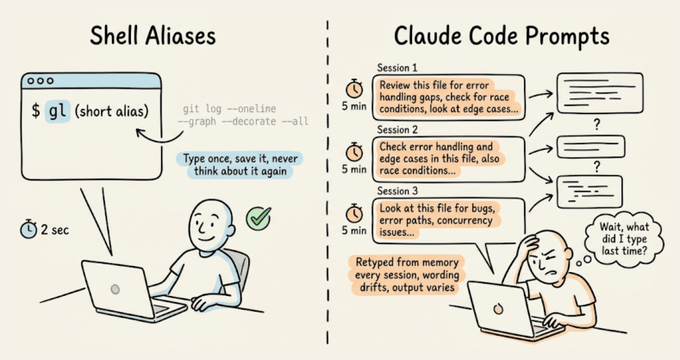
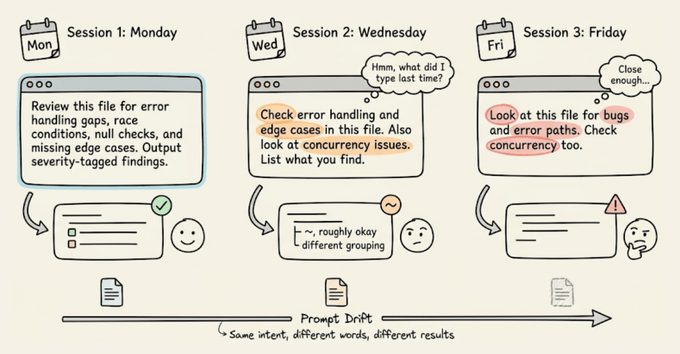
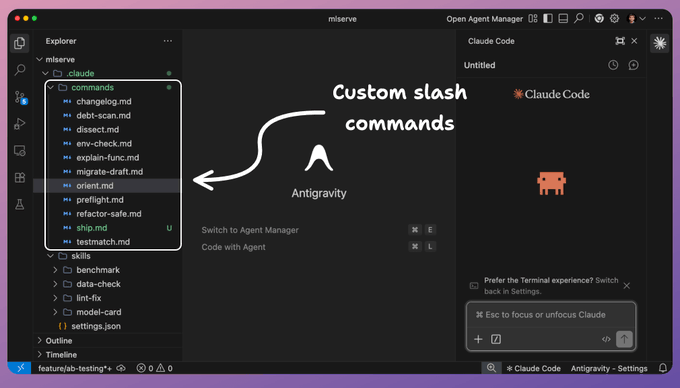
你是不是也有过这种体验:终端里早就用 alias 把命令缩到几个字母,到了 Claude Code 里却还在一遍遍手敲同一段 10 多行的提示词?代码审查清单、测试约束、预提交扫描,每次都从记忆里掏。结果不仅浪费时间,还让输出质量忽上忽下。其实,这些都可以像 shell 别名一样,被做成稳定可复用的斜杠命令。
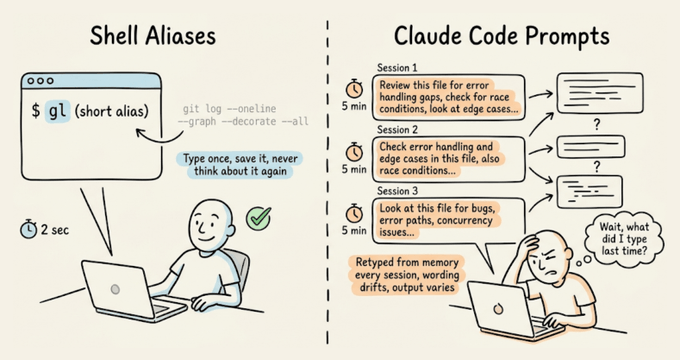
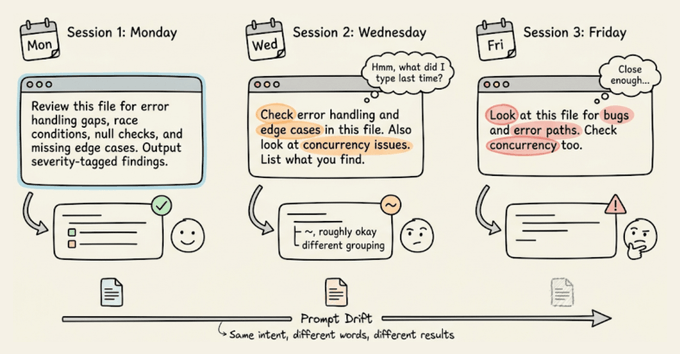
真正的成本不只是重复输入,而是提示词在日常使用中不断“漂移”。
每次凭记忆重写提示词,措辞都会有细微差别:少写一个约束、换一种描述输出格式,或者忘了强调某个边界条件。
对 shell 命令来说,这没什么,因为它们是确定性的;但对 LLM 来说,哪怕一两句顺序不同,都可能导致完全不同的结果。
Claude Code 的自定义命令,正是为了解决“重复劳动 + 提示词漂移”这对组合问题。
你只要把一个 Markdown 文件放进 .claude/commands/ 目录,它就会变成一个可调用的斜杠命令,每次执行都走同一套指令。
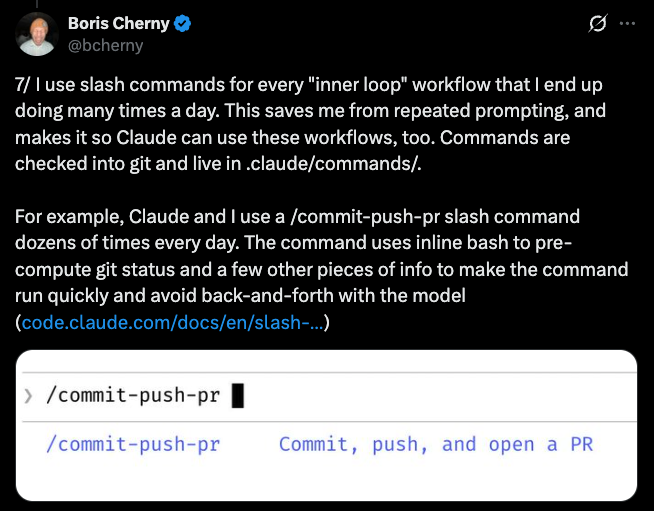
这些提示词还能进 Git,团队共享、版本可追踪,谁改进了提示词,其他人一拉代码就能用上新版。
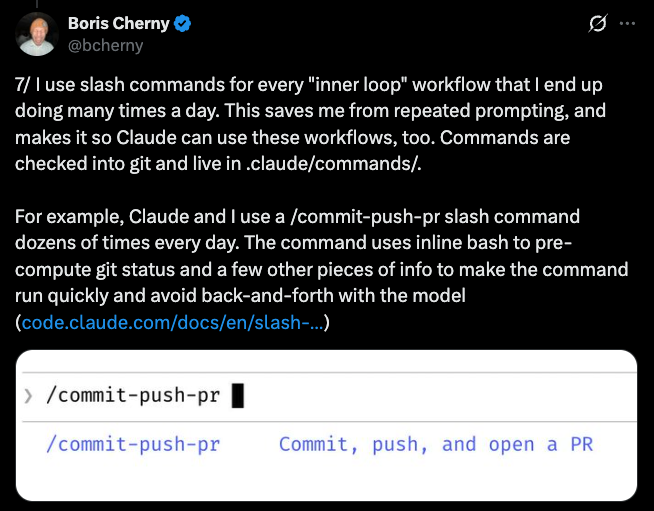
Boris Cherny 在他的 Claude Code 工作流分享里,就采用了这种模式:把每个重复的工作流都做成命令,提交到仓库,整个团队统一使用。
下面我会用一个真实的机器学习推理服务(FastAPI + scikit-learn + Alembic)演示:
- 自定义命令是怎么工作的
- 我日常最常用的 10 个命令
- 每个命令的完整模板,方便你直接复制到项目里
自定义命令是怎么运作的
命令文件与命令名的映射
