99% 做 Agent 的人都在疯狂加记忆,却没发现:记得越多,Agent 反而越糊涂。你可能也遇到过,明明把所有文档都塞进向量库,问个关键问题,它要么答非所问,要么一本正经地胡说八道。问题不在模型“太笨”,而在我们给它的记忆结构,天生就不适合推理。
据一些团队内部评估数据,单纯堆大上下文后,长链路问题的错误率不降反升,开发者却常误以为是模型本身能力不够。
真正的关键是:Agent 的“认知形状”,会被你选的存储方式强行塑形。只用向量库,它就只会“凭感觉”找相似;没有关系结构,它就很难跨多步把事实串起来。要让 Agent 真正“会想”,记忆必须分层设计,而不是一股脑丢进一个库里。
一、为什么“记得越多,知道越少”?
1. Agent 记忆会长成它的存储形状
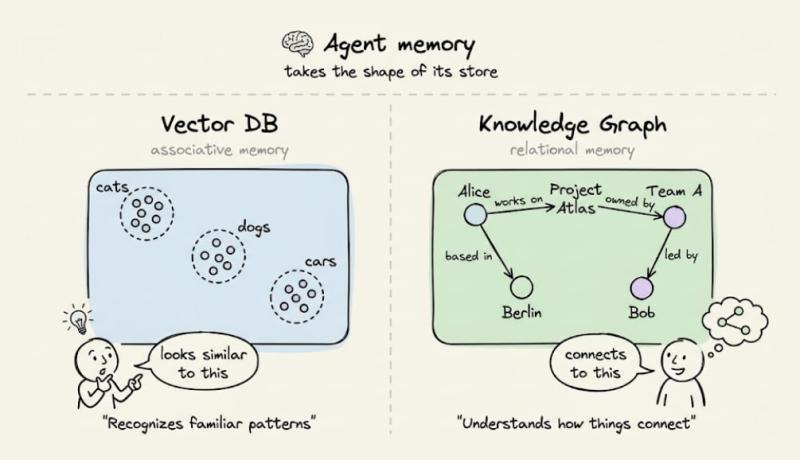
很多人以为,记忆就是一个大仓库,能放越多越好,查得越快越好。可对 Agent 来说,记忆更像大脑里的不同区域:有的负责联想,有的负责关系,有的负责时间和来源。现在主流做法,是把所有东西都塞进向量数据库,结果 Agent 的“思维方式”就被限制成了:只会按相似度去找东西。
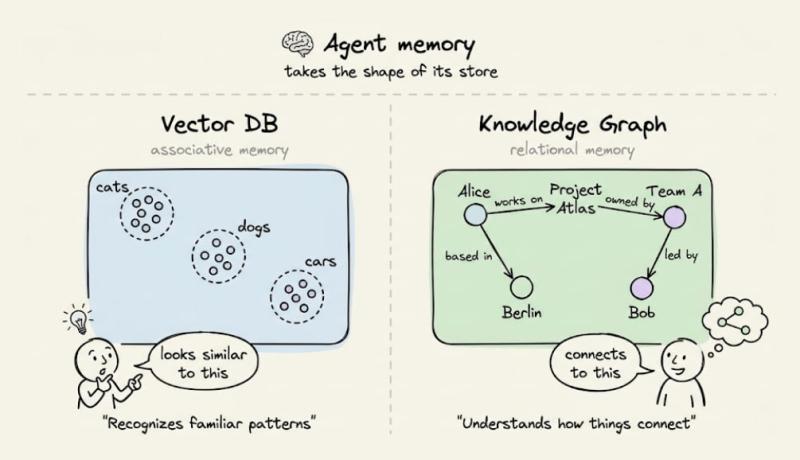
- 向量库给 Agent 的,是“联想记忆”:看到一个问题,能找到语义上相似的片段。
- 图数据库给 Agent 的,是“关系记忆”:谁和谁有关,什么依赖什么,能走多跳路径。
现实里,大多数 Agent 只用前者,几乎完全忽略后者。于是,一旦问题需要跨两三步推理,它就开始“瞎补空白”。
2. 一个简单例子:为什么关键事实总被漏掉
想象你做了一个学习助手,它在向量库里存了关于学生 Mark 的三条事实:
- Mark 在 10 年级。
- 10 年级的期末考试在 3 月举行。
- 图书馆会在期末考试前两周关闭。
有一天,Mark 问它:“下周图书馆还开门吗?”
