中国AI创业公司SentiPulse与中国人民大学的AI研究团队于4月8日(当地时间)联合发布了基于整合技术框架“SentiAvatar”的虚拟数字人“SUSU”,该技术能够让数字人在对话时展现自然流畅的动作。
在与数字人或3D虚拟形象交流时,常会感受到“嘴巴在动但表情僵硬,虽然有手势动作却与对话内容无关且不自然”,这正是数字人陷入“恐怖谷”现象的表现。该问题源于数字人动作生成通常是将通用动作拼接而成,缺乏与语义和情感的紧密结合。
然而,要实现人与数字人之间的信任建立、机器人与人类的协作,或是在游戏中更真实地表现角色,数字人必须具备自然、一致且富有情感的表现力。基于此,研究团队开发了此次的模型。

开发SentiAvatar面临三大挑战:
-
现有数据集多为英语语料,且缺少与动作同步的表情数据,尤其缺乏高质量的中文对话场景全身动作数据。
-
模型对简单动作描述如“挥手”理解良好,但对复杂动作如“无奈地耸肩”或“点头表示同意”等复合动作理解能力急剧下降。
-
生成的动作往往速度单一,且与语音的强弱和节奏完全不同步,显得机械且不自然。
这些问题的根源在于“语言意义”和“语言节奏”发生在不同时间尺度上,前者基于句子层面,后者基于帧级别,难以用单一模型同时兼顾。例如,现有的EMAGE和TalkShow等手势生成模型以语音为起点,缺乏对句子语义的深度理解;而T2M-GPT和MoMask等以文本为起点,则忽略了语音节奏的处理,未能实现时序上的精准匹配。
为解决上述问题,团队首先利用光学动作捕捉技术,针对同一角色采集了同步语音、动作注释文本、全身动作及表情等数据,构建了包含21,000个片段、37小时多模态对话的“SuSuInterActs数据集”。
随后,基于超过20万条动作序列(约676小时)对动作基础模型进行了预训练。基础模型采用Qwen-0.5B作为骨干网络,扩展了词汇表,包含2,048个动作标记和语音标记。为保持语言一致性,所有文本描述均翻译为中文。
在动作生成方面,SentiAvatar采用了“先规划再填充”的双通道并行架构,分别处理身体动作和面部表情。通过这一设计,生成的动作在自然度上显著优于其他主流AI模型。
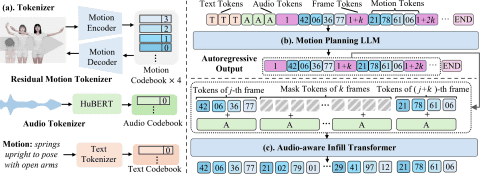
目前,SentiAvatar框架、SuSuInterActs数据集及预训练模型已在GitHub开源,面向全球对3D动作生成感兴趣的研究机构和开发者,推动3D数字人技术及其应用领域的发展。