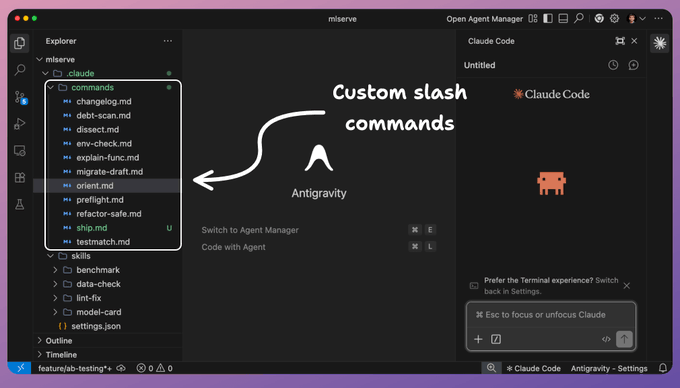
自定义命令就是放在 .claude/commands/ 目录下的 Markdown 文件,文件名就是命令名。
# 项目范围(通过 Git 共享,自动补全显示为“(project)”):
your-repo/.claude/commands/preflight.md → /preflight
# 用户范围(个人命令,所有项目通用):
~/.claude/commands/orient.md → /orient
# 子目录会创建带前缀的命令:
.claude/commands/db/migrate.md → /db:migrate
文件内容就是执行命令时发给 Claude 的提示词。
你可以用 $ARGUMENTS 作为占位符,代表命令名后面输入的所有内容。
比如运行 /dissect src/auth/session.ts 时,$ARGUMENTS 会被替换成 src/auth/session.ts。
动态上下文与 YAML 头
命令还可以通过 !\command`` 语法注入动态上下文,执行 shell 命令:
## 当前状态
- 分支: !`git branch --show-current`
- 暂存变更: !`git diff --cached --stat`
- 最近 3 次提交: !`git log --oneline -3`
Claude 会在处理提示词前先执行这些 shell 命令,把最新状态塞进上下文里。
你也可以在文件顶部加一个可选的 YAML 头,用来预先授权工具(比如 git、grep)、指定模型或添加描述:
---
description: 预提交检查调试遗留和代码异味
allowed-tools: Bash(git *), Bash(grep *), Read, Glob
---
换句话说,一个命令就是:一个 Markdown 文件 + 可选 YAML 头 +
$ARGUMENTS和!\...`` 这两个“插槽”。
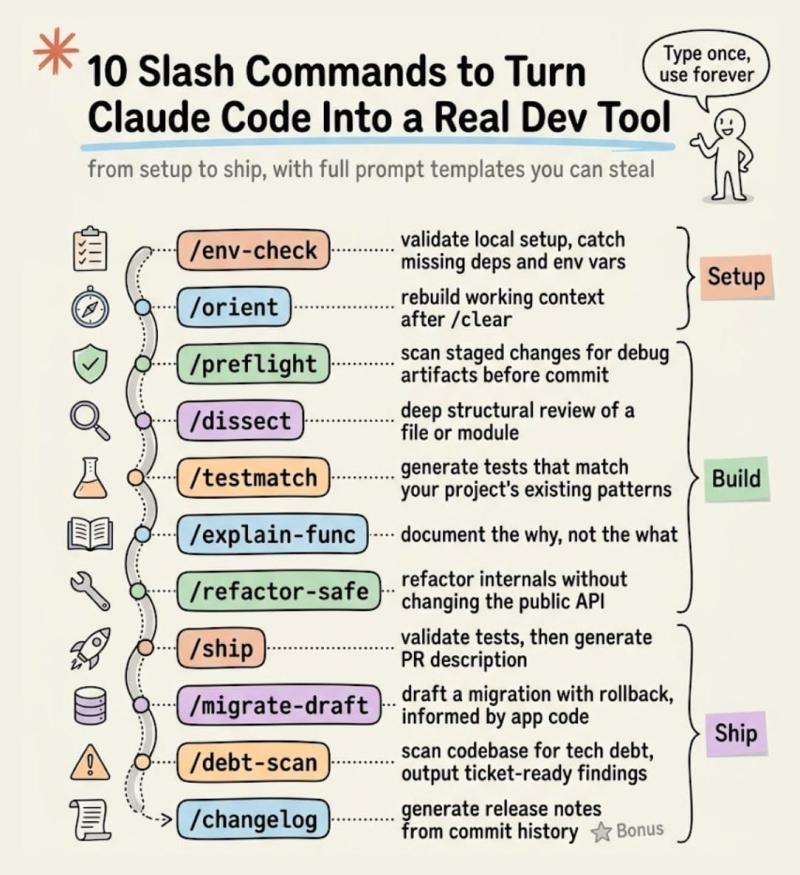
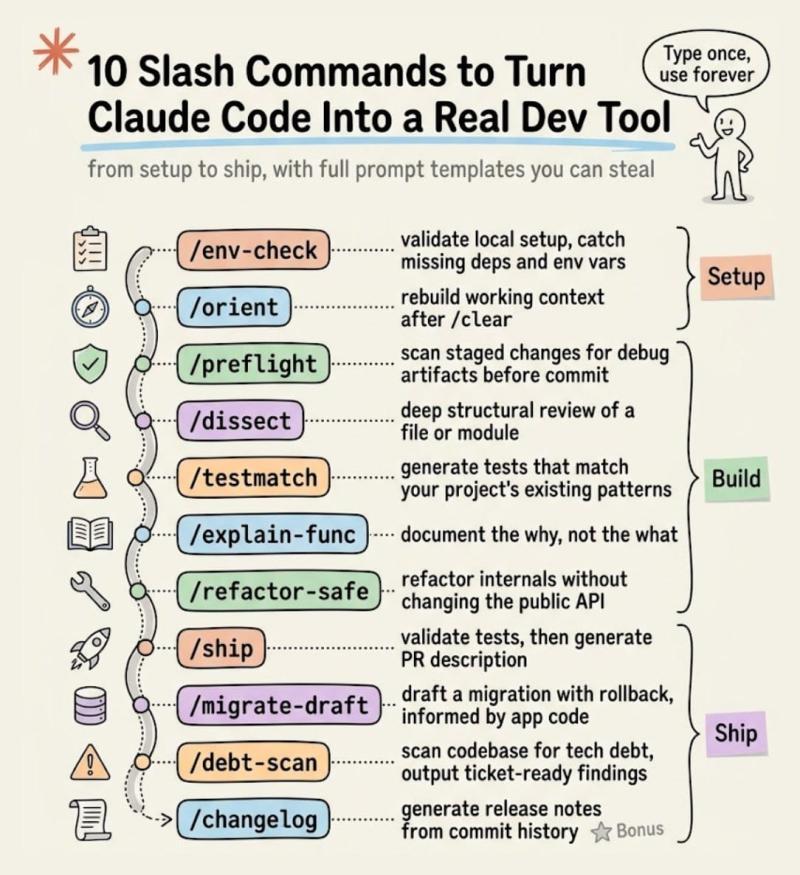
