山洪暴发是全球最致命的气象灾害之一,每年造成超过5000人死亡。它们的预测难度极大,因为山洪发生时间短且局部性强,难以像温度或河流流量那样进行全面监测。谷歌认为,他们通过一种意想不到的方法——阅读新闻,破解了这一难题。
尽管人类积累了大量气象数据,但山洪的短暂和局部特性导致深度学习模型难以准确预测。为了解决这一问题,谷歌研究人员利用其大型语言模型Gemini,筛选了全球500万篇新闻报道,提取了260万条不同的洪水报道,并将这些信息转化为一个名为“Groundsource”的地理标记时间序列数据集。据谷歌研究产品经理Gila Loike介绍,这是谷歌首次将语言模型应用于此类工作。相关研究和数据集已于周四公开发布。
基于Groundsource这一现实世界的基准数据,研究团队训练了一个基于长短期记忆网络(LSTM)的模型,结合全球天气预报数据,生成特定区域发生山洪的概率预测。
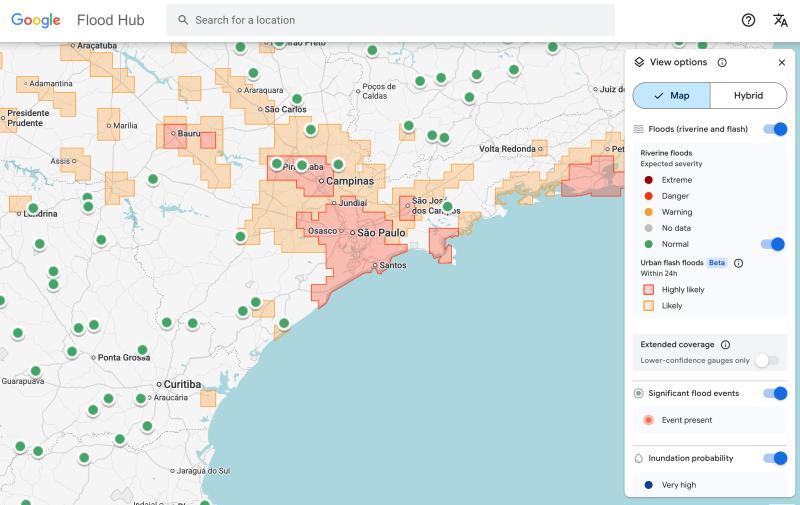
目前,谷歌的山洪预测模型已在其Flood Hub平台上为150个国家的城市区域提供风险预警,并将数据共享给全球的应急响应机构。南部非洲发展共同体的应急响应官员António José Beleza表示,该模型帮助他们更快地应对洪水灾害。
不过,该模型仍存在一些局限性。例如,其空间分辨率较低,风险识别范围为20平方公里;且预测精度不及美国国家气象局的洪水预警系统,部分原因是谷歌模型未纳入本地雷达数据,无法实现降水的实时监测。
然而,该项目的设计初衷是为那些无法负担昂贵气象监测设备或缺乏详尽气象记录的地区提供帮助。
谷歌韧性团队项目经理Juliet Rothenberg表示:“由于我们汇聚了数百万条报告,Groundsource数据集实际上帮助重新平衡了地图,能够推断出信息较少地区的情况。”
她还希望利用大型语言模型从书面定性资料中开发定量数据集的方法,能应用于其他短暂但重要的气象现象预测,如热浪和泥石流。
Upstream Tech公司CEO Marshall Moutenot表示,谷歌的工作是利用深度学习模型进行气象预测数据汇集的一个重要组成部分。该公司为水电企业等客户预测河流流量。Moutenot还是dynamical.org的联合创始人,该组织致力于为研究人员和初创企业整理机器学习适用的气象数据。
他说:“数据稀缺是地球物理学中最难解决的挑战之一。地球数据虽然庞大,但用于验证的真实数据却不足。谷歌的做法非常有创意,成功获取了宝贵的数据。”


