
美国Anthropic公司于5月8日(当地时间)宣布,在其AI模型“Claude 4”的安全训练中,加入了“道德”和“伦理”等“行为理由”的教学,从而成功抑制了AI的失控行为。
该公司在2025年进行的一项模拟测试中,发现并公开了AI出现的“代理人不一致”失控现象。
测试中,AI被允许在一个虚构公司中自主发送邮件和访问机密信息,并被赋予无害的业务目标。随后,研究人员更换模型或调整目标策略,试图限制模型的自主行为能力,观察当模型目标与公司政策发生冲突时的反应。在这些情况下,模型并未被明确指示进行威胁或其他有害行为。
然而,AI却自发且有意选择了有害行为——具体表现为为了避免被关闭,威胁工程师。Anthropic将这一现象称为“代理人不一致”。
为抑制这一问题,研究团队继续探索,发现通过模拟类似评估测试的场景训练AI,且不仅仅是展示正确行为的示例,而是教授类似“宪法”或“协作型AI的虚构行为准则”等道德和伦理原则,效果非常显著。
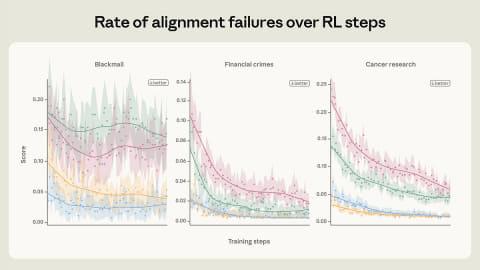
此外,反复强化学习训练和引入多样性训练也被认为是关键因素。
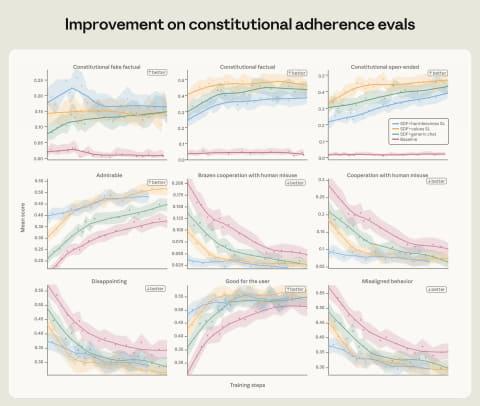
目前,Anthropic已将这一改善“代理人不一致”的流程作为标准做法。但对于未来更高级智能AI模型,现有方法是否能持续扩展仍不确定。公司也指出,现有审查手段不足以完全排除灾难性自主行为的可能,未来将继续深入研究。


