 AI资讯
AI资讯Meta推出Muse Spark 1.1,加入激烈的AI编程竞争
Meta于周四公开发布了新版Muse Spark,这是一款多模态AI模型,专为智能编程设计,旨在与OpenAI和Anthropic等公司推出的类似产品竞争。 Spark 1.1的首个版本于今年四月发布,具备多步推理能力,能够处理复杂流程,管理数字化工作流,并在企业系统中部署新功能,Meta公司表示。 虽然Meta在这方面稍显落后,Anthropic和OpenAI早已推出类似模型,但这并不意味着Me
按标签聚合查看文章内容。
AI资讯Meta于周四公开发布了新版Muse Spark,这是一款多模态AI模型,专为智能编程设计,旨在与OpenAI和Anthropic等公司推出的类似产品竞争。 Spark 1.1的首个版本于今年四月发布,具备多步推理能力,能够处理复杂流程,管理数字化工作流,并在企业系统中部署新功能,Meta公司表示。 虽然Meta在这方面稍显落后,Anthropic和OpenAI早已推出类似模型,但这并不意味着Me
 AI资讯
AI资讯阿里巴巴云发布了集视觉与语言功能于一体的多模态AI代理Qwen3.7-Plus,支持多种交互方式,提升编码和生产力工作流程能力。
 AI资讯
AI资讯本文深入解析了Fable 5模型的关键特性与应用技巧,同时汇总了近期AI领域的重要进展,包括腾讯Hy3开源模型发布、Anthropic的工作空间研究及多模态世界模型演示。
 AI资讯
AI资讯微软AI研究实验室于周四宣布推出三款基础AI模型,分别支持文本、语音和图像生成。这一发布标志着微软在构建多模态AI模型体系上的持续努力,旨在与其他AI实验室竞争,尽管微软仍与OpenAI保持合作关系。 其中,MAI-Transcribe-1支持25种语言的语音转文本,速度是微软Azure Fast的2.5倍。MAI-Voice-1是一款音频生成模型,能够在一秒内生成60秒的音频,并支持用户定制个性
 AI资讯
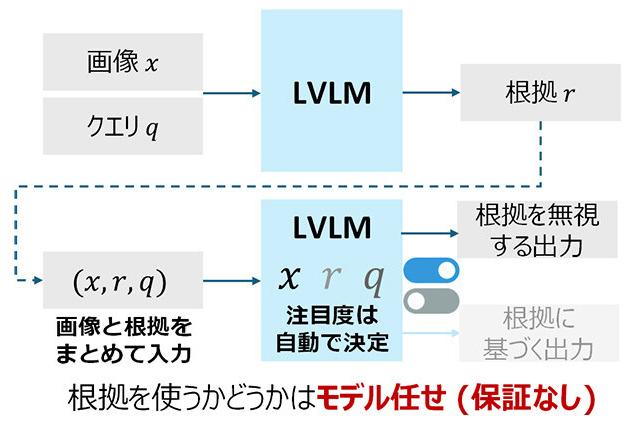
AI资讯日本NTT开发了通过理论框架增强多模态AI模型推理可信度的“根拠强化解码”技术,解决了视觉语言模型推理中根拠与结果不一致的问题。
 AI资讯
AI资讯智能手机和电脑虽然可以使用“AI”,但大多数情况下,这只是一个“入口”。实际的处理是在互联网另一端的数据中心中的大型计算机上完成的,因为AI需要大量的内存和计算能力。 然而,最近这种常识开始发生变化。虽然在游戏电脑上运行本地AI的尝试早已有之,但现在终于出现了“在智能手机上运行本地AI”的趋势。 这一变化的契机之一是日本国家谷歌公开的“Gemma4”。该AI核心模型采用了允许商业使用的Apache
 AI资讯
AI资讯多模态AI能够综合处理文字、图像、音频和视频等多种信息形式,推动AI从单纯的文本生成工具向多信息融合处理工具转变。
 AI资讯
AI资讯NVIDIA发布了面向AR眼镜和XR设备的多模态AI代理开发框架,支持开发者构建智能交互应用。
 AI资讯
AI资讯美国Meta公司于5月12日在X(前身为Twitter)宣布,为其AI助手“Meta AI”引入了“Meta AI语音对话”功能。此次更新搭载了支持多模态输入的AI模型“Muse Spark”,不仅支持文本输入,还能处理语音等多种输入方式。 通过“Meta AI语音对话”,用户可以与Meta AI进行更加自然的交流。除了传统的一问一答模式外,用户还能在对话中随时打断、切换话题,甚至切换语言,极大提
 AI资讯
AI资讯Thinking Machines团队发布了全新交互模型TML-Interaction-Small,凭借2760亿参数和12亿活跃参数,显著提升了实时语音模型的性能,开创了人机协作的新范式。
 AI写作
AI写作InkFox AI 是一款支持文本、图片、音频等多模态的智能创作与自动化平台,集成 AI 对话、文案生成、图片生成、工作流编排与团队协作,帮助个人与企业高效完成内容创作和业务流程自动化。
 AI资讯
AI资讯本文分享了OpenAI研究员Aidan McLaughlin关于提升对大型语言模型(LLMs)期望值的思考,以及近期AI领域的热点动态和技术进展。