RAG是“检索增强生成”(Retrieval-Augmented Generation)的缩写。
你是否曾向ChatGPT或Gemini询问过贵公司的工作规章或最新产品规格,却得到不相关的回答?AI在面对未学习过或最新的信息时,可能会凭空生成看似合理但实际上错误的答案,这就是我们在第二回中提到的“幻觉”现象。
虽然AI非常便利,但直接应用于企业内部工作时存在困难。为了解决这一弱点,本文介绍的技术之一就是“RAG”。
先检索外部知识再生成回答的机制
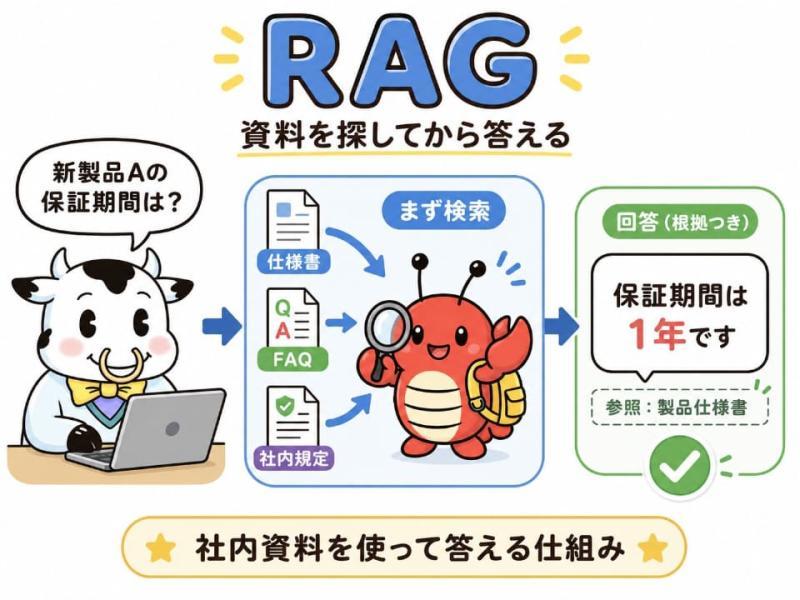
RAG的核心在于,AI在生成回答之前,会先检索外部知识库或企业内部文档,并以此作为参考来生成答案。
例如,将公司规章、产品手册、常见问题解答、会议记录、规格说明书等资料预先整理成便于AI检索的数据库。当用户询问“新产品A的保修期是多久?”时,AI不会直接生成答案,而是先搜索相关文档。
随后,将检索到的资料作为参考信息传递给大型语言模型(LLM)。LLM不仅依赖自身已有的知识,还会结合这些资料内容来生成回答。
换句话说,RAG并非让AI“全部记忆”,而是在需要时检索必要资料,并以此为依据作答。
打个比方,普通的LLM就像“闭卷考试”,无论多聪明,都无法回答教科书之外的最新信息或公司机密数据,强行回答时可能会编造虚假信息。
而RAG则像“开卷考试”,AI可以查阅手头的内部手册和文档,边看边答,从而减少幻觉现象,更准确地基于最新和专属信息作答。
Retrieval(检索)、Augmented(增强)、Generation(生成)——这就是RAG的基本理念。
与微调(Fine-tuning)的区别
在第四回中,我们提到过通过“微调”来调整AI的知识和回答风格。有人可能会认为,既然是为了添加知识,为什么不直接用微调而非RAG呢?
实际上,两者适用场景不同。微调适合调整模型的行为和专业性,但每次信息更新都需重新训练,成本和工作量较大。对于频繁变动的规章或产品规格,微调并不高效。
相比之下,RAG只需替换参考文档,便能轻松跟进最新信息。它不是重建AI模型,而是更新外部资料。
在企业内部AI或客服AI中,这种方式优势明显。与其让AI“记住所有公司信息”,不如让它“准确检索并阅读必要资料”,更符合实际运营需求。
RAG的局限性
不过,使用RAG并不保证答案一定正确。如果检索的文档过时或有误,回答自然也会出错。此外,AI有时也可能误解资料内容。
尽管如此,RAG的优势在于可以明确引用依据文档,方便人工核查。
未来企业AI的应用,不仅要关注模型本身的智能水平,更要重视“选择哪些资料、如何检索、如何利用资料生成回答”的策略。
RAG可视为将普通知识的AI转变为能处理企业专属信息的“专属助手”的基础技术。


