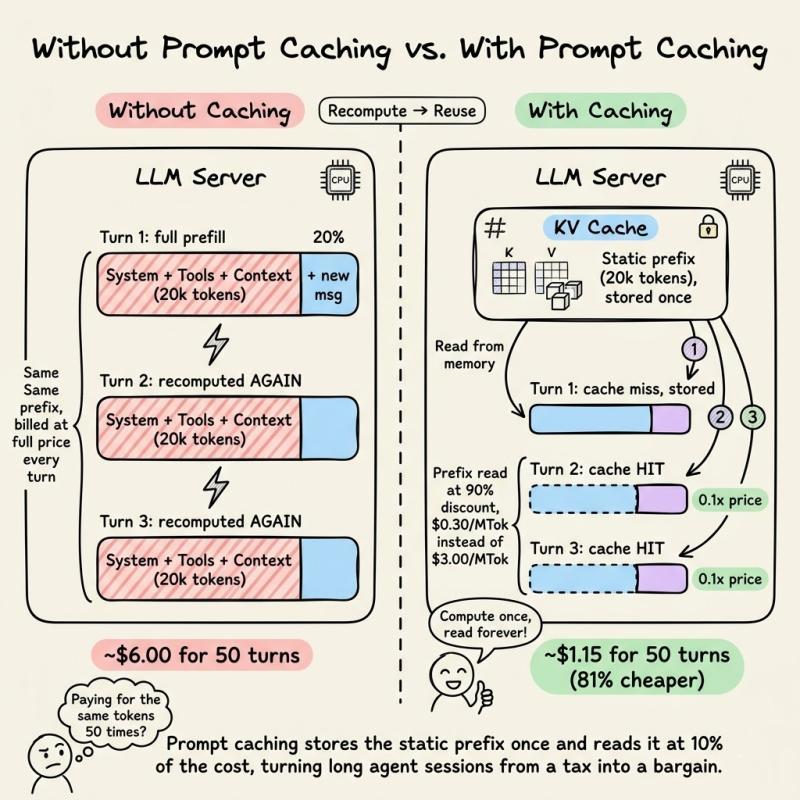
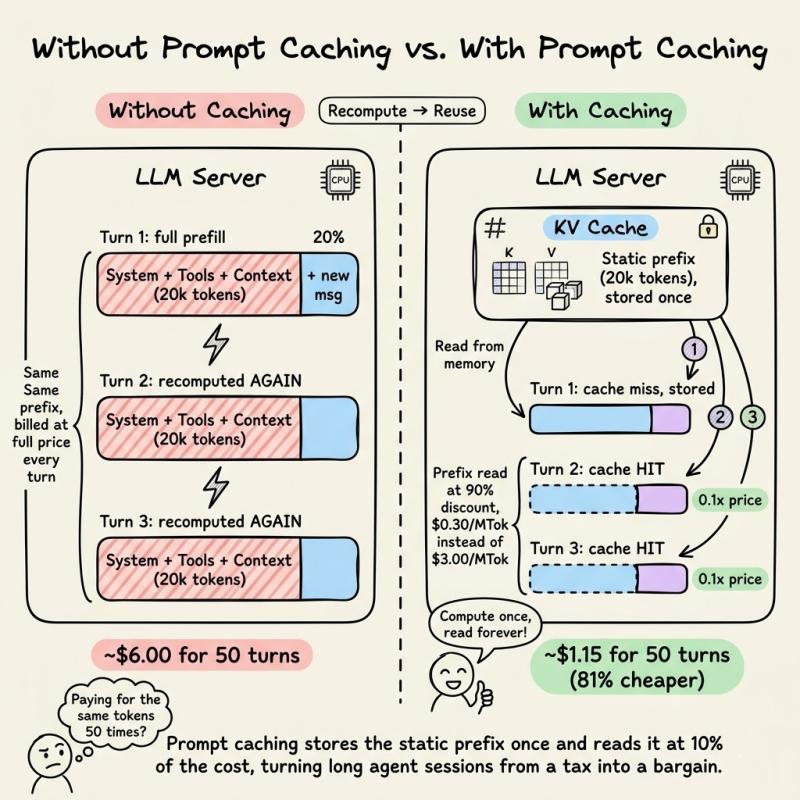
想象一个20,000个token的系统提示,里面塞满了工具定义、项目文档和行为规则。一个代理工作流跑50轮,每一轮都把这20,000个token重新送进模型,意味着有100万个token的计算是“重复劳动”。这些token本身没有产生任何新信息,却每次都按输入全价收费。
对单个用户来说,这可能只是几美元的差距;对一个有成千上万活跃会话的产品来说,就是实打实的利润空间。有团队反馈,在接入提示缓存前后,同样的代理工作流,云账单直接砍掉一半以上。说实话,如果你在做多轮对话、代码助手或长上下文检索,还没围绕缓存设计提示结构,那基本就是在给云厂商打工。
KV缓存是怎么省钱的?
