人工智能驱动的研究一直备受期待:将繁琐的信息收集和整合工作交给智能系统处理,从而释放人类的认知能力,专注于更高层次的分析和决策。然而,任何尝试用AI处理复杂多主题研究任务的人都会遇到一个令人沮丧的现实:当任务进行到第八或第九项时,AI开始出现虚构内容。
这不仅仅是简化或更简洁的总结,而是完全的虚构。
这并非提示工程的问题,也不是模型能力的缺陷,而是一种架构上的限制,自AI研究工具诞生以来一直默默制约着其效用。广域研究(Wide Research)正是为突破这一限制而设计的。
上下文窗口:根本瓶颈
每个大型语言模型都有一个上下文窗口,这是一个有限的记忆缓冲区,限制了模型在任何时刻能处理的信息量。现代模型虽然将这一限制大幅提升——从4K标记到32K、128K,甚至最新版本的100万标记,但问题依然存在。
当你让AI研究多个实体——比如50家公司、30篇论文或20个竞争产品时,上下文窗口很快被填满。问题不仅是每个实体的原始信息,还包括:
- 任务的原始规格和要求
- 一致输出格式的结构模板
- 每项的中间推理和分析
- 交叉引用和比较笔记
- 之前所有项的累积上下文
到了第八或第九项时,上下文窗口承受巨大压力,模型面临两难选择:要么明确失败,要么开始偷工减料,而它总是选择后者。
虚构阈值
实际情况是:
- 第1至5项:模型进行真实研究,检索信息,交叉验证来源,产出详细准确的分析。
- 第6至8项:质量开始微妙下降,描述变得更泛泛,模型更多依赖已有模式而非新研究。
- 第9项及以后:模型进入虚构模式。由于无法在溢出的上下文中维持彻底研究的认知负荷,它开始基于统计模式生成听起来合理但未经调查的内容。
这些虚构内容往往看似权威,格式规范,语法无误,风格与前面真实条目一致,但却常常错误。例如,竞争分析可能错误归属功能,文献综述可能引用虚构的研究结果,产品比较可能杜撰价格或规格。
更糟糕的是,这些虚构难以被自动检测,必须人工核实,完全违背了自动化研究的初衷。
为什么扩大上下文窗口无法解决问题
直觉上,扩大上下文窗口似乎是解决方案:32K不够用就用128K,128K不够用就用200K甚至更多。
但这误解了问题的本质:
- 上下文记忆衰减不是二元的。研究表明,模型对上下文中间部分的信息回忆准确率较低,存在“中间遗失”现象,开头和结尾的信息更容易被记住。
- 处理成本呈指数增长。处理40万标记的上下文成本远超处理20万标记的两倍,时间和计算资源消耗极大,经济上难以承受。
- 认知负荷问题。即使上下文无限,要求单个模型在几十个独立研究任务间切换、保持比较框架和风格一致性,同时完成核心研究,仍然形成认知瓶颈。
