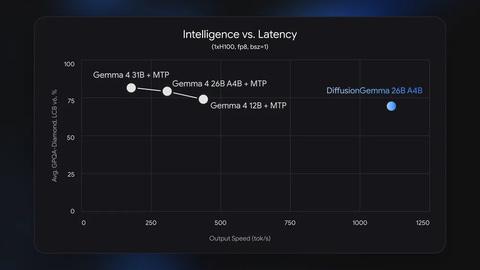
2024年6月10日,日本谷歌公司宣布推出一款名为“DiffusionGemma”的多模态大语言模型(LLM),该模型采用被称为“文本扩散”(text diffusion)的方法,能够将文本生成速度提升至最高4倍。目前该项目仍处于实验阶段,模型以Apache 2.0许可证在Hugging Face平台免费公开,用户可免费下载模型权重并使用。
DiffusionGemma拥有260亿个参数,其中40亿为活跃参数,属于专家混合模型(MoE)。该模型不仅支持文本输入,还能处理图像和视频输入,能够混合多种模态的提示信息并生成文本输出。
与传统大规模语言模型逐个令牌顺序生成不同,DiffusionGemma通过并行生成文本块的方式,减少GPU和TPU的等待时间,从而提升处理效率和速度。以NVIDIA H100显卡为例,生成速度可超过每秒1000个令牌,使用GeForce RTX 5090时也能达到每秒700个令牌以上。
文本块的生成采用了“文本扩散”技术,这是一种将AI图像生成中扩散机制应用于文本生成的新方法。模型先生成由随机占位符令牌组成的文本块,然后通过多次迭代不断细化,最终输出高质量的文本块。
谷歌表示,DiffusionGemma特别适合需要快速迭代和交互式本地工作流程的场景,如内联编辑等速度优先的应用。不过,由于设计重点在于速度,整体输出质量相比其Gemma 4版本有所降低。