Transformer在预填充阶段到底干了什么?
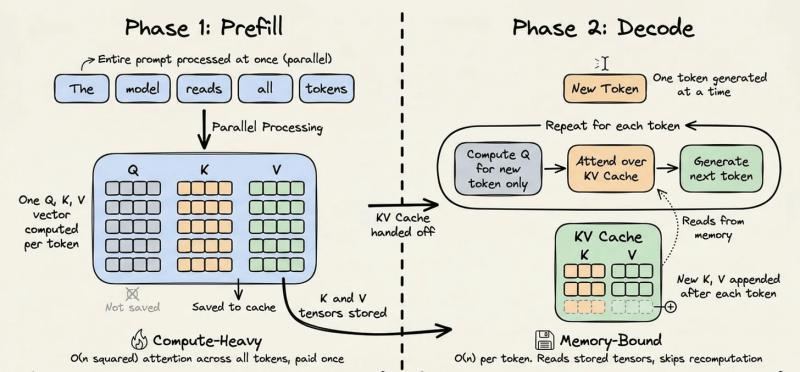
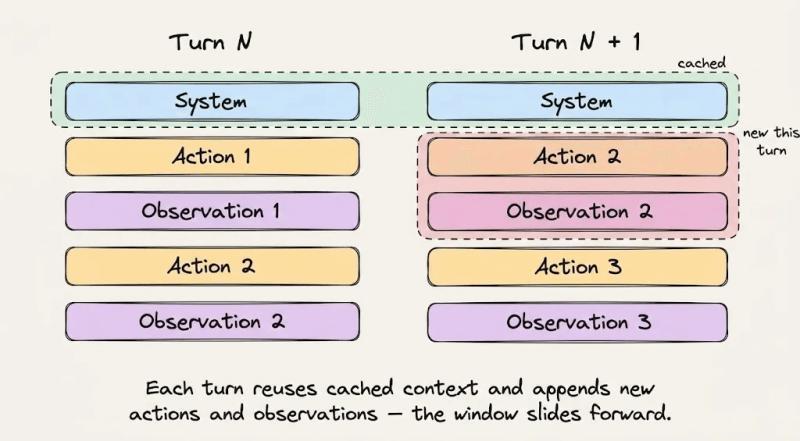
每次LLM推理,大致可以拆成两个阶段:预填充(prefill)和解码(decode)。预填充阶段会把整个输入提示吃进去,对上下文中所有token做一轮密集矩阵乘法,构建内部表示,这一步算力最重、最烧钱。解码阶段则是模型一边读历史状态,一边一个token一个token往后生成,更多是内存访问密集,而不是再做一遍全量矩阵乘法。
在预填充时,Transformer会为每个token算出三个向量:Query、Key、Value。注意力机制就是用这些向量来判断“这个token该关注上下文里的谁”。关键点在于:任意token的Key和Value只依赖它之前的token,一旦算完就不会再变。如果每次请求结束都把这些张量丢掉,下次同样的前缀又得从头算一遍,对长前缀来说完全是浪费。
KV缓存如何把O(n²)打成O(n)?