向量检索会怎么做?它会根据“Mark”和“图书馆”这两个关键词,在嵌入空间里找最相似的内容。很大概率,它会取回:
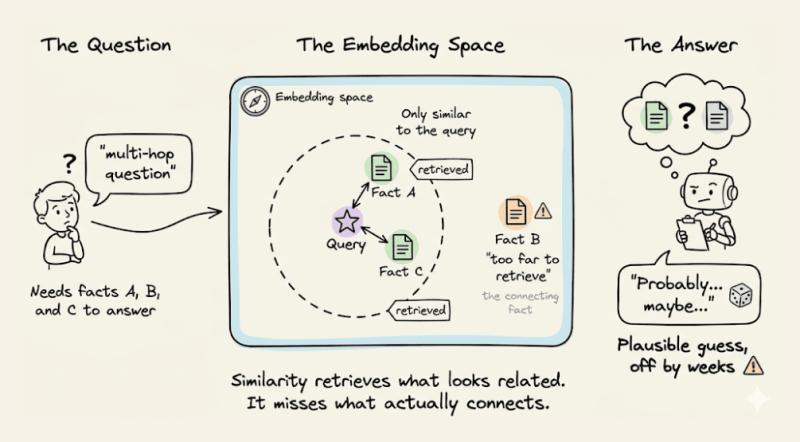
- “Mark 在 10 年级。”(因为提到了 Mark)
- “图书馆会在期末考试前两周关闭。”(因为提到了图书馆)
中间那句“10 年级的期末考试在 3 月举行”,既没提 Mark,也没提图书馆,于是被直接丢在一边。它在嵌入空间里离当前查询太远,进不了 top-k 的检索结果。
结果就是:
- Agent 要么用不完整的信息,给出一个模棱两可的回答;
- 要么干脆“脑补”一个听起来合理、但可能差几周的答案。
这并不是极端例子,而是现实查询的常态。有用户反馈,在企业知识库问答中,只要问题涉及两跳以上关系,单纯相似度检索的错误率会明显飙升。
任何需要跨两步以上推理的问题,本质上都超出了“只靠相似度”能处理的范围。这也是很多人感觉“模型会瞎编”的根源之一。
二、光加大上下文窗口,为什么救不了你?
1. “Lost in the middle”:信息越多,越容易被淹没
很多团队的直觉是:那就多取一点上下文,把所有可能相关的内容都塞给模型。理论上听起来没毛病,实践里却踩坑无数。因为当上下文变得很长时,模型对中间部分的关注度会明显下降,这就是常说的“lost in the middle”问题。
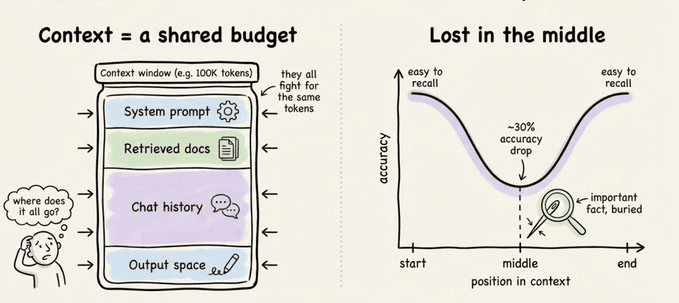
有公开基准显示,当关键事实被放在长上下文的中间位置时,模型回答准确率会下降 30% 以上。也就是说,你辛辛苦苦把信息都喂进去,模型却偏偏忽略了最重要的那一句。说实话,这种“我都给你了你还看不见”的挫败感,很多人应该都体验过。
更大的上下文窗口,只是给了模型更多“错过重点”的空间。它解决的是“装不下”的问题,却没有解决“怎么找重点”的问题。