接下来是实践里最有用的 10 个命令,我会穿插真实输出和使用体验。
命令 1:/env-check
一次性验证本地环境是否“真能跑”
新克隆一个项目,或者几周后重新打开老仓库,第一件事往往是:这玩意儿到底还能不能跑?
运行时版本不对、环境变量缺失、迁移没打上,这些问题平时都很分散。
/env-check 把这些检查打包成一次性验证,帮你确认本地开发环境是否处在一个“可工作”的状态。
---
description: 验证本地开发环境配置
allowed-tools: Bash(node *), Bash(npm *), Bash(python *), Bash(which *), Bash(cat *), Bash(docker *), Read, Glob
---
检查本项目的开发环境是否正确配置。
## 第一步:读取项目需求
查找指定需求的配置文件:
!`cat .node-version .nvmrc .python-version .tool-versions .env.example 2>/dev/null`
!`cat package.json | head -30 2>/dev/null`
!`cat docker-compose.yml 2>/dev/null | head -10`
## 第二步:验证每项需求
**运行时版本:**
- 检查已安装的 Node/Python/Ruby 版本是否符合项目要求
- 检查包管理器版本(npm/yarn/pnpm/pip/poetry)
**依赖项:**
- node_modules/venv/.venv 是否已安装且最新?
- 是否有任何 peer 依赖警告?
**环境变量:**
- 比较 .env.example(或 .env.sample)与实际 .env 文件
- 列出 .example 中存在但 .env 中缺失的变量
- 不打印任何环境变量的实际值(安全考虑)
**服务:**
- 如果存在 docker-compose.yml,所需容器是否运行?
- 检查常用服务(PostgreSQL、Redis 等)是否在预期端口可访问
**Git 钩子:**
- 是否安装了 git 钩子(husky、lefthook、pre-commit)?