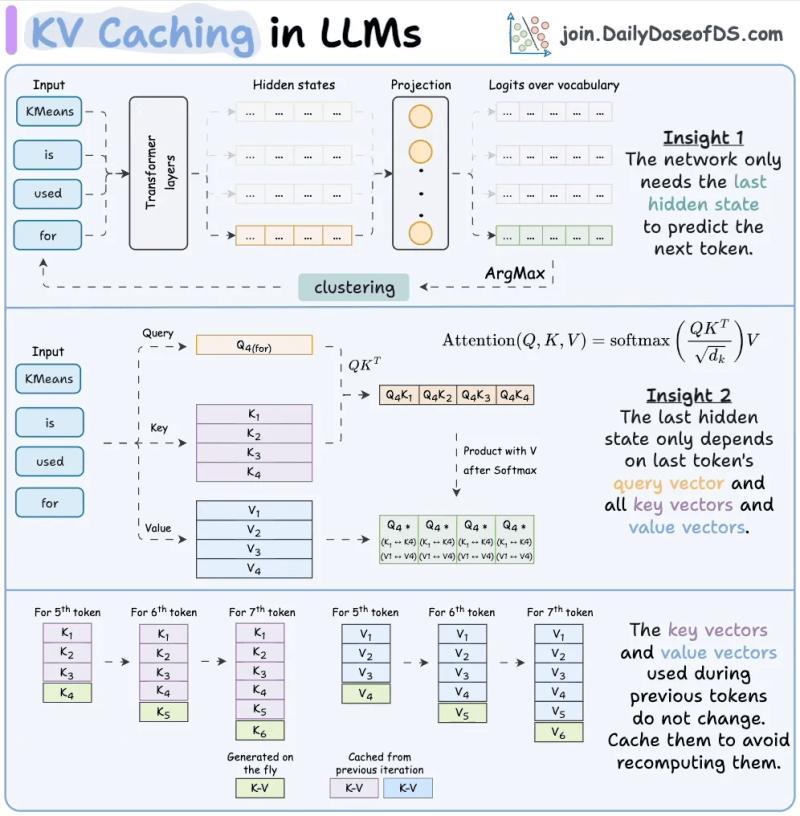
KV缓存的做法,是在推理服务器上把这些Key/Value张量持久化下来,用“token序列的加密哈希”当索引。新请求进来时,如果前缀的token序列一模一样,哈希就能对上,服务器直接从内存里把对应的KV张量读出来,跳过这部分的预填充计算。
从复杂度上看,这相当于把“每生成一个token都要对前面n个token做注意力”的O(n²)成本,压成了“只对新增的那一小段做注意力”的O(n)。对一个20,000-token前缀、重复50轮的场景,节省的算力是指数级的。有人做过粗算,在这种配置下,单轮请求的预填充成本可以被压到原来的十分之一左右。
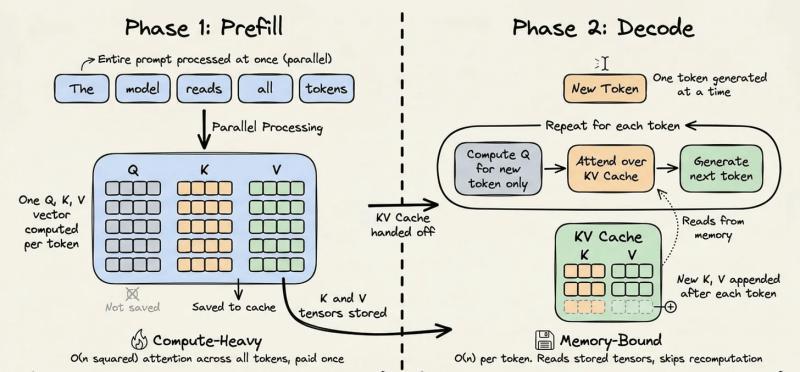
当然,缓存本身也不是免费的:写入KV张量要多付一点钱,延长缓存时间也有额外成本。怎么在“写入溢价”和“读取折扣”之间找到平衡,就成了架构设计的关键。
提示缓存的经济账
价格结构:写入贵一点,读取打九折再打九折
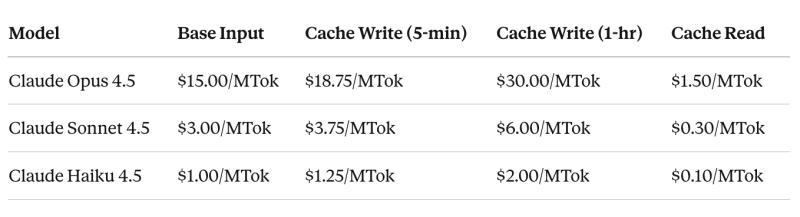
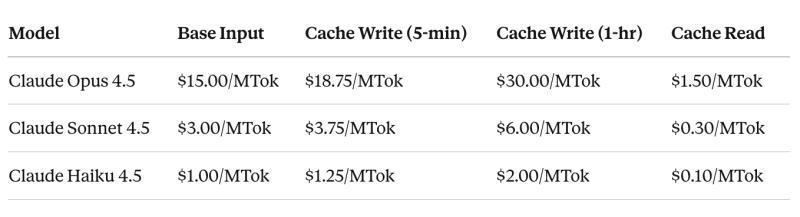
以Anthropic的Claude模型为例,提示缓存的定价大致是这样:
- 缓存读取:按基础输入价格的0.1倍计费,相当于缓存token打了90%的折扣。
- 缓存写入:按1.25倍计费,存KV张量要多付25%的溢价。
- 延长缓存一小时:按2.0倍计费,相当于为“多活一会儿”付租金。
这套结构的含义很直接:如果你能让同一段前缀被多次复用,写入时多付的那点钱,很快就会被后续的低价读取赚回来。反过来,如果缓存命中率很低,写入溢价就会变成纯损耗。有团队在内部压测时发现,当缓存命中率低于60%时,整体成本优势就开始变得不明显。
Claude Code的30分钟真实会话
Claude Code是一个围绕“让缓存一直热着”来设计的产品。下面这段30分钟的真实编码会话,就像一张放大的账单截图。
- 第0分钟:系统提示、工具定义、项目CLAUDE.md一次性加载,超过20,000个token。这一刻是整场会话里最贵的一次输入,但只付这一回。