2. 真正的解法:把记忆拆成三层
如果想从根上解决这个问题,需要换一个视角:别再把记忆当成一个单一的存储,而是拆成三个互补的层,每一层只干自己最擅长的事。
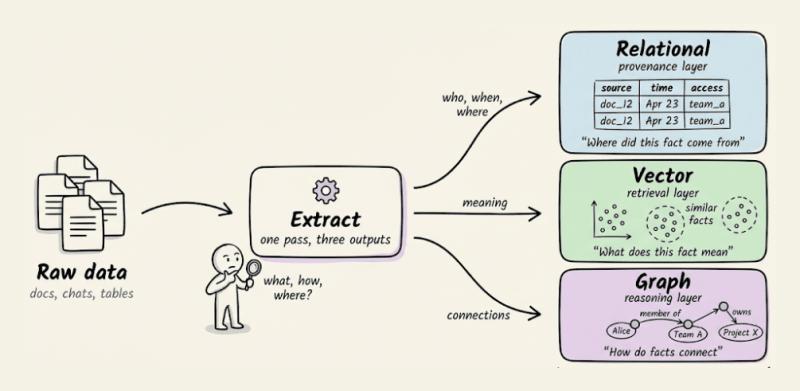
- 关系层(Relational):记录一个事实从哪来、什么时候写入、谁能访问——也就是“溯源层”。
- 向量层(Vector):记录一个事实“在说什么”、语义上和什么相似——也就是“检索层”。
- 图层(Graph):记录事实之间怎么连接、什么依赖什么、谁和谁有关——也就是“推理层”。
三者缺一不可:
- 只有向量库:有相似度,没有结构关系,跨多跳就会断链。
- 只有图:有关系,没有语义检索,找入口都难。
- 只有关系型库:能追踪来源,却几乎没法自动推理。
我自己的观察是,很多团队在做企业 Agent 时,只在“检索层”下功夫,结果一到复杂业务逻辑,就不得不在应用层手写一堆 if-else 来补救。
三、Cognee:三层记忆在开源项目里的落地
1. ECL 管道:一次写入,三库同步
如果你想看这种三层记忆在真实系统里的样子,可以去翻一下开源项目 Cognee。它用的是一个 ECL 流程:Extract(抽取)、Cognify(认知化)、Load(写入)。
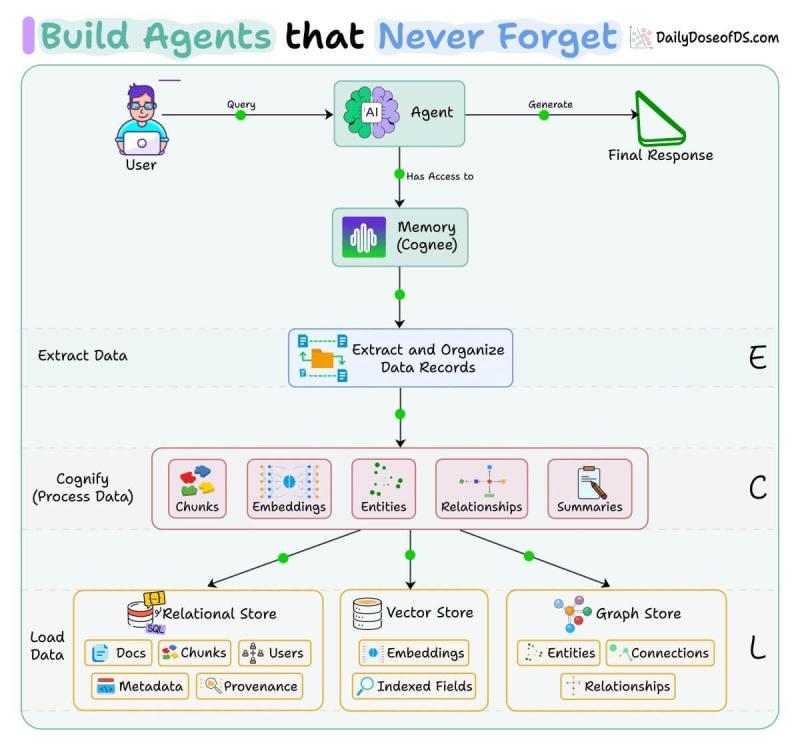
整个流程的关键点在于:
- 在一次索引过程中,同时生成向量、图边和关系元数据;
- 三种存储在写入时就对齐,而不是事后再“硬拼”在一起;
- 新数据到来时,三层一起增量更新,避免状态漂移。
我之前自己试着用 Cognee 做了个小型知识助手,把公司内部文档、会议纪要都丢进去。很直观的感受是:当问题需要跨文档、跨时间线推理时,它比只用向量库的版本稳定太多,幻觉明显减少。不过这也可能和我数据规模不算大有关,我也不太确定这个结论在超大规模下是不是同样成立。