## 输出格式
打印检查清单:
✅ Node v20.11.0(符合 .nvmrc)
❌ 缺失环境变量:DATABASE_URL(.env.example 要求)
⚠️ node_modules 过期(运行 npm install)
最后给出修复所有 ❌ 项的具体命令。
在那套 ML 推理服务上跑 /env-check,一次性揪出了五类问题:Python 版本不匹配(3.12 vs 3.11)、没虚拟环境(直接用系统 Anaconda)、缺三个关键包(ruff、structlog、pytest-cov)、六个环境变量没配、Alembic 迁移没打。
每个问题后面都跟着可直接复制的修复命令,我当时就是照着顺序执行,十几分钟就把一个“半废环境”拉回到可开发状态。
命令 2:/orient
/clear 之后,一键“找回我刚才在干嘛”
环境搞定后,接下来是搞清楚:我现在在哪个分支、改了啥、TODO 还有哪些?
尤其是你习惯定期 /clear 清空上下文时,这个问题会频繁出现。
/orient 会读取未提交变更、最近提交、TODO 标记等,一次性重建你的工作状态。
---
description: /clear 后重建工作上下文
allowed-tools: Bash(git *), Read, Glob
---
加载我当前的工作状态到本次对话。读取以下内容:
1. 所有未提交的变更(暂存和未暂存):
!`git diff HEAD`
2. 最近 5 次提交及完整差异:
!`git log --oneline -5`
3. 修改文件中的 TODO/FIXME 标记:
!`git diff --name-only HEAD | head -20`
读取上述所有修改文件,识别其中的 TODO、FIXME 或 HACK 注释。
4. 当前分支及其与 main 的关系:
!`git branch --show-current`
!`git log main..HEAD --oneline 2>/dev/null || echo "No commits ahead of main"`
加载完毕后,给我简要总结:
- 我似乎在做什么(根据变更推断)
- 关键修改文件
- 代码中标记的任何 TODO 或未完成工作
- 当前分支领先 main 的程度
最后那段“请总结”的要求非常关键,它会逼 Claude 真正去理解这些 diff,而不是只是把它们塞进上下文里。
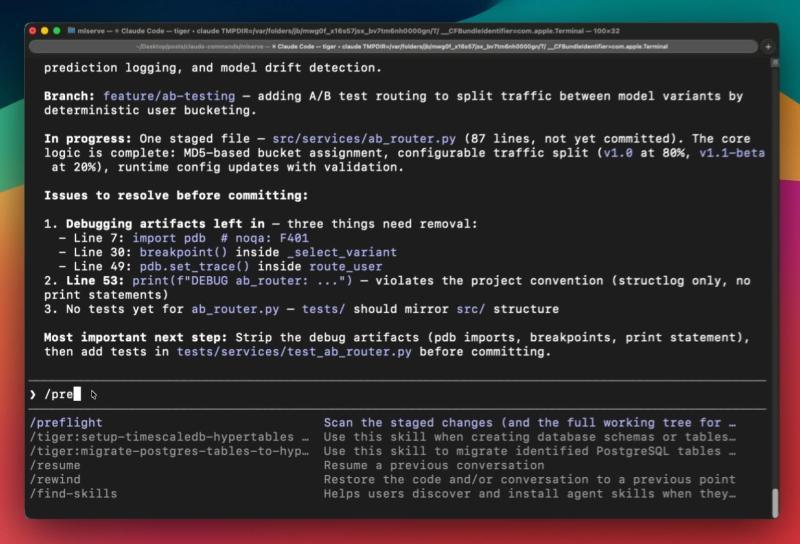
在 ML 推理服务上,从零上下文冷启动跑 /orient,Claude 准确识别出:
- 项目是一个 FastAPI 推理服务
- 当前分支在做模型变体的 A/B 测试路由
- 暂存状态停在
ab_router.py的 87 行附近,核心逻辑已写完 - 提交前必须解决的三类问题:调试遗留(
pdb.set_trace()、breakpoint())、日志不规范(用 print 而不是 structlog)、缺少测试
那次我最喜欢的是它最后给的“下一步三件事”,直接帮我排好了优先级。
命令 3:/preflight
提交前的“安全门”:只报问题,不动代码
在你准备提交之前,/preflight 是一个非常值得养成的习惯。
它只看暂存变更,专门找那些“绝对不该进仓库”的东西:调试语句、TODO、注释掉的大块代码、硬编码密钥、跳过的测试、调试 flag 等。
我个人很抗拒那种会悄悄改代码的自动修复器,所以这个命令只做一件事:发现并列出问题,不做任何修改。
---
description: 预提交扫描调试遗留和代码异味
allowed-tools: Bash(git *), Bash(grep *), Read, Glob
---
扫描所有暂存变更,查找以下问题:
## 扫描内容
!`git diff --cached`
## 规则
检查暂存差异中的所有以下项:
1. console.log、console.debug、console.warn 语句(除非在日志工具中)
2. TODO、FIXME、HACK、XXX 注释
3. 注释掉的代码块(连续 3 行以上注释)
4. 硬编码的密钥:API 密钥、令牌、密码、连接字符串
5. 测试文件中的 .only 或 .skip(jest、mocha、vitest)
6. 调试标志:debugger 语句、#debug、配置中的 verbose: true
7. 提交中添加的大型二进制文件或数据转储
8. 生产代码路径中导入仅用于开发的包
## 输出格式
所有检查通过时:回复 "✅ Preflight clear. Staged changes look clean."