- 第1–5分钟:你开始下指令,Claude Code派出探索子代理在代码库里乱逛、grep、打开文件。这些新内容都追加在动态后缀里,而那20,000-token的静态前缀,每轮都以每百万token 0.30美元的缓存价读取,而不是3.00美元的全价。
- 第6–15分钟:计划子代理拿到的是“摘要简报”,而不是原始工具输出,避免动态后缀被无意义放大。你点头通过后,Claude Code开始改代码。静态前缀每轮都从缓存读,命中率超过90%,每次访问还会刷新TTL,让缓存一直保持热状态。
- 第16–25分钟:你提出更多修改,触发更多工具调用和终端输出,动态后缀继续增长。到这时,会话已经处理了数十万个token,但每一轮都在重复读取那20,000-token的基础前缀,而不是重算。
- 第28分钟:你在终端敲下
/cost。如果完全不用缓存,200万个token按Sonnet 4.5的费率要付6.00美元。实际情况是,92%的token命中缓存,1.84百万token按缓存价算,总成本只有1.15美元,单任务成本直接降了81%。
这就是“热缓存”的真实样子:静态基础只付一次钱,后面几乎都是在薅缓存折扣。动态尾部才是你真正为“新信息”付费的地方。我自己第一次在内部工具上打开缓存统计时,看到命中率从30%调到90%,账单曲线肉眼可见地往下掉,那种感觉非常直观。
基于哈希的缓存有多脆?
“1 + 2 = 3”和“2 + 1”为什么不是一回事?
关于提示缓存,最反直觉的一点是:
“
1 + 2 = 3”可以命中缓存,但“2 + 1”就完全是另一个前缀。
原因在于,基础设施是对“整个token序列”从头到尾做哈希。只要序列里有任何一个token变了,哪怕只是顺序对调,哈希值就完全不同,缓存就当你是一个全新的前缀。那20,000个token的KV张量,只能眼睁睁看着被丢掉重算。
这不是一个小小的实现细节,而是Claude Code所有工程决策背后的硬约束。有用户在生产环境踩过这样的坑:系统提示里偷偷加了一个时间戳,结果每次请求的前缀都不一样,缓存命中率直接跌到个位数,账单翻倍。
真实世界里,缓存是怎么被“悄悄搞坏”的?
