产品详细介绍
CEBRA 是一套面向神经科学与时间序列分析的机器学习方法与工具集,用于将高维时间序列(尤其是神经活动与行为数据)压缩到低维潜在空间,从而揭示数据中原本难以观察的结构与规律。它特别擅长处理同时记录的行为数据与神经数据,可在多种实验范式和物种中实现稳定、可解释的嵌入与解码。
核心能力包括:
-
非线性时间序列降维与嵌入
CEBRA 通过对比学习等技术,将高维神经信号映射到低维潜在空间(embedding),在保留关键动态结构的同时大幅压缩数据维度。相比传统线性方法(如 PCA),CEBRA 能捕捉复杂、非线性的神经—行为关系。 -
联合神经与行为数据建模
CEBRA 可以同时利用神经记录(如钙成像、Neuropixels 电生理)与行为标签(如位置、运动方向、视觉刺激特征)进行训练:- 监督 / 假设驱动模式(CEBRA-Behavior):使用行为标签或外部变量作为“锚点”,学习与行为高度对齐的潜在空间,用于解码位置、轨迹或刺激类别等;
- 自监督 / 发现驱动模式:在无显式标签的情况下,仅依赖时间结构与对比学习,自动发现神经活动中的隐含结构,适合探索性分析与新假设生成。
-
跨会话与跨模态一致性
CEBRA 设计强调潜在空间的一致性:- 支持单次或多次实验会话的联合建模;
- 可在不同记录方式之间(如 2-photon 钙成像与 Neuropixels 电极记录)学习到对齐的潜在空间;
- 一致性本身可作为度量,用于比较不同条件、动物或实验范式下的神经表征差异。
-
高精度神经解码与重建
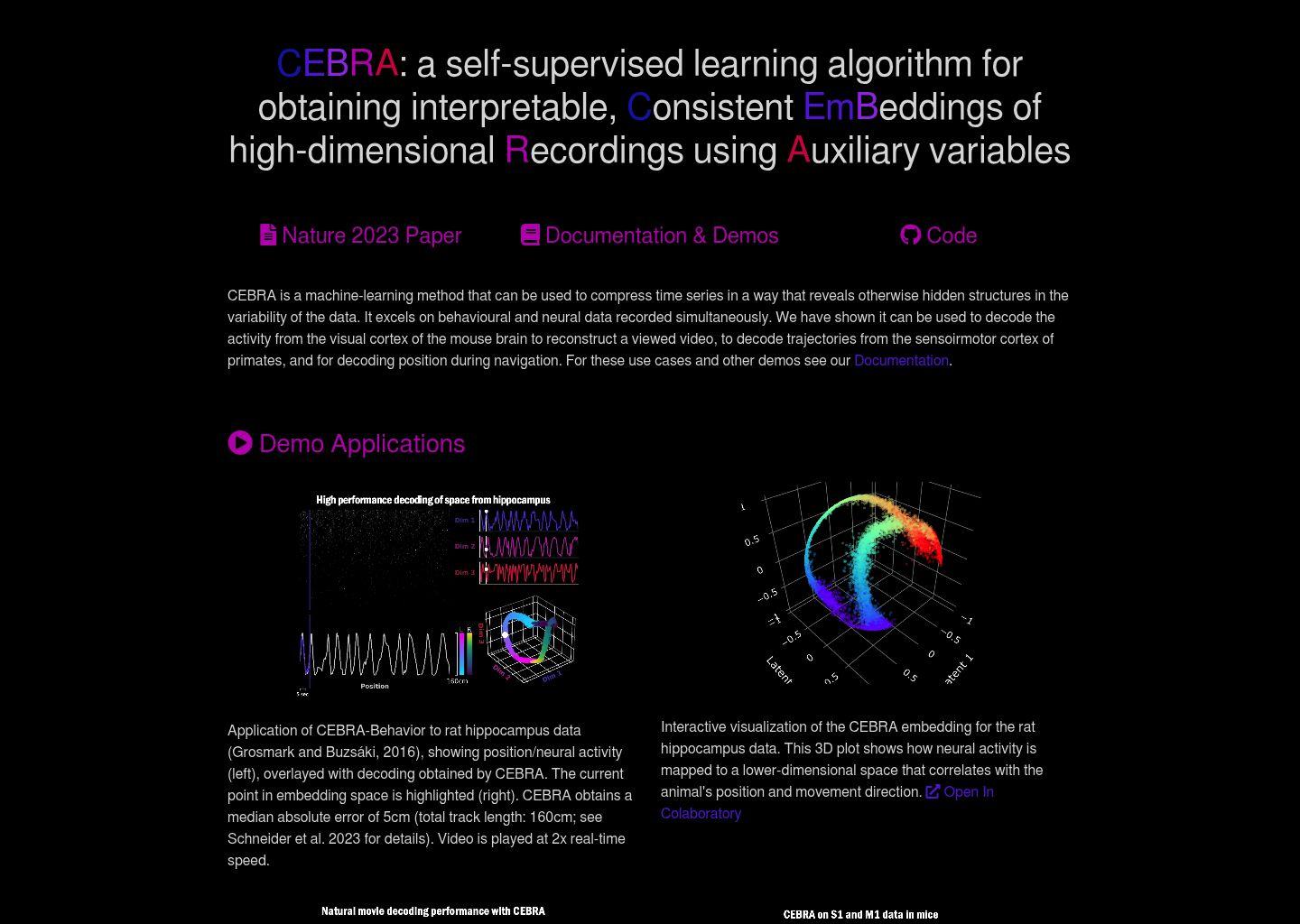
在多个公开数据集上,CEBRA 展示了高性能解码能力:- 空间位置解码:在大鼠海马数据上,利用 CEBRA-Behavior 嵌入解码动物在跑道上的位置,达到约 5cm 的中位绝对误差(总轨道长度约 160cm);
- 运动轨迹解码:在灵长类感觉运动皮层数据中,利用嵌入空间重建手部或身体运动轨迹;
- 视觉刺激重建:在小鼠初级视觉皮层数据中,结合视觉帧特征(如 DINO 特征)作为标签,通过 CEBRA 嵌入和 kNN 解码器,实现对观看视频内容的快速、高精度重建。
-
广泛适用的数据类型与任务
CEBRA 已在多种数据与任务上验证:- 钙成像(2-photon)与 Neuropixels 电生理记录;
- 感觉任务(视觉、体感)与运动任务(导航、到达运动等);
- 简单行为(线性跑道)到复杂自然行为(自由探索、自然视觉刺激);
- 多物种(如小鼠、大鼠、灵长类等)。
-
研究与应用拓展
- 已在 Nature、ICML、NeurIPS、ICLR 等高水平期刊与会议中被广泛引用,影响领域包括神经解码、脑机接口、计算神经科学与时间序列机器学习;
- 提供扩展版本,可对时间序列进行归因分析(attribution maps),帮助理解哪些时间片段或特征对解码结果贡献最大;
- EPFL 已就“时间序列数据降维及其嵌入应用”提交专利,如需非学术/商业使用,建议联系 EPFL 技术转移办公室确认授权。
-
开源实现与生态
- 官方实现已在 GitHub 开源,便于研究者直接使用或二次开发;
- 提供文档、示例与 Colab 演示,涵盖视觉皮层解码、海马位置解码、感觉运动皮层轨迹解码等典型案例;
- 可通过关注项目社交媒体账号获取更新与新版本发布信息。
简单使用教程
以下为基于官方实现的一般性使用流程示意,具体命令与 API 以 GitHub 文档为准。