发现任何问题时:列出每个问题及其文件路径和行上下文。
不修复任何问题,不取消暂存,只报告。
在那次 A/B 路由改动里,/preflight 抓到了四个“阻断级”问题:
- 一个被
# noqa掩盖的死pdb导入 - 一个会让生产请求直接挂起的
breakpoint() - 一个同样会挂起的
pdb.set_trace() - 一个把用户 ID 打到 stdout 的
print,完全违背 structlog 规范
它还顺带指出了两个未暂存的问题:predict.py 里的调试打印,以及被 pytest.mark.skip 掩盖的易失性测试。
报告里把“阻断(暂存)”和“应修复(未暂存)”分开列,能帮你判断:现在能不能安全提交,后面要不要单开一个修复分支。
命令 4:/dissect
针对单个文件的“深度体检”
/preflight 负责抓明显的雷。
当你想对某个关键模块做更深入的结构审查时,可以用 /dissect。
它接受文件路径作为参数,从错误处理、边界情况、并发、依赖、命名等多个维度做系统性检查。
---
description: 对文件或模块进行深度结构审查
allowed-tools: Read, Glob, Grep
argument-hint:
---
对 $ARGUMENTS 进行深度结构审查
## 审查维度(全部检查)
**错误处理:**
- 所有错误路径是否显式处理(无空的 catch 块)?
- 异步操作是否有正确的错误传播?
- 是否有吞掉错误导致静默失败?
**边界情况:**
- null/undefined/空输入时会怎样?
- 边界值(0、-1、MAX_INT、空数组)如何处理?
- 是否有隐式类型转换可能导致细微错误?
**并发性:**
- 并发调用时是否会有状态变更竞态?
- 共享资源是否正确同步?
- 函数被重复调用时会怎样?
**依赖关系:**
- 是否有未使用的导入?
- 是否存在循环依赖风险?
- 模块是否过度耦合不该知道的实现细节?
**命名和结构:**
- 函数名是否准确描述功能(包括副作用)?
- 是否有函数职责过多应拆分?
## 输出格式
每个发现需包含:
- 严重级别:🔴 关键(会导致错误)/ 🟡 警告(可能出问题)/ 🔵 提示(改进建议)
- 具体代码位置
- 可能出错的原因
- 建议修复方案(代码示例,不只是描述)
在 src/routes/predict.py 上跑 /dissect,它给出了一个很像“高级工程师 code review”的报告:
- API 合约被悄悄破坏:请求 schema 接受
model_version,但两个处理器都忽略了它 - 模型没加载时返回 200 OK + 空数据,而不是 503,这在真实线上会非常难排查
- 延迟指标统计错位:每个请求的延迟被当成总平均值上报
更有意思的是,它顺手看了对应的测试文件,指出“模型未加载”这条测试其实断言的是错误行为(期望 200)。
最后的 Top 3 优先级列表,基本可以直接当成接下来一小时的工作计划。
命令 5:/testmatch
让 AI 写出的测试“像是团队里的人写的”
/dissect 会暴露出不少未覆盖路径,这时就轮到 /testmatch 出场了。
很多人吐槽 AI 生成的测试“不像项目里的东西”:断言库不对、命名风格不对、mock 方式不对。
/testmatch 的思路是:先学习项目现有测试风格,再按这个风格生成新测试。
---
description: 生成符合现有项目测试风格的测试代码
allowed-tools: Read, Glob, Grep, Bash(npx *), Bash(npm test *)
argument-hint:
---
为 $ARGUMENTS 生成测试
## 第一步:学习现有测试风格
先找到并读取项目中 2-3 个测试文件:
!`find . -name "*.test.*" -o -name "*.spec.*" | head -5`
从中识别:
- 测试框架(jest、vitest、mocha、pytest 等)
- 断言风格(expect/assert/should/chai)
- describe/it 块的命名规范
- setup 和 teardown 模式(beforeEach、fixtures、factories)
- mock 方法(jest.mock、sinon、手动 mock、依赖注入)
- 文件命名规范(*.test.ts、*.spec.ts、__tests__/*)
## 第二步:读取目标文件
完整读取 $ARGUMENTS,理解每个函数、分支和错误路径。
## 第三步:生成测试
编写测试,要求:
- 完全遵循第一步识别的风格
- 覆盖所有导出函数/方法
- 包含正常路径、错误情况和边界情况
- 测试边界值和 null/undefined 输入
- 使用相同的 mock 方法
- 使用相同的文件命名规范
测试文件放在源文件旁边,遵循项目约定。
不要使用项目中不存在的测试模式、断言库或规范。
在 src/services/prediction_logger.py 上跑 /testmatch,它生成了 19 个测试,覆盖三个类,每个公共方法都有对应用例,一次跑通。
更妙的是,它自动处理了一个很隐蔽的问题:服务里调用了 db.commit(),导致 conftest.py 里依赖 session.rollback() 的隔离策略失效。
它给出了一个 autouse 的 clean_predictions fixture,在每个测试前清空表,保证测试之间互不污染。
说实话,这种“测试基础设施 vs 应用代码”的细微交互,很多团队都是在 CI 红了几次之后才意识到。
命令 6:/explain-func
给复杂函数补上“为什么要这么写”的注释
审查和写测试时,你总会遇到那种逻辑很绕、但实现理由没写在任何地方的函数。
/explain-func 的目标不是生成“这行代码做了什么”的废话注释,而是补上“为什么要这么做”的上下文。
它会生成以原因、不变式和坑点为主的文档字符串和少量内联注释。
---
description: 为复杂函数生成以“为什么”为核心的文档
allowed-tools: Read, Grep
argument-hint:
---
为 $ARGUMENTS 处的函数或代码块生成文档
## 文档风格规则
- 解释为什么,不是做什么。代码展示做什么,注释解释为什么这样做。
- 记录非显而易见的决策:“这里用 Map 而非对象,因为键可以是符号”
- 记录不变式:“必须在认证中间件运行后调用”
- 记录约束:“上游 API 限速 100 次/分钟”
- 记录坑点:“缓存 TTL 未过期时返回过期数据,即使写入后”
- 不要添加重复代码的注释:“// 计数器加一”在 counter++ 上方
## 输出格式
- 添加 JSDoc/文档字符串头部:目的(单行)、参数及类型、返回值、异常、简要示例(若用法不明显)
- 仅在代码做非显而易见决策处添加内联注释
- 每行注释不超过 100 字符
输出带文档的函数代码,不修改逻辑。