生产环境中,常见的缓存失效来源包括:
- 在系统提示里注入时间戳或随机ID,让每次请求的前缀都独一无二。
- JSON序列化器在不同请求间对工具schema的键采用不同排序,导致工具定义的token序列变化。
- 会话中途更新AgentTool的参数或描述,等于把整个20,000-token前缀推倒重来。
为了对抗这些“隐形杀手”,Claude Code团队总结了三条硬规则:
- 会话期间不要修改工具。工具定义属于缓存前缀的一部分,添加、删除或重排工具,都会让后续所有请求的缓存失效。
- 会话中不要切换模型。缓存是模型特定的,切到另一个模型(哪怕只是更便宜的版本),都得从零重建缓存。
- 不要通过修改前缀来更新状态。Claude Code选择在下一条用户消息里追加“提醒标签”,而不是去编辑系统提示本身,让前缀保持字节级稳定。
我也不太确定这三条是不是适用于所有场景,但在高并发、多轮长会话的产品里,它们的确是被一次次事故验证出来的“血泪经验”。
把这些原则用在你自己的代理上
提示结构:从上到下怎么排?
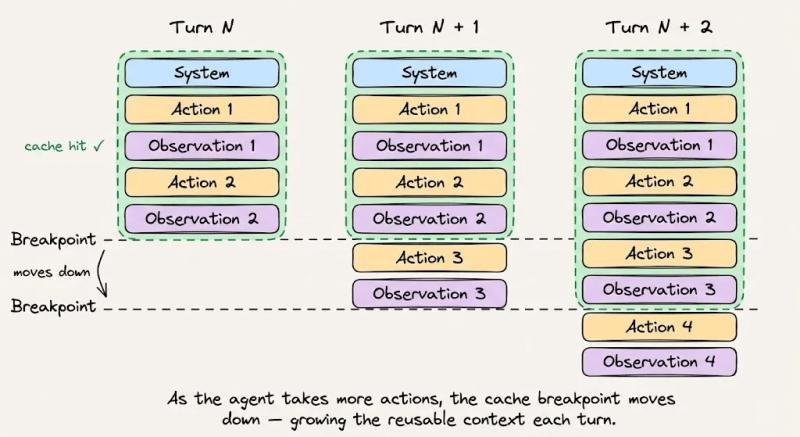
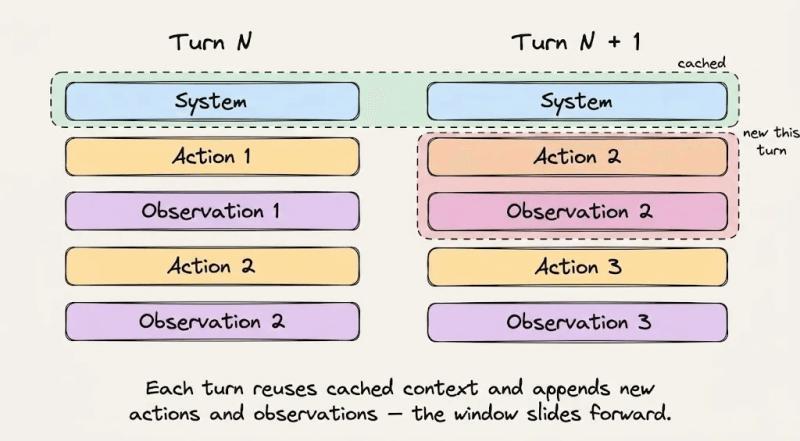
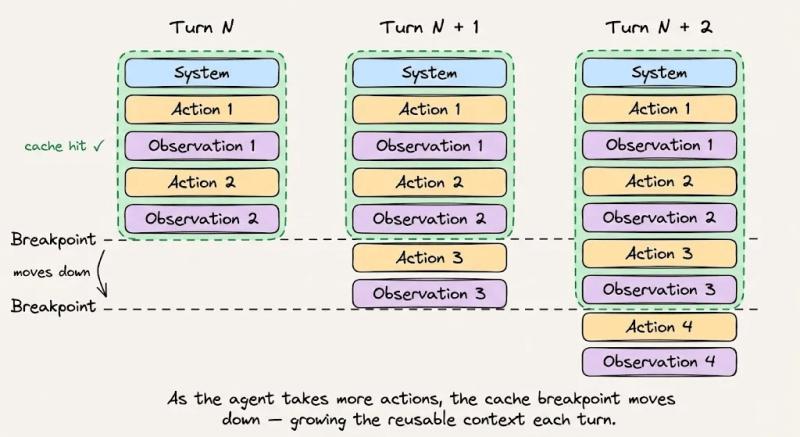