-
环境准备与安装
- 确保已安装 Python(建议 3.x)及常用科学计算库(如 PyTorch、NumPy 等);
- 从 GitHub 克隆 CEBRA 仓库:
- 使用
git clone下载代码; - 或在本地/Colab 中直接通过
pip安装(若提供 PyPI 包);
- 使用
- 按仓库 README 安装依赖(如
pip install -r requirements.txt)。
-
准备数据
- 神经数据:整理为时间 × 神经元(或通道)的矩阵或相应张量格式;
- 行为/标签数据(可选):
- 位置、速度、运动方向等连续变量;
- 视觉帧特征(如预先提取的 DINO 特征)、任务条件或类别标签;
- 确保神经数据与行为数据在时间上对齐(采样率、时间戳一致或可插值对齐)。
-
选择训练模式
- 若有明确行为标签或外部变量:
- 选择 CEBRA-Behavior(监督/半监督) 模式,目标是学习与行为高度对齐的潜在空间,用于解码或假设检验;
- 若无标签或希望进行探索性分析:
- 选择 自监督/无标签模式,仅依赖时间结构与对比学习,自动发现神经活动中的隐含模式。
- 若有明确行为标签或外部变量:
-
配置模型与训练
- 在配置文件或脚本中设置:
- 嵌入维度(如 2D、3D 或更高维度);
- 时间窗长度、步长等时间序列切片参数;
- 批大小、学习率、训练轮数等优化参数;
- 对比学习相关超参数(如温度系数、负样本策略等,若在接口中暴露)。
- 调用 CEBRA 提供的训练接口,将神经数据与(可选的)行为标签输入模型,开始训练:
- 可在训练过程中监控损失、嵌入可视化或解码性能,以判断收敛情况;
- 对多会话数据,可选择联合训练或对齐训练策略。
- 在配置文件或脚本中设置:
-
生成潜在嵌入与可视化
- 使用训练好的 CEBRA 模型,对神经时间序列进行前向推理,得到每个时间点对应的潜在向量;
- 将 2D/3D 嵌入与行为变量(如位置、方向、速度)叠加可视化:
- 观察轨迹是否与真实行为轨迹对齐;
- 检查不同条件或刺激在嵌入空间中的分布与分离度;
- 对于海马或导航任务,可直接在嵌入空间中查看位置环路或路径结构。
-
解码与下游分析
- 使用简单解码器(如 kNN、线性回归、分类器)在 CEBRA 嵌入上进行:
- 位置解码(导航任务);
- 运动轨迹或速度解码(感觉运动皮层);
- 视觉帧或类别解码(视觉皮层);
- 评估解码误差(如位置误差、分类准确率)以量化模型性能;
- 对比不同条件、会话或动物的嵌入一致性,探索神经表征的稳定性与差异。
- 使用简单解码器(如 kNN、线性回归、分类器)在 CEBRA 嵌入上进行:
-
进阶:归因与解释(可选)
- 若使用扩展版本的 CEBRA,可生成时间序列归因图(attribution maps):
- 分析哪些时间片段或神经元对特定解码结果贡献最大;
- 帮助解释模型如何利用神经活动模式进行行为或刺激解码。
- 若使用扩展版本的 CEBRA,可生成时间序列归因图(attribution maps):
-
部署与合作建议
- 在学术研究中,可直接基于开源实现进行分析,并在论文中引用相关 CEBRA 文献;
- 若计划在非学术或商业场景中使用(如产品化脑机接口、商业数据分析平台等),建议:
- 先阅读官网关于专利与授权的说明;
- 联系 EPFL 技术转移办公室或项目团队,确认许可与合作方式。