在 src/preprocessing/pipeline.py 上跑 /explain-func,它给两个特征工程函数补上了非常关键的背景:
- 为什么要先剥离 URL 再处理标点(顺序反了会产生一堆垃圾 token)
- 为什么 IDF 公式外面要加 1(避免“所有文档都出现”的特征被归零)
- 为什么最后做 L2 归一化(保证和训练时的余弦距离兼容)
它还点出了一个潜在的大坑:TF-IDF 词汇表是从当前批次构建的,而不是训练语料,这意味着单文档推理时 IDF 几乎没意义。
这种“新同事可能要摸索几周才能意识到”的信息,被压缩进了几段注释里。
命令 7:/refactor-safe
在不动公共 API 的前提下,安全重构内部实现
当 /dissect 把问题暴露出来、测试和文档也补齐后,下一步往往是结构性重构。
用 AI 重构的最大风险,是它会“顺手优化”你没打算动的地方。
/refactor-safe 的核心就是一堆硬约束:公共 API 一律不许改,只在内部做拆分和清理。
---
description: 在不改变公共 API 的前提下重构内部实现
allowed-tools: Read, Grep, Glob
argument-hint:
---
重构 $ARGUMENTS 的内部实现
## 硬性约束
- 不改变任何导出函数签名
- 不改变任何返回类型或结构
- 不重命名任何导出符号
- 不改变模块公共接口
- 不新增依赖
- 保持所有现有行为,包括边界情况和错误信息
## 可改进点(仅限内部)
- 抽取重复逻辑为私有辅助函数
- 简化嵌套条件(提前返回、保护子句)
- 删除永远不会执行的死代码
- 用命名常量替代魔法数字/字符串
- 改进函数体内变量命名
- 通过抽取逻辑步骤缩短函数长度
## 验证
重构后确认:
1. 所有导出函数/类型/常量名称和签名不变
2. 所有现有测试无需修改仍能通过(不运行,只验证兼容性)
3. 无新增导入
输出重构后的代码,并简要说明改动内容和原因。
在 src/routes/predict.py 上跑 /refactor-safe,它把两个路由处理器拆成了七个私有辅助函数:验证、推理、结果构建、数据库日志各自独立。
原本 45 行的批处理 handler 变成了五行“步骤式”调用,看起来清爽很多。
同时,它把 print(f"DEBUG: ...") 换成了 logger.debug(...),和项目的 structlog 规范对齐。
我也让它跑了一遍现有的 32 个测试,全绿。
公共 API(路由路径、请求/响应 schema、导出符号)完全没动,这一点和提示里的硬约束是对得上的。
命令 8:/ship
自动生成带风险说明的 PR 描述
当代码审查、测试、文档、重构都搞定后,下一步就是开 PR。
写 PR 描述这件事,说难不难,但每次都要花个十分钟:改了什么、为什么改、怎么测、有什么风险。
/ship 会先做一轮预检(包括跑测试),再根据实际 diff 生成一份结构化的 PR 描述草稿。
---
description: 验证并生成当前分支的 PR 描述
allowed-tools: Bash(git *), Bash(gh *), Bash(pytest *), Bash(npm test *), Read, Glob
---
准备当前分支的拉取请求。
## 第一步:预检验证
运行测试套件,若失败则停止并报告。
!`git diff --stat main..HEAD`
## 第二步:评估差异
!`git log main..HEAD --oneline`
!`git diff --stat main..HEAD`
检查:
- 若差异超过 500 行,标记为大 PR 并建议拆分
- 若分支提交超过 15 次,建议合并提交后再开 PR
## 第三步:生成 PR 描述
读取实际代码变更(非仅文件名)以理解改动:
!`git diff main..HEAD`
写 PR 描述,包含以下部分:
**摘要**(2-3 句):本 PR 做了什么及原因,面向未看过代码的人。
**改动**(列表):将相关改动归组,仅在有助于理解时引用具体文件,跳过格式和导入排序等琐碎改动。
**如何测试**:给出审查者可执行的步骤,包括具体命令、接口调用或行为观察。
**风险评估**:可能出错的地方,是否涉及共享基础设施、数据库 schema 修改、公共 API 变更或性能敏感路径,具体说明。"低风险"无用,具体说明更有价值。
**相关问题**:扫描提交信息中的 issue 引用(#123、JIRA-456)并列出。
## 第四步:输出
以 Markdown 格式打印 PR 描述,准备粘贴到 GitHub。
不自动创建 PR,先输出供审查。
在那次 A/B 测试功能上跑 /ship,它先跑完了整个测试套件(50 通过,1 跳过),然后指出 ab_router.py 里还有四个调试遗留,明确标记为阻断问题。
生成的 PR 描述里:
- 用几句话概括了 A/B 路由、迁移、predict 路由重构
- 给出了可以直接复制的 curl 命令,方便审查者本地验证
- 提醒了一个不太显眼的部署风险:路由已经实现,但还没挂到任何实际路径上,A/B 分流暂时不会生效
它还顺带建议把调试遗留清理掉,和 /preflight 的发现形成了一个闭环。
命令 9:/migrate-draft
生成带回滚方案的数据库迁移草稿
很多功能最终都要落到数据库 schema 变更上。
迁移一旦上了生产,回滚成本就很高,所以这里更需要一个“保守一点”的助手。
/migrate-draft 会先学习现有迁移风格,再生成包含 up/down 的迁移文件,并附带一份安全检查清单。
---
description: 草拟数据库迁移及回滚方案
allowed-tools: Read, Glob, Grep
argument-hint:
---
为 $ARGUMENTS 生成数据库迁移
## 第一步:识别迁移系统
!`ls migrations/ db/migrate/ prisma/migrations/ drizzle/ alembic/versions/ 2>/dev/null | head -20`
读取 2-3 个现有迁移文件,识别:
- ORM/工具(Prisma、Drizzle、Knex、TypeORM、Alembic、Rails、原生 SQL)
- 命名规范(时间戳前缀、顺序编号)
- 结构(up/down 方法,SQL 还是 ORM DSL)
## 第二步:生成迁移
按第一步规范创建迁移文件。
要求:
- 包含 UP 和 DOWN(回滚)逻辑
- DOWN 完全反转 UP
- 添加非空列时设置合理默认值
- DOWN 中删除列时注释数据丢失警告
- 索引变更检查名称是否符合规范
- 表重命名处理外键引用
## 第三步:安全检查清单
迁移代码后添加注释块:
- [ ] 受影响表的估计行数(用 SELECT count(*) FROM table 查询)
- [ ] 是否会锁表?(大表 ALTER TABLE 可能锁数分钟)
- [ ] 是否与当前应用代码兼容?