无论你是直接用Claude Code,还是自己从零搭一个代理,这套结构都值得照搬:
- 顶部:系统指令和行为规则,整场会话保持不变。
- 其下:所有工具定义,一次性加载,不在会话中添加或删除。
- 再下:检索到的上下文和参考文档,在会话期间尽量稳定。
- 底部:对话历史、工具输出、终端日志,这是动态后缀。
在Anthropic API里,如果你启用了自动缓存,缓存断点会随着对话自动往后推;如果没开,你就得自己盯着token边界,手动决定“前缀切到哪儿”。边界一旦切错,很可能直接错过缓存。
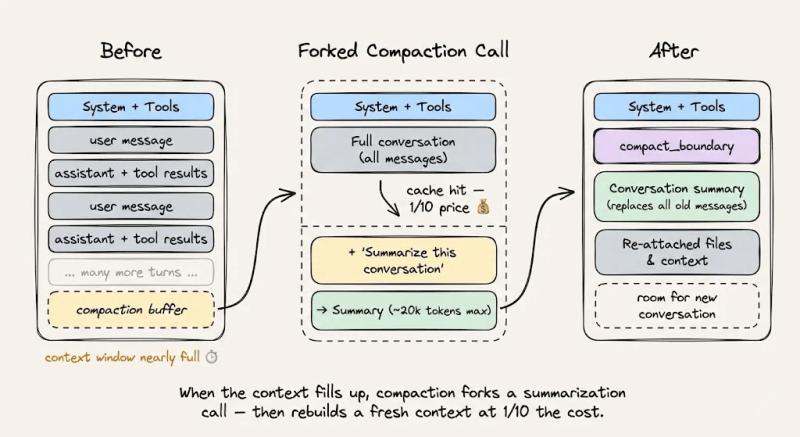
上下文压缩:怎么在不破坏缓存的前提下“瘦身”?
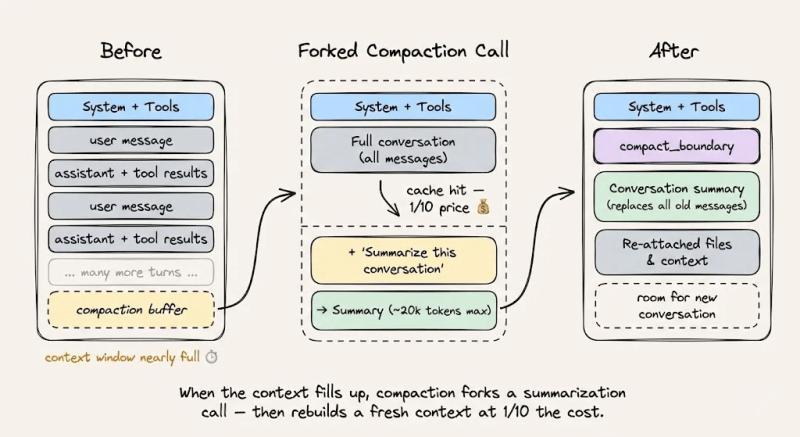
当会话接近上下文上限时,你需要做上下文压缩,但压缩方式本身也会影响缓存命中率。一个“缓存友好”的做法是:
- 保持系统提示、工具定义、已有对话历史不动。
- 通过一条新的用户消息,告诉模型“请把上面的对话压缩成摘要,并在后续只使用摘要”。
- 把压缩后的摘要作为后续对话的一部分追加在动态后缀里,而不是去改前缀。
这样一来,缓存前缀可以被完整复用,唯一新增计费的是那条“压缩指令”和压缩结果本身。对长会话来说,这种“分叉而不改头”的策略,能在不牺牲缓存命中率的前提下,让上下文一直保持可控。
如何判断缓存到底有没有帮你省钱?