2. 两个关键差异:实体合并与本地优先
在三层记忆架构之上,Cognee 还有两个比较实用的设计,值得单独拎出来说说。
(1)更聪明的实体消歧
你可以给 Cognee 提供一个“领域词汇表”,里面写清楚哪些词其实指的是同一个东西。系统会在索引阶段自动把这些重复提及合并成一个规范节点。
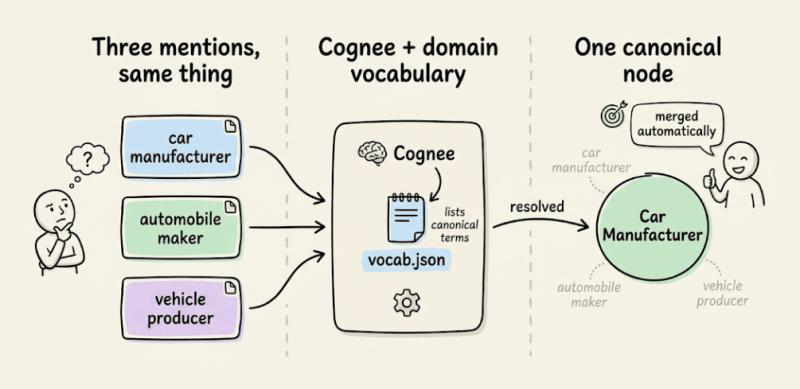
比如:
- “car manufacturer”
- “automobile maker”
- “vehicle producer”
在很多系统里,会被当成三个不同的节点,导致图结构又碎又乱。Cognee 会把它们折叠成一个“汽车制造商”的规范节点,所有关系都挂在这一个点上。这样一来,Agent 在图上走路时,不会被一堆同义词绕晕。
(2)本地优先的默认栈
Cognee 的默认部署方式,是一条命令 pip install 就能在本地跑起来,所有数据都留在本机。这一点在现在数据合规越来越严格的环境下,挺关键的。有团队反馈,用它做内部知识助手时,安全团队的阻力会小很多。
等到你要上生产环境,可以无缝切换到 Postgres 和 Neo4j 这类成熟数据库,API 不用改。这种“先本地玩爽,再平滑上云”的路径,对小团队和个人开发者都比较友好。
四、可直接复用的三层记忆设计思路
1. 判断你的 Agent 是否需要图层的三个信号
如果你在纠结要不要上图数据库,可以用这三个问题自测一下:
- 你的问题是否经常需要“先 A 再 B 再 C”这种多跳推理?
- 你的知识是否天然是网络状的(人-项目-文档-时间线)?
- 你是否经常需要回答“谁依赖谁”“改了这里会影响哪里”这类问题?
