日本国家谷歌公司发布了面向实时语音翻译的最新语音模型“Gemini 3.5 Live Translate”,目前已在谷歌全线产品中开始推广。
- 面向开发者:通过Gemini Live API和谷歌AI Studio提供公开预览版本
- 面向企业用户:本月起在谷歌Meet中启动私密预览
- 面向所有用户:通过Android和iOS版谷歌翻译应用提供
该模型可自动识别70多种语言,生成保持说话者语调、语速和音高的自然流畅翻译语音。不同于传统的“逐句等待”翻译方式,Gemini 3.5采用连续生成语音的策略,平衡等待上下文信息和与说话者同步的翻译质量,延迟仅几秒即可输出流畅语音。
此外,模型支持实时处理语音流,实现语言间无缝切换,无需手动设置即可处理多语言输入,且具备较强的抗噪能力,能适应嘈杂和复杂环境。
利用Gemini Live API,Agora、Fishjam、LiveKit、Pipecat、Vision Agents等开发平台能够帮助开发者轻松构建和部署语音翻译应用。
这些平台的集成简化了复杂的实时媒体流基础设施管理,使开发者能专注于提升用户体验。
日本国家Grab公司正在测试该模型,以实现乘车过程中司机与乘客之间的近实时多语言沟通。
谷歌Meet的语音翻译功能即将采用该模型,带来以下改进:
- 支持语言从原先的5种扩展至70多种
- 从仅支持英语互译,扩展到单次会议中可支持超过2000种语言组合
- 界面更新,用户可更便捷地使用语音翻译功能
本月起,谷歌将针对部分企业版谷歌Workspace用户开放私密预览,计划年底前进一步推广。
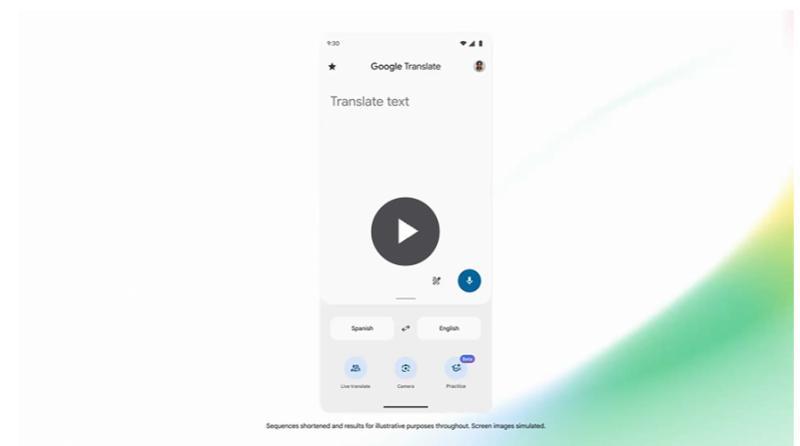
该模型也将陆续在全球范围内通过Android和iOS版谷歌翻译应用上线。使用实时翻译功能时,只需连接耳机,即可体验反映说话者语调的流畅翻译。
针对Android用户,还推出了基于该模型的新“聆听模式”,用户只需像普通通话一样将手机贴近耳朵,即可听到翻译后的语音。
值得一提的是,所有由该模型生成的语音均嵌入了SynthID电子水印,直接集成于音频输出中,有助于识别AI生成内容,防止虚假信息传播。