要验证缓存是否真的在工作,不要靠感觉,要看API返回里的三个字段:
cache_creation_input_tokens:本次写入缓存的token数量。cache_read_input_tokens:本次从缓存读取的token数量。input_tokens:本次未通过缓存、需要现算的输入token数量。
一个常用的指标是缓存效率:
cache_read_input_tokens / (cache_read_input_tokens + cache_creation_input_tokens)
把这个指标当成“服务正常运行时间”一样去监控:命中率突然掉到某个阈值以下,就说明有人改了系统提示、工具定义,或者序列化顺序被悄悄动过。也有团队会在内部仪表盘上直接展示“每个产品线的缓存命中率+成本曲线”,一旦出现异常波动,就能快速回溯到具体的提示变更。
关键要点与可复用方法
提示缓存不是一个“勾选即用”的小功能,而是一整套需要围绕它来设计的架构纪律。核心思路其实很朴素:
- 把所有静态内容放在提示顶部,并在会话期间保持字节级不变。
- 把所有会变化的内容放在底部,让缓存断点自然向后推进。
- 让基础设施对前缀做哈希,存KV张量,对后续读取给出高额折扣。
真正难的是细节:不要在系统提示里塞时间戳,不要随意调整工具定义的顺序,不要在会话中切换模型,也不要在缓存断点上游修改任何东西。Claude Code用92%的缓存命中率和81%的成本下降,给出了一个“把缓存当一等公民”的样板。如果你在做代理产品,却没有围绕提示缓存来设计,那很多时候是在用最贵的方式跑本可以很便宜的工作流。
这个判断和设计方法,在不同模型、不同云厂商之间都能复用。等你哪天准备重构提示结构,或者要给老板解释“为什么账单突然降了”,不妨把这套思路翻出来对照一下。
常见问题
Q:怎么判断自己的代理适不适合用提示缓存?
A:如果你的代理有多轮对话、长系统提示或大量工具定义,基本就非常适合用提示缓存。原因在于,这类场景的静态前缀占比高、复用频率大,重复计算的浪费最严重。你可以先抓一段真实流量,统计每轮请求中“系统提示+工具定义+项目文档”的token占比,如果长期超过30%,而且这些内容在会话中几乎不变,那启用缓存往往能带来可观的成本下降。建议先在一条流量较大的业务线上灰度开启缓存,并配合监控命中率和成本变化。
Q:缓存命中率低于多少就不划算了?
A:一般来说,当缓存命中率长期低于50–60%时,写入溢价可能会抵消读取折扣,收益变得有限。原因是:每次写入缓存都要按1.25倍计费,如果后续只有一两次读取,摊薄下来并不便宜。你可以按前面提到的公式计算缓存效率,并结合实际单次请求的成本对比“有缓存”和“无缓存”的差异。如果发现命中率偏低,优先排查是否有时间戳、随机ID、工具顺序变化等问题,再考虑是否需要对提示结构做更激进的重构。
Q:会话中途必须加一个新工具,会不会把缓存全毁了?
A:在当前的哈希机制下,会话中途新增或删除工具,确实会让后续请求的前缀与之前完全不同,相当于从零开始重建缓存。原因是工具定义本身属于静态前缀的一部分,只要内容或顺序变了,前缀的token序列就变了。可操作的做法有两个:一是尽量在会话开始前就加载好所有可能用到的工具,通过“启用/禁用标志”控制是否调用;二是把“工具选择逻辑”放在动态后缀里,比如通过一条用户消息告诉模型“从现在起可以使用某某能力”,而不是直接改工具schema。
Q:上下文压缩会不会影响模型效果或缓存收益?
A:上下文压缩做得好,可以在不明显损失效果的前提下,保持缓存收益并延长会话寿命。压缩带来的风险主要有两点:一是摘要质量不佳,导致模型丢失关键信息;二是如果你通过修改前缀来“替换历史”,会直接破坏缓存。建议采用“追加摘要而不改前缀”的策略,把压缩结果作为新消息放在动态后缀中,并在提示里明确告诉模型“以后优先参考摘要”。同时,可以对比压缩前后的任务成功率和平均token消耗,评估压缩策略是否值得长期采用。
Q:如何在团队协作中避免有人无意间破坏缓存结构?
A:比较稳妥的做法是把“提示结构”和“缓存约束”写成显式规范,并在代码层面加上保护。原因在于,很多缓存失效都是由看似无害的小改动引起的,比如在系统提示里加一句“调试信息”或在工具定义里插入一个时间戳。你可以:在CI中加入对系统提示和工具schema的快照比对,防止无意修改;在配置层面禁止会话中途切换模型;在监控里设置缓存命中率告警,一旦异常就回滚最近的提示变更。长期看,这比靠口头约定要可靠得多,也能让新同事更快理解“哪些地方动不得”。
如果你正打算上马一个新代理,或者准备给现有系统做一次成本优化,这些关于提示缓存的细节,往往比多调几个超参更值回票价。留一点空间给试错,但别忽视那些已经被大规模实践验证过的经验。