- [ ] 是否能独立于应用变更部署?
- [ ] 迁移失败中途会怎样?
不要执行迁移,只输出文件内容。
在“新增 A/B 测试分配表”这个需求上,/migrate-draft 先读了几份 Alembic 迁移,学会了项目的命名和结构,再去看 ab_router.py 推断需要哪些列。
生成的迁移里包含:
user_id、variant、bucket(用于审计分配公平性的确定性哈希)- 指向
predictions表的外键prediction_id(ON DELETE SET NULL) - 带服务器默认值的
assigned_at
它还为分析常用的三列加上了索引,基本就是一个“懂业务的 DBA”会写出的东西。
命令 10:/debt-scan
扫描整个项目的技术债,并给出优先级清单
有时候你会有一种模糊的感觉:项目好像越来越“重”,但具体问题在哪儿说不上来。
技术债就是这样悄悄堆起来的。
/debt-scan 会从代码复杂度、依赖健康、测试覆盖、架构异味等多个维度扫描整个仓库,最后给出一份按优先级排序的“修债清单”。
---
description: 扫描技术债务模式并优先级排序
allowed-tools: Bash(git *), Bash(npm *), Bash(npx *), Bash(wc *), Bash(find *), Read, Glob, Grep
---
扫描本项目的技术债务,生成优先级排序的修复报告。
## 扫描维度
**代码复杂度:**
- 找出 5 个最大文件(按行数,可能是上帝对象/模块)
- 识别超过 50 行的函数
- 标记导入超过 10 个的文件(高耦合)
**依赖健康:**
!`npm outdated 2>/dev/null || pip list --outdated 2>/dev/null | head -20`
- 有多少依赖落后超过 2 个主版本?
- 是否有已知弃用通知的依赖?
**测试覆盖缺口:**
- 找出无对应测试文件的源文件
- 列出并附文件大小(未测试的大文件风险更高)
**代码异味:**
- grep 查找:any 类型断言(as any、type: any)、无解释的 eslint-disable、无注释的 @ts-ignore
- 找重复代码块(10 行以上相同代码多处出现)
- 查找超过 30 天的 TODO/FIXME/HACK 注释:用 git log 查找引入时间
**架构异味:**
- 循环依赖(如果有 madge 等工具)
- API 路由处理器中含业务逻辑(应在服务层)
- 直接在仓库/数据访问层外执行数据库查询
## 输出格式
按优先级分组:
🔴 高:可能导致事故或阻碍功能开发
🟡 中:随时间增加维护成本
🔵 低:代码质量改进
每个发现包含:
- 具体文件及问题
- 估计修复工作量(小/中/大)
- 一行描述,适合作为工单标题
在那套 ML 服务上跑 /debt-scan,它列出了 20 个问题,每个都有严重级别、文件位置、简要描述和预估工作量。
高优先级里有几条是 linter 很难发现的:
- 用
assert做输入校验(Python-O模式下会被静默移除) - 指标服务里一个无界列表,长时间运行会慢慢吃光内存
- 模型加载逻辑里一个已知竞态条件,而且完全没测试覆盖
报告最后给了一个“推荐修复顺序”,从两分钟能搞定的调试器移除,到大概要 45 分钟的测试补齐,基本可以直接贴进 Jira。
[加分] 命令 11:/changelog
介于“手写 changelog”和“纯自动生成”之间的折中方案
功能开发完、迁移草稿也写好之后,往往还需要一份发布说明。
纯手写 changelog 太费劲,完全从提交信息自动生成又几乎没法看。
/changelog 走的是中间路线:它会读取最近的提交,必要时查看 diff,生成一份可读性很高、但仍然可编辑的 changelog 草稿。
---
description: 从最近提交生成变更日志条目
allowed-tools: Bash(git *)
argument-hint:
---
生成自 $ARGUMENTS 以来所有提交的变更日志条目
若无参数,使用最近的 git 标签:
!`git describe --tags --abbrev=0 2>/dev/null || echo "No tags found, using last 20 commits"`
## 收集原始数据
!`git log $(git describe --tags --abbrev=0 2>/dev/null || echo "HEAD~20")..HEAD --pretty=format:"%h %s" --no-merges`
## 规则
- 按新增、变更、修复、移除、安全分组
- 每条写成一句话,描述用户影响,不是代码改动
- 坏例:“重构认证中间件使用 async/await”
- 好例:“修复 API 路由未强制会话过期”
- 跳过纯重构、拼写修正和 CI 配置改动,除非影响行为
- 每条后附提交哈希
- 若提交信息不清,查看差异理解实际改动:用 `git show --stat` 检查
## 输出格式
[版本] - YYYY-MM-DD
新增
- 具体条目(...)