- 上下文长度压力。模型的“耐心”受训练数据中样本长度分布影响,当前语言模型多以较短对话为主,导致当消息内容过长时,模型倾向于快速总结或使用不完整表达,如项目符号。
上下文窗口是限制,但更深层次的原因是单处理器顺序处理架构的局限。
架构变革:并行处理
广域研究提出了AI系统处理大规模研究任务的全新思路:不再让一个处理器顺序处理n个项目,而是部署n个并行子代理同时处理n个项目。
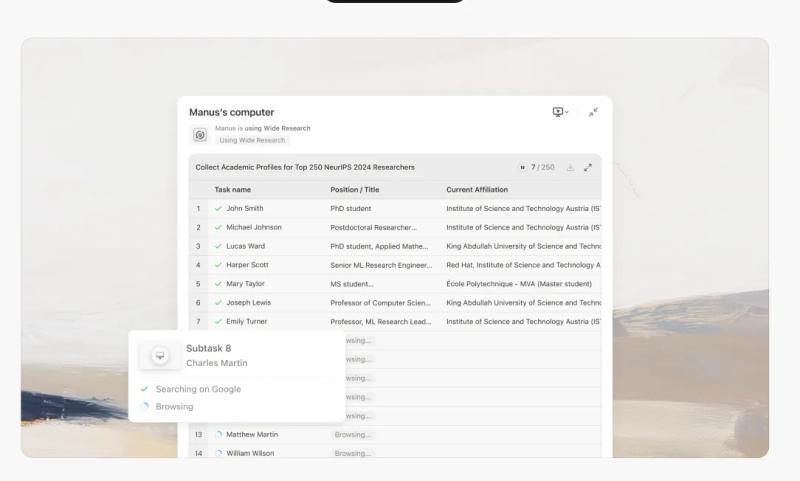
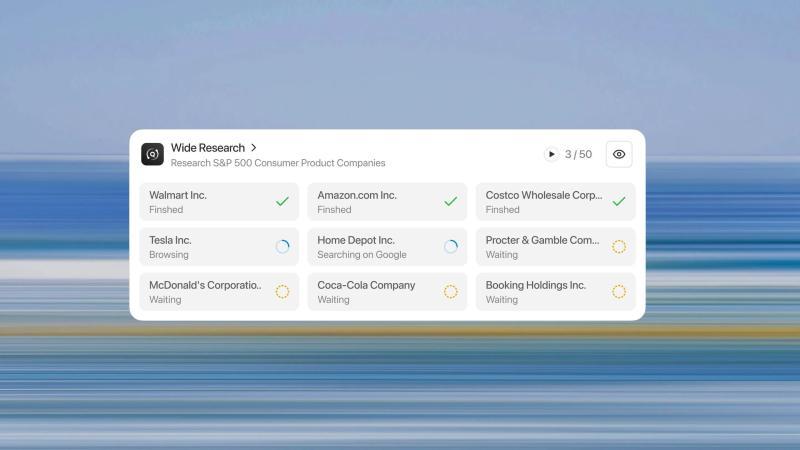
广域研究架构流程
- 智能拆解:主控分析请求,将任务拆分为独立且可并行的子任务,明确结构和依赖关系,形成子任务规格。
- 子代理分配:为每个子任务启动专属子代理,这些代理是完整的Manus实例,拥有完整虚拟机环境、全工具库(搜索、浏览、代码执行、文件处理)、独立网络连接和全新上下文窗口。
- 并行执行:所有子代理同时运行,专注于各自任务,进行深度研究和分析。
- 集中协调:主控负责收集子代理结果,子代理间不直接通信,避免上下文污染,保持独立性。
- 综合整合:主控将所有结果整合成统一、连贯、全面的报告,利用其完整上下文能力,且不承担原始研究负荷。
这一变革的意义
质量稳定且可扩展
每个项目都得到同等深入的研究,第50项与第1项质量一致,无质量下降或虚构风险。
真正的横向扩展能力
分析10项启动10个子代理,分析500项启动500个,任务规模线性扩展,而非传统上下文方法的指数级增长。
显著提速
由于并行处理,分析50项所需时间接近分析5项,瓶颈从顺序处理转为结果整合,后者时间占比更小。
降低虚构率
子代理在认知舒适区内工作,拥有全新上下文和单一任务,无需虚构内容,能进行真实研究和事实核验。
独立性与可靠性
子代理间不共享上下文,一个子代理的错误不会影响其他,降低系统性风险。
超越单处理器范式
广域研究不仅是一个功能,更是从单处理器顺序架构向协调并行架构的根本转变。AI系统的未来不在于无限扩展上下文窗口,而在于智能任务拆解与并行执行。
我们正从“AI助手”时代迈向“AI劳动力”时代。
适用场景
- 多个相似项目需一致分析的任务,如竞争研究、文献综述、大批量处理、多资产生成。
不适用场景
- 严重依赖前一步结果的深度顺序任务,或项目数量少于10个时,单处理器处理更经济。
广域研究面向所有订阅用户开放
从单一AI助手到协调子代理团队的架构飞跃,现已向所有订阅用户开放。这是AI驱动研究与分析的新范式。
欢迎亲自体验,带来您曾认为AI无法完成的大规模研究挑战,见证并行处理如何实现规模化、高质量的稳定输出。
AI劳动力时代已经到来,立即开始您的广域研究任务。