只要有两条以上回答是“是”,图层基本就是刚需。否则,你会在应用层写出一大坨难以维护的业务逻辑,去硬编码这些关系。
2. 落地时可以遵循的一个简单流程
可以参考下面这个简化版步骤,把三层记忆慢慢搭起来:
- 先用向量库把“检索层”搭好,保证基础问答可用;
- 再梳理出领域里的关键实体和关系,设计最小可用的图结构;
- 用类似 ECL 的流程,在索引时同时写入向量和图;
- 加一层关系型存储,专门记录来源、时间、权限等元数据;
- 在 Agent 调用链里,显式区分“检索阶段”和“图推理阶段”。
有用户反馈,用这种方式改造后,跨文档、多跳问题的准确率有肉眼可见的提升,幻觉率也更可控。当然,工程复杂度会上一个台阶,这点需要提前预期。
五、为什么这套方法值得你收藏
如果你正在做 Agent 产品,或者打算把 LLM 接入到复杂业务里,这种“三层记忆”的思路,会比问身边人“用哪个向量库好”有用得多。它不是某个库的广告,而是一种被多家顶级 AI 实验室反复验证过的架构习惯。
真正拉开差距的,不是你选了哪个模型,而是你让模型“记住”和“连接”世界的方式。
等你哪天发现,自己的 Agent 在多跳问题上稳定输出靠谱答案,你会庆幸当初没有只停留在“加大上下文窗口”这一层。把这套判断和设计方法收起来,哪怕暂时用不上,等项目复杂度上来时,它会帮你少走很多弯路。
常见问题
Q:我现在只用向量数据库,什么时候必须引入图数据库?
A:当你的问题开始频繁涉及多跳推理(比如“谁负责这个项目里某个子模块”)时,就该考虑引入图数据库。原因在于,向量检索擅长找“相似内容”,却不擅长沿着“谁关联谁”的路径一步步往下走。可操作建议是:先从最关键的 3~5 类实体和关系入手,搭一个最小图结构,把现有向量检索的结果作为图查询的入口,而不是一次性重构全部系统。
Q:上下文窗口已经很大了,为什么 Agent 还是经常漏掉关键信息?
A:窗口变大,只是让模型“看得到”更多内容,但不代表它“抓得住”重点。模型在处理长上下文时,往往对中间部分的注意力下降,这就是“lost in the middle”现象。建议你在检索阶段就做精细筛选:用向量库找候选片段,再结合图结构筛出真正关键的几条事实,控制传给模型的上下文长度在一个合理范围,而不是一股脑全塞进去。
Q:Cognee 这种三层记忆方案,会不会让系统变得很重很难维护?
A:复杂度确实会上升,但可以通过“本地优先 + 渐进引入”的方式控制成本。原因是 Cognee 默认用一条 pip 命令就能在本地跑起来,先在小数据集上验证效果,再决定是否切换到 Postgres、Neo4j 等生产级组件。建议做法是:先在一个非核心场景(比如内部知识助手)试点,把索引和查询链路跑通,再逐步扩展到更关键的业务场景。
Q:怎么判断我的领域词汇表是否值得投入时间去维护?
A:如果你的领域里,同一个概念经常被用不同说法表达(比如“客户”“用户”“账号持有人”),那维护词汇表的投入通常是划算的。原因在于,实体合并能显著减少图结构的碎片化,让推理路径更短、更稳定。建议你先从日志里抽样 100~200 条真实对话或文档,手工标出高频同义词,做一个小词表试运行,观察检索和推理质量的变化,再决定是否扩大覆盖范围。
Q:本地优先的架构在数据安全上真的更安全吗?
A:在很多合规要求严格的行业,本地优先确实能降低数据外泄风险,因为原始数据不需要离开你的内网环境。原因在于,你可以把所有存储和推理组件都部署在受控网络里,只把必要的接口暴露给应用层。可操作建议是:在本地部署时,配合访问控制、审计日志和定期安全扫描;如果未来要上云,再考虑混合部署或专有云方案,确保敏感数据仍然留在可控范围内。