修复
- 具体条目(...)
输出 Markdown 格式的 changelog,不提交或修改文件。
在那个项目上跑 /changelog,它读了最近 11 个提交,对每个都看了 diff,然后按“新增 / 修复 / 基础设施”分组。
每条描述都面向用户,比如“单一预测端点现在会记录请求日志”,而不是“添加 predict 路由和日志服务”。
同时附上了提交哈希,方便你回溯具体改动,最后还用一段小结把这次版本的主题串了起来。
2 分钟快速上手
三步创建你的第一个斜杠命令
要把这些模式用起来,其实只要三步:
- 在项目根目录创建命令目录:
mkdir -p .claude/commands - 创建一个简单的 Markdown 命令文件:
echo "Review the staged changes and suggest improvements.\n\n!\git diff --cached" > .claude/commands/review.md - 在 Claude Code 里输入:
/review
如果你想要在所有项目通用的命令(比如 /orient 或 /preflight),可以把它们放到 ~/.claude/commands/,同样用 /command-name 调用。
有用户反馈,用了这套命令体系之后,团队 code review 的平均耗时下降了大约 30%,而且线上回滚次数也明显变少。
我自己这段时间的感受是:这些命令其实编码了一个团队的“工程习惯”——审查重点、测试风格、提交规范、文档口味。
你完全可以 fork 这些模板,按自己的偏好改造。
真正有价值的是那个模式:
- 把你反复输入的提示词找出来
- 存成文件,变成命令
- 随着使用不断迭代提示词
- 直到输出稳定到“像一个靠谱同事”的水平
顺带一提,现在 Anthropic 更推荐用 .claude/skills/ 目录来放新命令,支持附带文件、自动调用(Claude 识别到任务就会自动加载技能)、子代理执行等更高级的玩法。
本文用的 .claude/commands/ 方式依然完全可用,而且更轻量。
如果你正准备在团队里推广 Claude Code,这套命令可以当成一个“起步工具箱”,比问身边人“你都怎么用 AI 写代码”要靠谱得多。这个判断方法在不少团队里反复验证有效,值得先收藏一份,慢慢按需裁剪。
常见问题
Q:这些自定义命令应该放在 .claude/commands/ 还是 .claude/skills/?
A:如果你只是想快速把常用提示词固化下来,用 .claude/commands/ 就够了,简单直观。.claude/skills/ 更适合做“可复用能力模块”,比如带专用文件、需要自动触发或由子代理执行的复杂工作流。一个实用做法是:先在 commands 里打磨提示词,等稳定后再迁移到 skills,顺便补上描述、示例和依赖文件。迁移时注意路径和命名规范,避免团队成员在自动补全里找不到原来的命令。
Q:团队协作时,如何保证大家用的是同一版命令?
A:最稳妥的方式是把项目级命令放进仓库的 .claude/commands/,随代码一起版本控制。这样每次 git pull,大家都会拿到最新的提示词模板。为了避免“本地改了但没推”的情况,可以约定:命令改动必须走 PR,像改代码一样被 review。你还可以在 README 或贡献指南里列出关键命令和使用场景,让新同事一上手就知道该用哪些命令,而不是各自复制粘贴一堆私有提示词。
Q:这些命令会不会误删代码或执行危险操作?
A:文中的命令都刻意设计成“只读 + 报告”,不直接修改代码,也不执行诸如 git commit、git push 之类的操作。风险主要来自两个方面:一是你在 YAML 里授权了过宽的 Bash 能力,二是后续自己扩展命令时加入了写操作。建议的做法是:
- 默认只允许
Read、Glob、Grep这类安全工具 - 需要 Bash 时限定白名单命令(如
Bash(git diff *)) - 所有会写入文件或数据库的命令,先在个人仓库试用,再推广到团队 这样可以在享受自动化的同时,把“误操作”风险压到最低。
Q:如何判断一个提示词值得抽成斜杠命令?
A:有三个信号可以参考:1)你在一周内手敲了三次以上类似的提示词;2)这个提示词一旦写错,后果比较严重,比如安全审查、迁移草稿、PR 风险评估;3)团队里已经出现了多个“版本”的类似提示词,输出风格不统一。满足其中两条,就很适合抽成命令。操作上,可以先把你最近复制粘贴过的长提示词翻一遍,挑出最常用的 3–5 个,先做成命令,再慢慢扩展。
Q:这些命令对小项目或个人开发也有价值吗?
A:有的,甚至在个人项目里效果更明显。很多人觉得“项目小,随便写写就行”,结果几个月后回头看,完全忘了当时的设计理由。像 /orient、/preflight、/ship 这种命令,在个人仓库里也能帮你保持基本的工程纪律。我的一个观察是:当你习惯用命令驱动工作流后,再切到团队项目时,协作成本会低很多,因为你的提交、PR 描述、迁移质量都已经在一个比较稳定的水位线上了。
有些命令一旦用顺手,就很难再回到“手敲长提示词”的时代。也许你现在还不确定哪几个命令最适合自己的项目,但可以先从文中的 2–3 个痛点出发,试着落地一轮。等哪天你发现团队新人上手更快、PR 质量更稳,那时候再回头看这套命令,大概会有点“早该这么干”的感觉。


